Crawling_practice
- 웹 크롤링을 시도해본다.
- 우선 Pycharm 환경에서 가상환경을 생성해야 한다.
바탕화면에 crawling 폴더 생성
→ 우클릭하여 pycharm으로 열기
→ File → Settings
→ Project : crawling → python interpreter
→ 톱니모양 → add
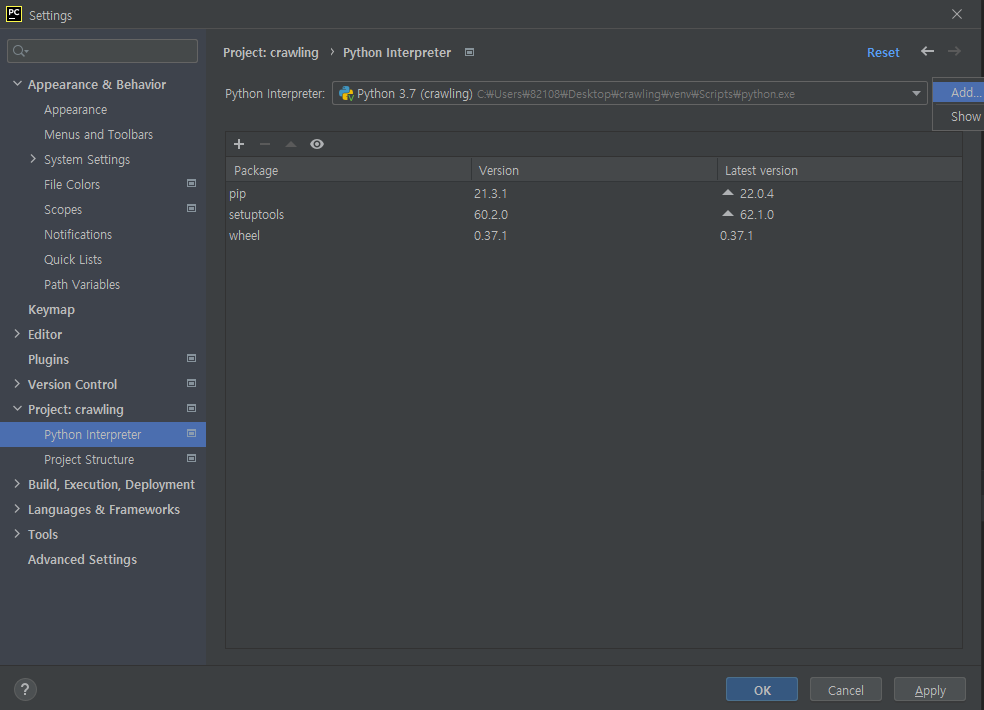
- 필요한 패키지들을 설치한다.
→ git bash 터미널
→pip install beautifulsoup4
→pip install numpy pandas matplotlib seaborn
→pip install requests
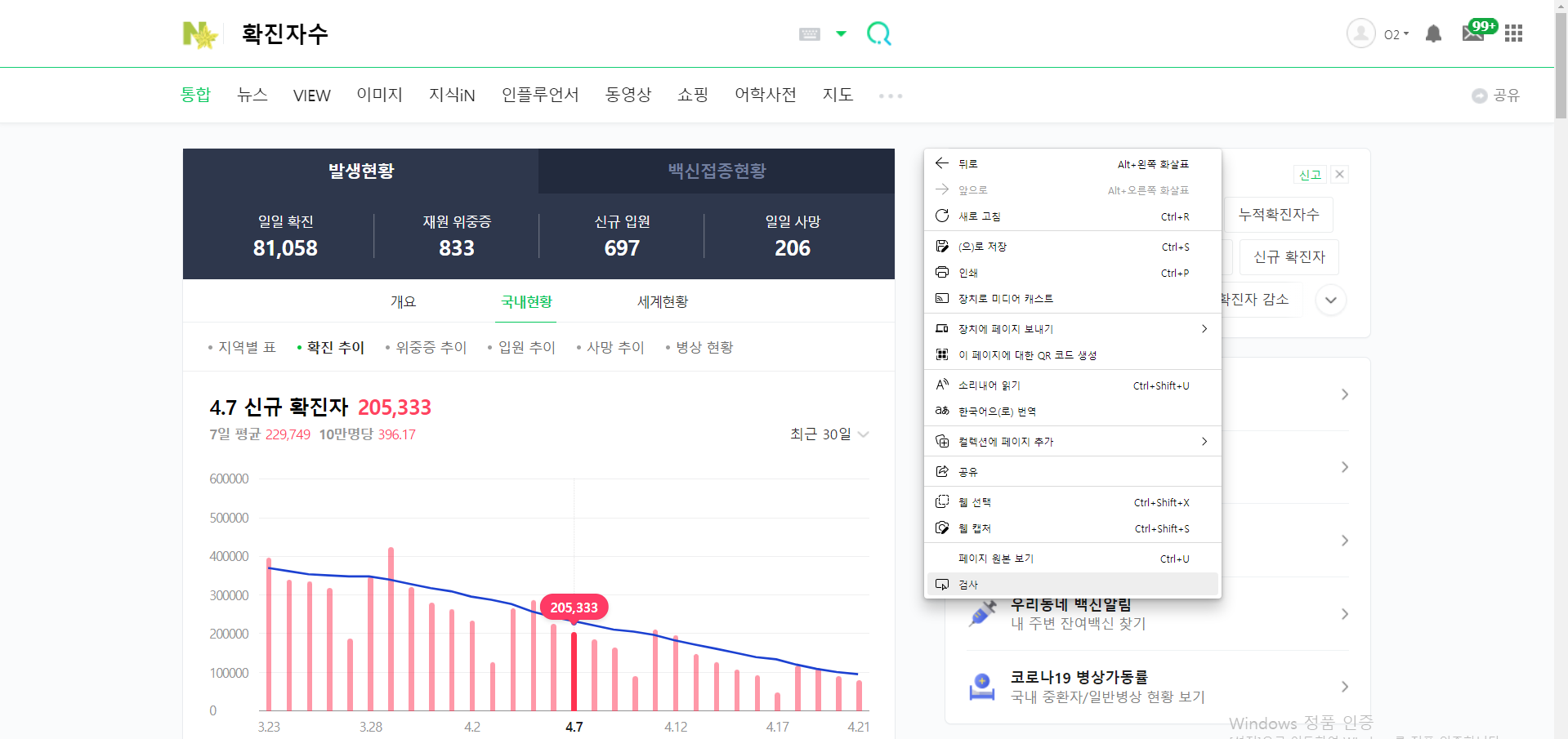
- 브라우저에서 검색을 진행
→ 검색 : 확진자수
→ 우클릭 → 검사
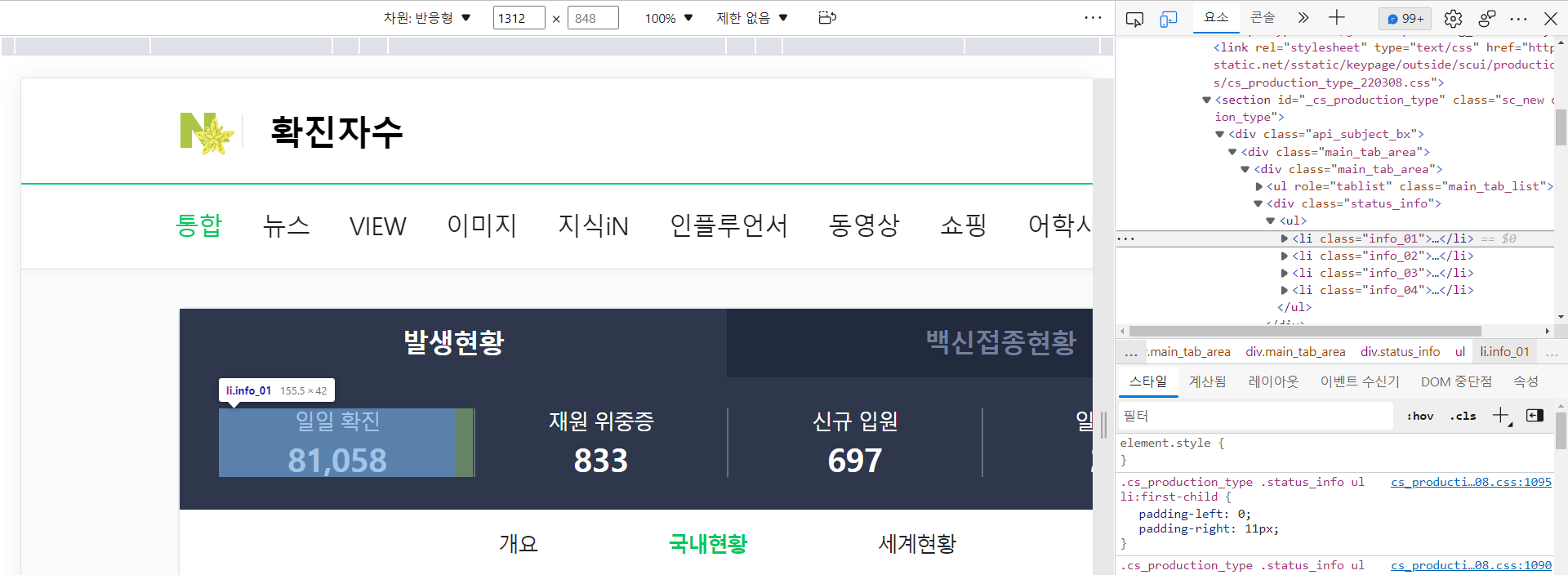
- 원하는 정보가 포함된 코드를 선택 가능
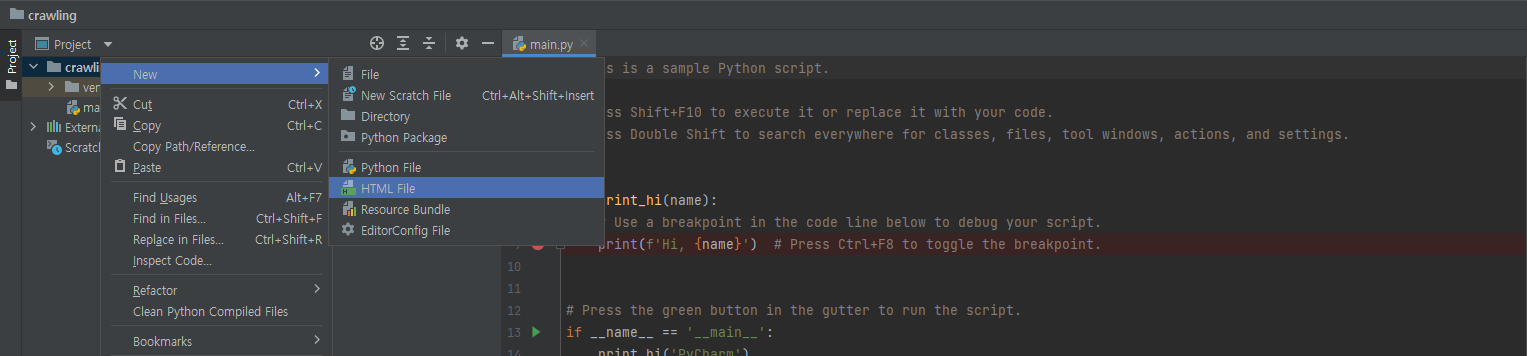
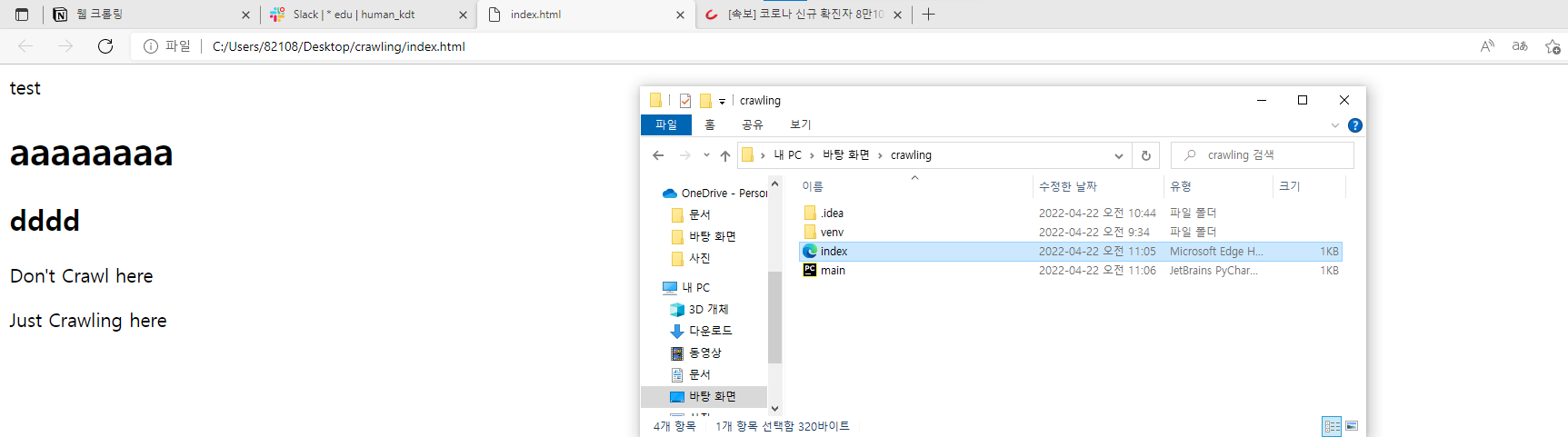
- index.html을 생성한다.
crawling 폴더 우클릭 → New → HTML.file
- 다음과 같이 입력하고 index 파일을 열어본다.
1 | <!DOCTYPE html> |
- index 파일을 열면 index.html에 작성한 대로 출력된다.
- 이번에는 다른 파일에 코드를 작성해보자.
- 일단 main.py에 작성한다.
1 | from bs4 import BeautifulSoup |
- Index.html에서 크롤링하여 다음과 같이 출력된다.
→ python main.py

팁
- 정렬 : ctrl + alt + l
Python
웹상에 있는 데이터를 숩집하는 도구
- BeautifulSoup 가장 일반적인 수집 도구 (CSS 통해서 수집)
- Scrapy (CSS, XAPTH 통해서 데이터 수집 + JavaScript)
- Selenium (CSS, XPATH 통해서 데이터 수집 + JAVAScript)
—> 자바 필요 + 여러가지 설치 도구 필요
웹 사이트 만드는 3대 조건 + 1
- HTML, CSS, JavaScript, Ajax (비동기처리)
웹 사이트 구동 방식
GET / POST
Reference
Crawling_practice
You need to set
install_url to use ShareThis. Please set it in _config.yml.