chapter_6_1
비지도 학습
- vs 지도 학습
- 종속 변수가 있다 = 타겟이 있다
- 비지도 학습은 종속변수 및 타겟이 없다.
- 분류
- 다중분류
- 전제조건 : (다양한 유형) 데이터가 많아야 함
- 딥러닝과 연관이 됨(자연어 처리, 이미지)
데이터 불러오기
- 과일가게 문제 : 많은 과일 사진을 각 과일 별로 분류해야 한다.
- 다음을 참고하라 : http://bit.ly/hg-06-1
1 | !wget https://bit.ly/fruits_300_data -O fruits_300.npy |
--2022-03-31 03:09:03-- https://bit.ly/fruits_300_data
Resolving bit.ly (bit.ly)... 67.199.248.11, 67.199.248.10
Connecting to bit.ly (bit.ly)|67.199.248.11|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: https://github.com/rickiepark/hg-mldl/raw/master/fruits_300.npy [following]
--2022-03-31 03:09:03-- https://github.com/rickiepark/hg-mldl/raw/master/fruits_300.npy
Resolving github.com (github.com)... 140.82.121.4
Connecting to github.com (github.com)|140.82.121.4|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://raw.githubusercontent.com/rickiepark/hg-mldl/master/fruits_300.npy [following]
--2022-03-31 03:09:03-- https://raw.githubusercontent.com/rickiepark/hg-mldl/master/fruits_300.npy
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.108.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3000128 (2.9M) [application/octet-stream]
Saving to: ‘fruits_300.npy’
fruits_300.npy 100%[===================>] 2.86M --.-KB/s in 0.03s
2022-03-31 03:09:03 (107 MB/s) - ‘fruits_300.npy’ saved [3000128/3000128]
- numpy 파일을 불러옴
1 | import numpy as np |
(300, 100, 100)
3
- 첫 번째 차원(300) = 샘플의 개수
- 두 번째 차원(100) = 이미지 높이
- 세 번째 차원(100) = 이미지 너비
- 이미지 크기 100 x 100
1 | # 첫 번째 행에 있는 픽셀 100개에 들어있는 값을 출력 |
array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 1,
1, 1, 1, 1, 1, 1, 2, 3, 2, 1, 2, 1, 1,
1, 1, 2, 1, 3, 2, 1, 3, 1, 4, 1, 2, 5,
5, 5, 19, 148, 192, 117, 28, 1, 1, 2, 1, 4, 1,
1, 3, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=uint8)
- 이미지 시각화
- 흑백 사진을 담고 있다.
- 0~255까지의 정숫값을 가진다.
1 | plt.imshow(fruits[0], cmap='gray') # cmap 은 옵션 |

1 | plt.imshow(fruits[0], cmap='gray_r') # cmap 은 옵션 |

- 여러 이미지 시각화
1 | fig, axs = plt.subplots(1, 2) |
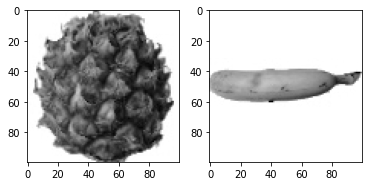
픽셀값 분석
1 | apple = fruits[0:100].reshape(-1, 100 * 100) # 두 번째와 세 번째 차원 크기가 100이므로. |
(100, 10000)
(100, 10000)
(100, 10000)
axis = 0 vs axis = 1 차이 확인 (p.293)
각 이미지에 대한 픽셀 평균값 비교
1 | # axis = 1 = 열 |
[ 88.3346 97.9249 87.3709 98.3703 92.8705 82.6439 94.4244 95.5999
90.681 81.6226 87.0578 95.0745 93.8416 87.017 97.5078 87.2019
88.9827 100.9158 92.7823 100.9184 104.9854 88.674 99.5643 97.2495
94.1179 92.1935 95.1671 93.3322 102.8967 94.6695 90.5285 89.0744
97.7641 97.2938 100.7564 90.5236 100.2542 85.8452 96.4615 97.1492
90.711 102.3193 87.1629 89.8751 86.7327 86.3991 95.2865 89.1709
96.8163 91.6604 96.1065 99.6829 94.9718 87.4812 89.2596 89.5268
93.799 97.3983 87.151 97.825 103.22 94.4239 83.6657 83.5159
102.8453 87.0379 91.2742 100.4848 93.8388 90.8568 97.4616 97.5022
82.446 87.1789 96.9206 90.3135 90.565 97.6538 98.0919 93.6252
87.3867 84.7073 89.1135 86.7646 88.7301 86.643 96.7323 97.2604
81.9424 87.1687 97.2066 83.4712 95.9781 91.8096 98.4086 100.7823
101.556 100.7027 91.6098 88.8976]
- 각 과일에 대한 히스토그램 작성
- 히스토그램은 값이 발생하는 빈도를 그래프로 표시한 것.
- 보통 x축은 값의 구간이고, y축은 발생 빈도이다.
1 | plt.hist(np.mean(apple, axis = 1), alpha = 0.8) # alpha 는 투명도 조절하는 매개변수 |
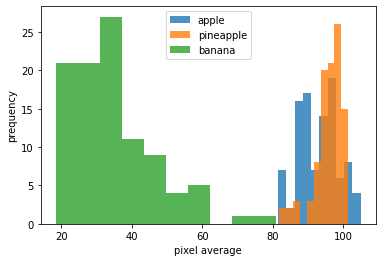
위 결과에서 banana는 픽셀 평균값이 다른 두 과일과 확연히 다르다.
- banana는 픽셀 평균값으로 구분하기 쉽다.
이번에는 샘플의 평균값이 아니라 픽셀별 평균값을 비교해 본다.
즉, 전체 샘플에 대해 각 픽셀의 평균을 조사한다.
axis=0으로 지정하여 픽셀의 평균을 계산하면 된다.
1 | fig, axs = plt.subplots(1, 3, figsize=(20, 5)) |
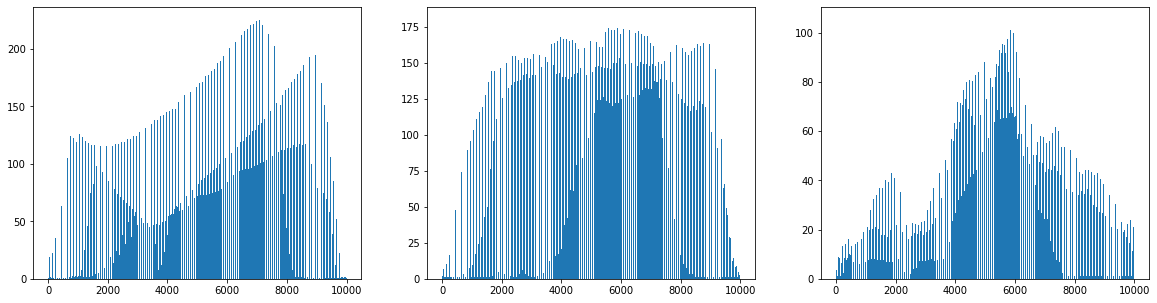
- 대표 이미지
1 | apple_mean = np.mean(apple, axis=0).reshape(100, 100) |

평균값과 가까운 사진 고르기
1 | abs_diff = np.abs(fruits - apple_mean) |
(300,)
- 오차의 값이 가장 작은 순서대로 100개를 골라본다.
1 | apple_index = np.argsort(abs_mean)[:100] |

1 | apple_index = np.argsort(abs_mean)[:100] |

- Reference : 혼자 공부하는 머신러닝 + 딥러닝
You need to set
install_url to use ShareThis. Please set it in _config.yml.