chapter4_2
확률적 경사 하강법
1차 가장 큰 차이 (기존 ML모형)
- 샘플링 방식이 달라짐
- 샘플링을 좀 더 세분화함
2차 가장 큰 차이
- 오차를 보정 (200p~201p)
- 기울기 보정이다.
- 미분으로 기울기(경사)를 구한다.
- 기울기가 0에 가까워질 때까지 반복한다.
- 기울기 보정이다.
- 오차를 보정 (200p~201p)
경사하강법이 쓰인 여러 알고리즘
- (이미지, 텍스트) 딥러닝 기초 알고리즘
- 트리 알고리즘 + 경사하강법 융햡 = 부스팅 계열
- : 대표 알고리즘 : LightGBM, Xgboost, Catboost
- : 1등으로 자주 쓰인 알고리즘 = lightGBM, Xgboost
- : 하이퍼 파라미터의 개수가 80개 넘음
머신러닝의 목적 : 오차를 줄이는 것
- 오차 = 손실(Cost)
손실 함수(loss function)
- 손실(Cost) = 오차
SGDClassifier
- 확률적 경사하강법 분류기
1 | import pandas as pd |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 159 entries, 0 to 158
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Species 159 non-null object
1 Weight 159 non-null float64
2 Length 159 non-null float64
3 Diagonal 159 non-null float64
4 Height 159 non-null float64
5 Width 159 non-null float64
dtypes: float64(5), object(1)
memory usage: 7.6+ KB
- 배열로 변환하는 코드
- 독립변수 = fish_input
- 종속변수 = fish_target
1 | fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']] # Diagonal = 대각선 |
- 훈련 데이터와 테스트 데이터
- 이제 데이터를 훈련 세트와 테스트 세트로 나눈다.
- 외워야 할 정도로 중요. 자주 쓰다보면 외워진다.
1 | from sklearn.model_selection import train_test_split |
((119, 5), (40, 5), (119,), (40,))
- 표준화 처리
- 다시 한 번 강조하지만 꼭 훈련 세트에서 학습한 통계값으로 테스트 세트도 변환한다.
- 키워드 : Data Leakage 방지
- 데이터 분석 희망자! 필수 공부!
1 | from sklearn.preprocessing import StandardScaler |
모델 학습
- 2개의 매개 변수 지정
- loss = “log” = 로지스틱 손실 함수로 지정
- max_iter = 에포크 횟수 지정
1 | from sklearn.linear_model import SGDClassifier |
0.8571428571428571
0.8
- 에포크
- 최적의 기울기를 찾아야 한다.
- 적절한 에포크 숫자를 찾자
1 | import numpy as np |
[0.5294117647058824, 0.6218487394957983, 0.6386554621848739, 0.7310924369747899, 0.7226890756302521]
[0.65, 0.55, 0.575, 0.7, 0.7]
- 모형 학습 시각화
1 | import matplotlib.pyplot as plt |
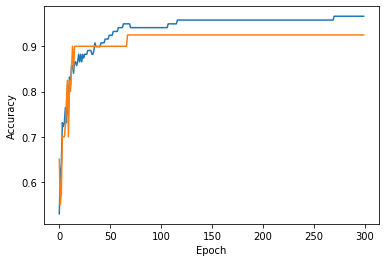
위 결과 25쯤에서 과소적합.
위 결과 125쯤에서 과대적합.
이 모델의 경우 100번째 Epoch가 적절한 반복 횟수로 보인다.
그럼 SGDClassifier의 반복 횟루를 100에 맞추고 모델을 다시 훈련한다.
그리고 최종적으로 훈련 세트와 테스트 세트에서 점수를 출련한다.
1 | sc = SGDClassifier(loss = 'log', max_iter=100, tol=None, random_state=42) |
0.957983193277311
0.925
SGDClassifier는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다.
tol 매개변수에서 향상될 최솟값을 지정한다.
앞의 코드에서는 tol매개변수를 None으로 지정하여 자동으로 멈추지 않고 max_iter=100 만큼 무조건 반복하도록 했다.
결과적으로 점수가 높게 나왔다.
확률적 경사 하강법을 사용한 생선 분류 문제를 성공적으로 수행했다.
loss 매개변수
- SGDClassifier의 매개변수이다.
- loss 매개변수의 기본값은 ‘hinge’이다.
- ‘힌지 손실’은 ‘서포트 벡터 머신’ 이라 불리는 또 다른 머신러닝 알고리즘을 위한 손실 함수이다.
- 한 마디로 loss 매개변수는 여러 알고리즘에서 쓰이는 매개변수이다.
loss 매개변수와 힌지 손실 예시
- 간단한 예로 힌지 손실을 사용해 같은 반복 횟수 동안 모델을 훈련해보자.
1 | sc = SGDClassifier(loss='hinge', max_iter=100, tol=None, random_state=42) |
0.9495798319327731
0.925
전체 소스 코드
1 | # 확률적 경사 하강법 |
0.8571428571428571
0.8
0.957983193277311
0.925
0.9411764705882353
0.925
[0.5294117647058824, 0.6218487394957983, 0.6386554621848739, 0.7310924369747899, 0.7226890756302521]
[0.65, 0.55, 0.575, 0.7, 0.7]
0.957983193277311
0.925
0.9495798319327731
0.925
- Reference : 혼자 공부하는 머신러닝 + 딥러닝
You need to set
install_url to use ShareThis. Please set it in _config.yml.