사전준비
- spark on windows 참고하여 세팅
- 스파크를 설치한다.
- 만약, 파이썬이 처음이라면 **Anaconda**를 설치한다.
pyspark 설치
- git bash를 이용해 폴더를 생성하고 터미널을 연다.
바탕화면 우클릭 : git bash here
→ mkdir pyspk_project
→ cd pyspk_project
→ code .
→ git bash 터미널
→ virtualenv venv
→ source venv/Scripts/activate
→ pip install pyspark
pyspark 실습_1
→ 폴더 생성 : chapter01_get_started
→ 파일 생성 : step01_basic.py
→ 코드 작성
import pyspark
print(pyspark.__version__)
→ 저장
→ 경로 이동 : cd chapter01_get_started
→ 실행 : python step01_basic.py
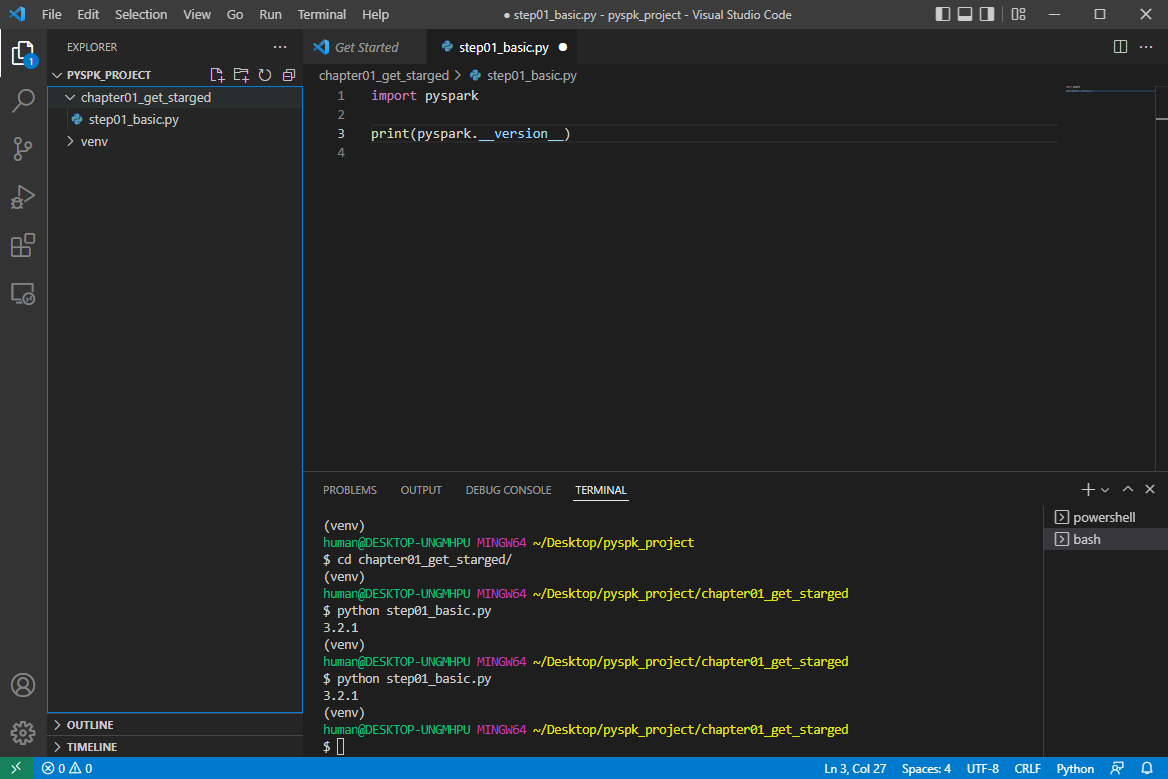
→ step01_basic.py를 다음과 같이 작성
1
2
3
4
5
6
7
8
9
10
11
12
| # -*- coding: utf-8 -*-
import pyspark
print(pyspark.__version__)
from pyspark.sql import SparkSession
# 스파크 세션 초기화
spark = SparkSession.builder.master('local[1]').appName('SampleTutorial').getOrCreate()
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])
print("rdd Count:", rdd.count())
|
→ 저장 후 실행
→ 주소창에 입력 : http://localhost:4040/
→ 다음 화면이 출력된다.
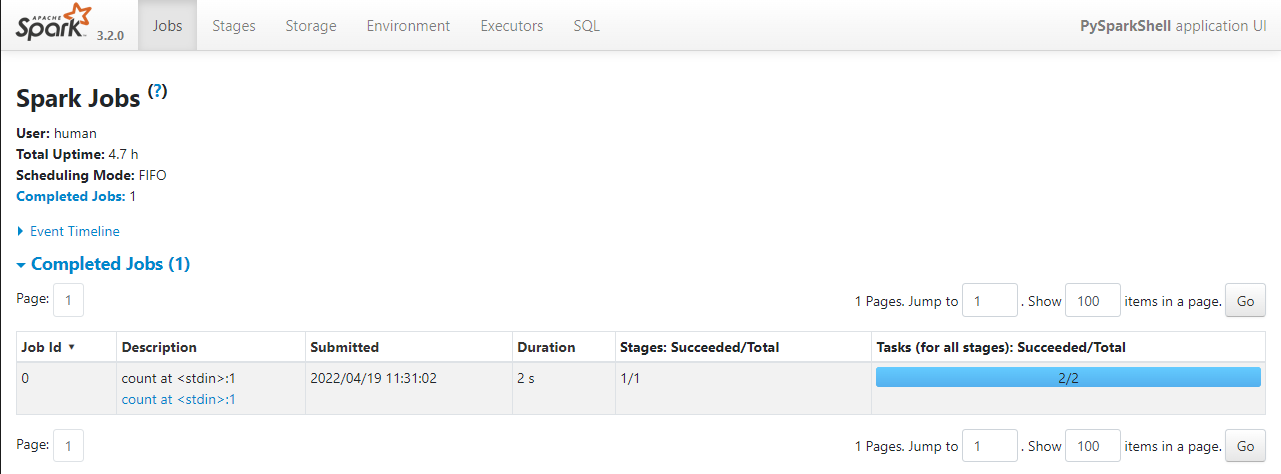
pyspark 실습_2
- 슬랙에서 dataset.zip 을 다운로드
- 압축을 풀고 chapter01_get_started 파일에 복사하여 옮긴다.
→ 파일 생성 : step02_ratings.py
→ 코드 작성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| # SparkContext
# RDD
from pyspark import SparkConf, SparkContext
import collections
print("Hello")
def main():
# MasterNode = local
# MapReduce
conf = SparkConf().setMaster('local').setAppName('RatingsHistogram')
sc = SparkContext(conf = conf)
lines = sc.textFile("ml-100k/u.logs")
ratings = lines.map(lambda x: x.split()[2])
print("ratings: ", ratings)
result = ratings.countByValue()
print("result:", result)
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print("%s %i" % (key, value))
if __name__ == "__main__":
main()
|
→ 저장
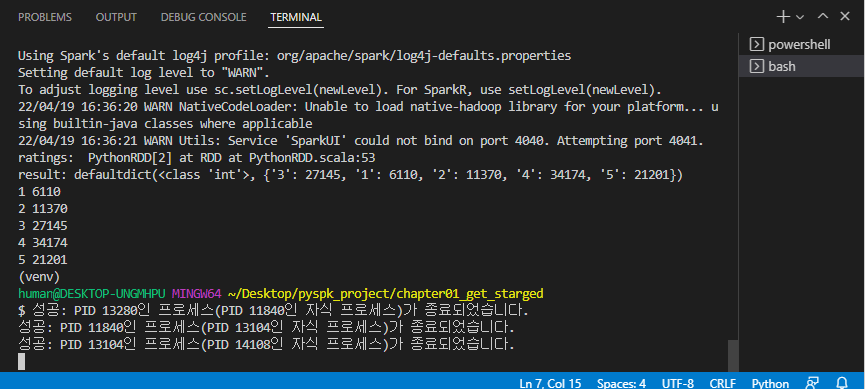
→ 실행 : python step02_ratings.py
→ 다음 결과가 출력된다.
→ 파일 생성 : step03_dataloading.py
→ 코드 작성
→ pip install pandas
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| # Spark SQL 적용
# Spark Session
from pyspark.sql import SparkSession
import pandas as pd
# 스파크 세션 생성
"""
my_spark = SparkSession.builder.getOrCreate()
print(my_spark)
# 테이블을 확인하는 코드
print(my_spark.catalog.listDatabases())
# show database
my_spark.sql('show databases').show()
# 현재 DB 확인
my_spark.catalog.currentDatabase()
my_spark.stop()
"""
# CSV 파일 불러오기
spark = SparkSession.builder.master('local[1]').appName('DBTutorial').getOrCreate()
flights = spark.read.option('header', 'true').csv('data/flight_small.csv')
# flights.show(4)
# spark.catalog.currentDatabase()
# flights 테이블을 default DB에 추가함
flights.createOrReplaceTempView('flights')
# print(spark.catalog.listTables('default'))
# spark.sql('show tables from default').show()
# 쿼리 통해서 데이터 저장
query = "FROM Fligths SELECT * LIMIT 10"
query2 = "SELECT * FROM flights 10"
# 스파크에 세션할당
flights10 = spark.sql(query2)
flights10.show()
# Spark 데이터 프레임을 Pandas 데이터 프레임을 변환
pd_flights10 = flights10.toPandas()
print(pd_flights10.head())
|
→ 저장
→ 실행 : python step03_dataloading.py