사전준비
git bash로 VSCord에 들어가 터미널을 연다.
바탕화면 우클릭 : git bash here
→ cd pyspk_project
→ code .
→ git bash 터미널
pyspark 실습(1)
→ source venv/Scripts/activate
→ chapter01_get_starged 폴더에서 파일 생성
→ 파일 생성 : step04_structype.py
키워드 : Struct Type
구글링 : Spark Struct Type, Spark Struct
참고 링크 :
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.types.StructType.html
→ 코드 작성
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from struct import Structfrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as func from pyspark.sql.types import StructType, StructField, IntegerType, LongTypespark = SparkSession.builder.appName("PopularMovies" ).getOrCreate() schema = StructType( [ StructField("userID" , IntegerType(), True ), StructField("movieID" , IntegerType(), True ), StructField("rating" , IntegerType(), True ), StructField("timestamp" , LongType(), True ) ] ) print ("Schema is done" )movies_df = spark.read.option("sep" , "\t" ).schema(schema).csv("ml-100k/u.logs" ) toMovieIds = movies_df.groupBy("movieID" ).count().orderBy(func.desc('count' )) print (movies_df.show(10 ))spark.stop()
→ 경로 이동 : cd chapter01_get_started
→ 저장 후 실행
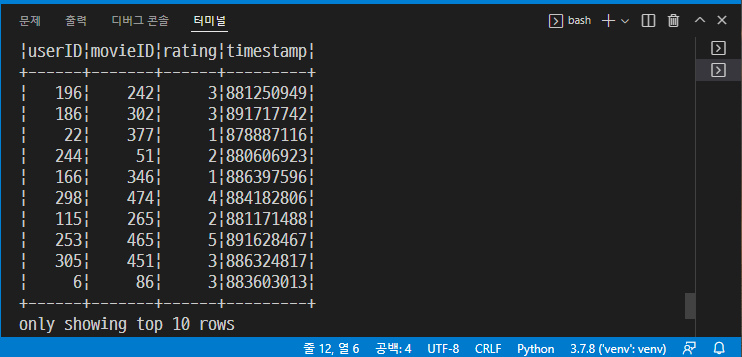
→ python step04_structype.py
→ 다음 테이블이 출력되어야 한다.
pyspark 실습(2)
→ chapter01_get_starged 폴더에서 파일 생성
→ 파일 생성 : step05_advancestructype.py
→ 코드 작성
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as funcfrom pyspark.sql.types import StructType, StructField, IntegerType, LongTypeimport codecsprint ("Hello" )def loadMovieNames (): movieNames = {} with codecs.open ("ml-100k/u.ITEM" , "r" , encoding="ISO-8859-1" , errors="ignore" ) as f: for line in f: fields = line.split("|" ) movieNames[int (fields[0 ])] = fields[1 ] return movieNames spark = SparkSession.builder.appName("PopularMovies" ).getOrCreate() nameDict = spark.sparkContext.broadcast(loadMovieNames()) schema = StructType( [ StructField("userID" , IntegerType(), True ) , StructField("movieID" , IntegerType(), True ) , StructField("rating" , IntegerType(), True ) , StructField("timestamp" , LongType(), True ) ] ) print ("Schema is done" )movies_df = spark.read.option("sep" , "\t" ).schema(schema).csv("ml-100k/u.logs" ) topMovieIds = movies_df.groupBy("movieID" ).count() def lookupName (movieID ): return nameDict.value[movieID] lookupNameUDF = func.udf(lookupName) moviesWithNames = topMovieIds.withColumn("movieTitle" , lookupNameUDF(func.col("movieID" ))) final_df = moviesWithNames.orderBy(func.desc("count" )) print (final_df.show(10 ))spark.stop()
→ 저장 후 실행
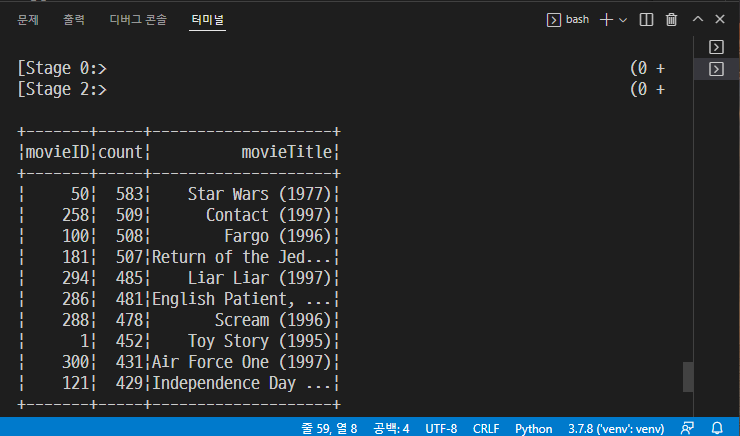
→ python step05_advancestructype.py
→ 다음과 같이 출력된다.