Crawling start for chatbot data
크롤링 기초
- 크롤링한 데이터를 카카오 스킬을 통해 챗봇에 출력하도록 할 것이다
- 우선 크롤링 기초를 연습하고 시작할 예정
사이트 정보 가져오기 - requests 사용법
1. requests 모듈 설치
- VSCord에서 실행. 가상환경 진입 후 진행.
1 | pip install requests |
2. URL 요청하기 -get
- status_code 는 응답코드를 가져온다.
- text에는 HTML 코드가 담겨 있다.
1 | import requests |
- status_code 의 응답코드는 200이 출력된다.
- text의 HTML 코드는 다음과 같이 출력된다.
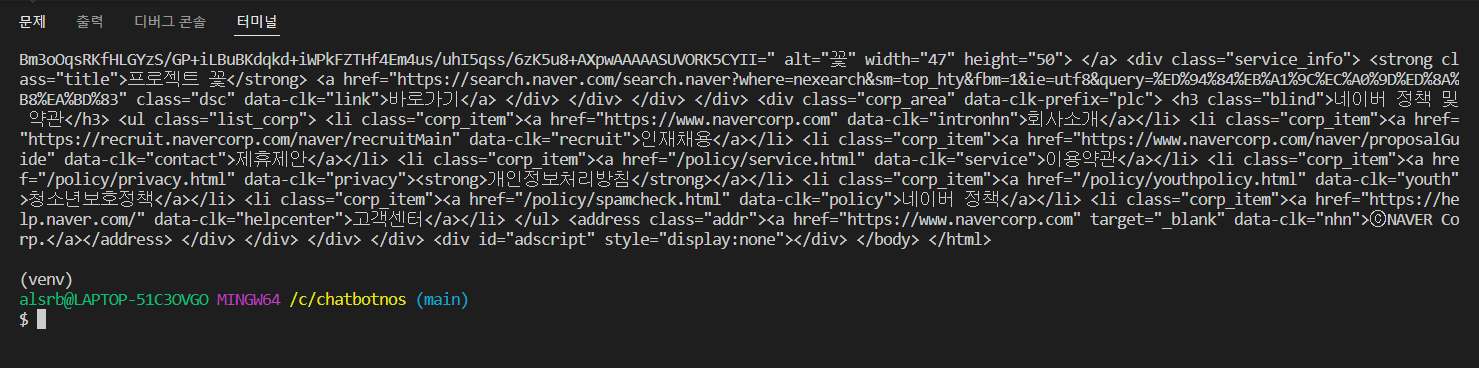
사이트 정보 추출하기 - beaurifulsoup 사용법
0. BeautifulSoup가 필요한 이유
- request.text를 이용해 가져온 데이터는 텍스트형태의 html.
- 텍스트형태의 데이터에서 원하는 html 태그를 추출할 수 있을까?
- 이를 쉽게 할 수 있게 도와주는 녀석이 바로 “뷰티풀수프”.
- 즉, html을 수프객체로 만들어서 추출하기 쉽게 만들어준다.
1. beautifulsoup 설치
1 | pip install beautifulsoup4 |
2.beautifulsoup 사용법
- 정보를 추출할 사이트의 url 참고
- 응답 코드가 200 일때, html 을 받아와 soup 객체로 변환
1 | import requests |
웹 크롤링 예제
- 추출할 정보를 우클릭 → 검사
- 다음과 같이 선택한 정보의 html이 표시된다
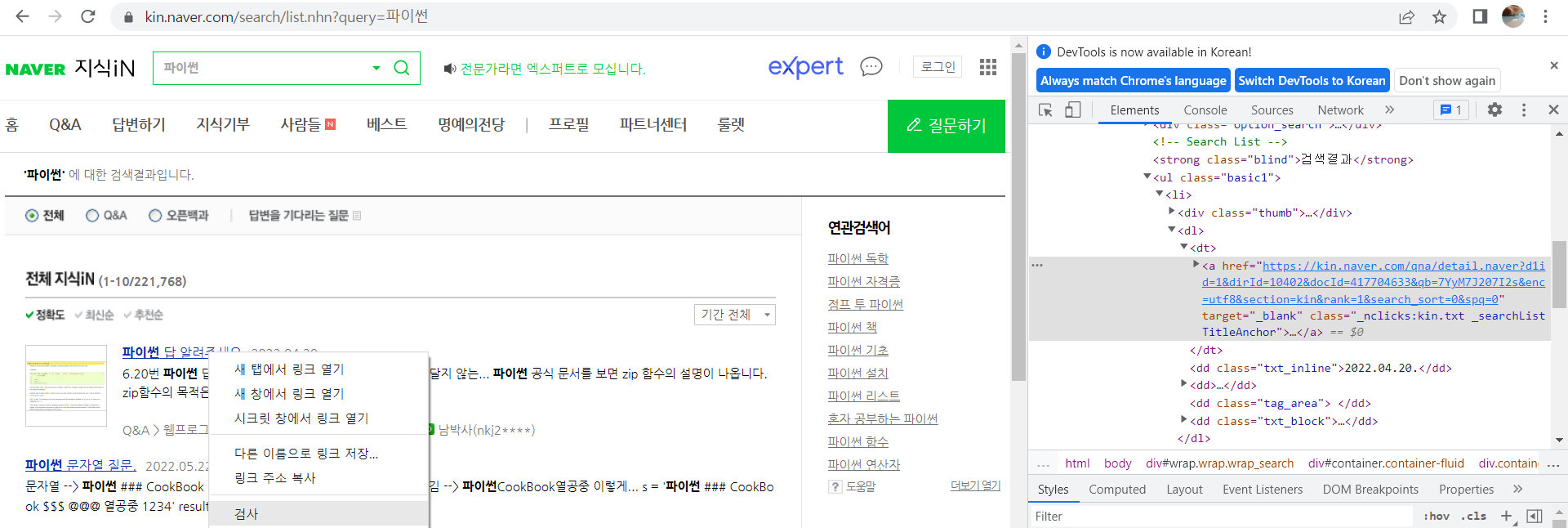
- 해당 html 우클릭 → copy → copy selector
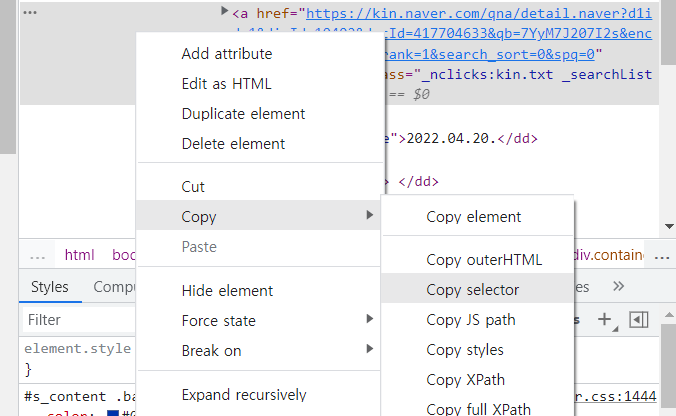
- 복사한 copy selector를 붙여넣어서 코드 작성
- copy selector 예시 :
#s_content > div.section > ul > li:nth-child(1) > dl > dt > a
- copy selector 예시 :
1 | import requests |
- 다음과 같이 처음 지정했던 정보가 출력된다.

텍스트만 출력
- 텍스트만 뽑아오고 싶다면 get_text() 함수를 이용하면 됩니다.
1 | import requests |
- 결과

Crawling start for chatbot data
You need to set
install_url to use ShareThis. Please set it in _config.yml.