Spark ML
- Spark로 머신러닝을 사용해 본다.
- 실용성과 별개로 경험삼아 작성해보는 코드이다.
- 머신러닝(ML)은 Scikit-Learn을 중점적으로 공부해야 한다.
- 딥러닝(DL)은 Tensorflow, Pytorch에 포커스를 맞춰야 한다.
사전준비
- git bash로 VSCord에 들어가 터밀널을 연다.
바탕화면 우클릭 : git bash here
→ cd pyspk_project
→ code .
→ git bash 터미널
pyspark_ml 실습(1)
- 가상환경 진입하고 폴더, 파일 생성
→ source venv/Scripts/activate
→ 폴더 생성 : chapter03_ml
→ cd chapter03_ml
- 슬랙에서 data.zip 을 다운로드
- 압축을 풀고 chapter03_ml 폴더에 복사하여 옮긴다.
→ 파일 생성 : step01_regression.py
→ 코드 작성
1 | from pyspark.ml.regression import DecisionTreeRegressor |
→ 저장 후 실행
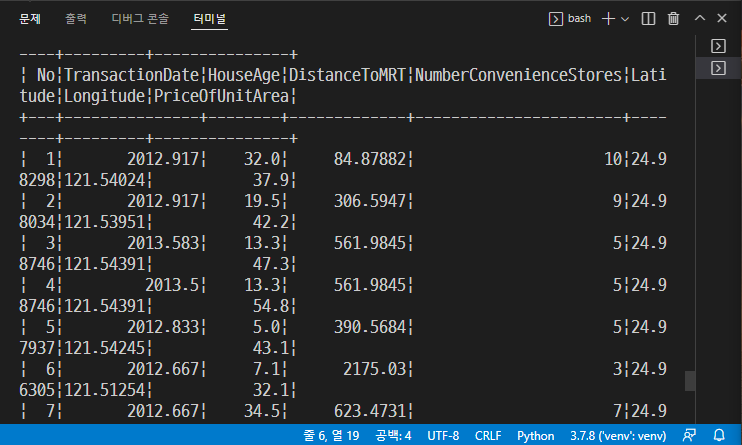
→ python step01_regression.py
→ 다음과 같이 출력된다.
pyspark_ml 실습(2)
→ 파일 생성 : step02_logistic_regression.py
→ 코드 작성
1 | # 세션 할당 |
→ 저장 후 실행
→ python step02_logistic_regression.py
pyspark_ml 실습(3)
- pyspark_pipeline
→ 파일 생성 : step03_pipeline.py
→ 코드 작성
1 | from tokenize import Token |
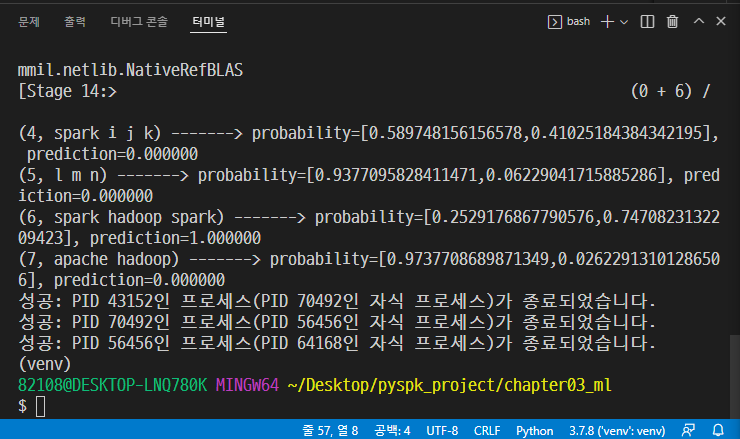
→ 저장 후 실행
→ python step03_pipeline.py
pyspark_ml 실습(3)
→ 파일 생성 : step03_randomforest.py
→ 코드 작성
1 | from cProfile import label |
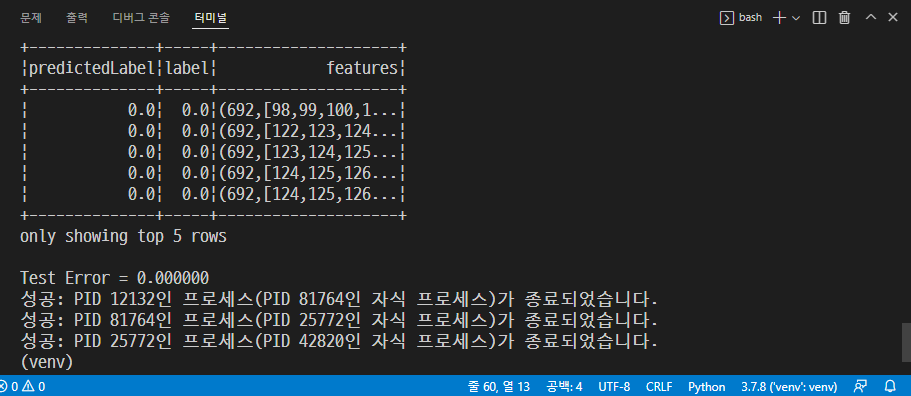
→ 저장 후 실행
→ python step04_randomforest.py
팁
venv 생성되어 있는 경로로 이동
→ pip install jupyterlab
→ jupyter lab
→ 주피터랩에서 블로그에 올릴 자료 작성 가능.
You need to set
install_url to use ShareThis. Please set it in _config.yml.