k-평균
데이터 불러오기 다음을 참고하라 : http://bit.ly/hg-06-2
1 !wget https://bit.ly/fruits_300_data -O fruits_300.npy
--2022-03-31 02:17:17-- https://bit.ly/fruits_300_data
Resolving bit.ly (bit.ly)... 67.199.248.11, 67.199.248.10
Connecting to bit.ly (bit.ly)|67.199.248.11|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: https://github.com/rickiepark/hg-mldl/raw/master/fruits_300.npy [following]
--2022-03-31 02:17:17-- https://github.com/rickiepark/hg-mldl/raw/master/fruits_300.npy
Resolving github.com (github.com)... 192.30.255.112
Connecting to github.com (github.com)|192.30.255.112|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://raw.githubusercontent.com/rickiepark/hg-mldl/master/fruits_300.npy [following]
--2022-03-31 02:17:17-- https://raw.githubusercontent.com/rickiepark/hg-mldl/master/fruits_300.npy
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.109.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3000128 (2.9M) [application/octet-stream]
Saving to: ‘fruits_300.npy’
fruits_300.npy 100%[===================>] 2.86M --.-KB/s in 0.05s
2022-03-31 02:17:17 (56.9 MB/s) - ‘fruits_300.npy’ saved [3000128/3000128]
1 2 3 4 5 6 import numpy as npimport matplotlib.pyplot as pltfruits = np.load('fruits_300.npy' ) print (fruits.shape)print (fruits.ndim)
(300, 100, 100)
3
3차원 (샘플개수, 너비, 높이)
2차원 (샘플개수, 너비 x 높이)
1 2 fruits_2d = fruits.reshape(-1 , 100 *100 ) fruits_2d.shape
(300, 10000)
1 2 3 from sklearn.cluster import KMeanskm = KMeans(n_clusters=3 , random_state = 42 ) km.fit(fruits_2d)
KMeans(n_clusters=3, random_state=42)
[2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 0 2 0 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 0 0 2 2 2 2 2 2 2 2 0 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1]
1 print (np.unique(km.labels_, return_counts=True ))
(array([0, 1, 2], dtype=int32), array([111, 98, 91]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import matplotlib.pyplot as pltdef draw_fruits (arr, ratio=1 ): n = len (arr) rows = int (np.ceil(n/10 )) cols = n if rows < 2 else 10 fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False ) for i in range (rows): for j in range (cols): if i*10 + j < n: axs[i, j].imshow(arr[i*10 + j], cmap='gray_r' ) axs[i, j].axis('off' ) plt.show()
1 draw_fruits(fruits[km.labels_==0 ])
클러스터 중심 1 draw_fruits(km.cluster_centers_.reshape(-1 , 100 , 100 ), ratio=3 )
1 print (km.transform(fruits_2d[100 :101 ]))
[[3393.8136117 8837.37750892 5267.70439881]]
1 print (km.predict(fruits_2d[100 :101 ]))
[0]
1 draw_fruits(fruits[100 :101 ])
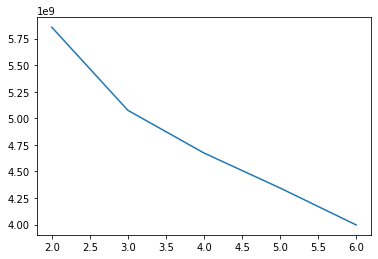
최적의 k-평균 찾기 1 2 3 4 5 6 7 inertia = [] for k in range (2 , 7 ): km = KMeans(n_clusters = k, random_state=42 ) km.fit(fruits_2d) inertia.append(km.inertia_) plt.plot(range (2 , 7 ), inertia) plt.show()
위 결과 최적의 k-평균은 3.0 정도 된다.
chapter6. 비지도학습은 잘 안 쓰인다. 시각화 문법만 유의해서 살펴보자.
Reference : 혼자 공부하는 머신러닝 + 딥러닝