Oracle_practice6
집계함수
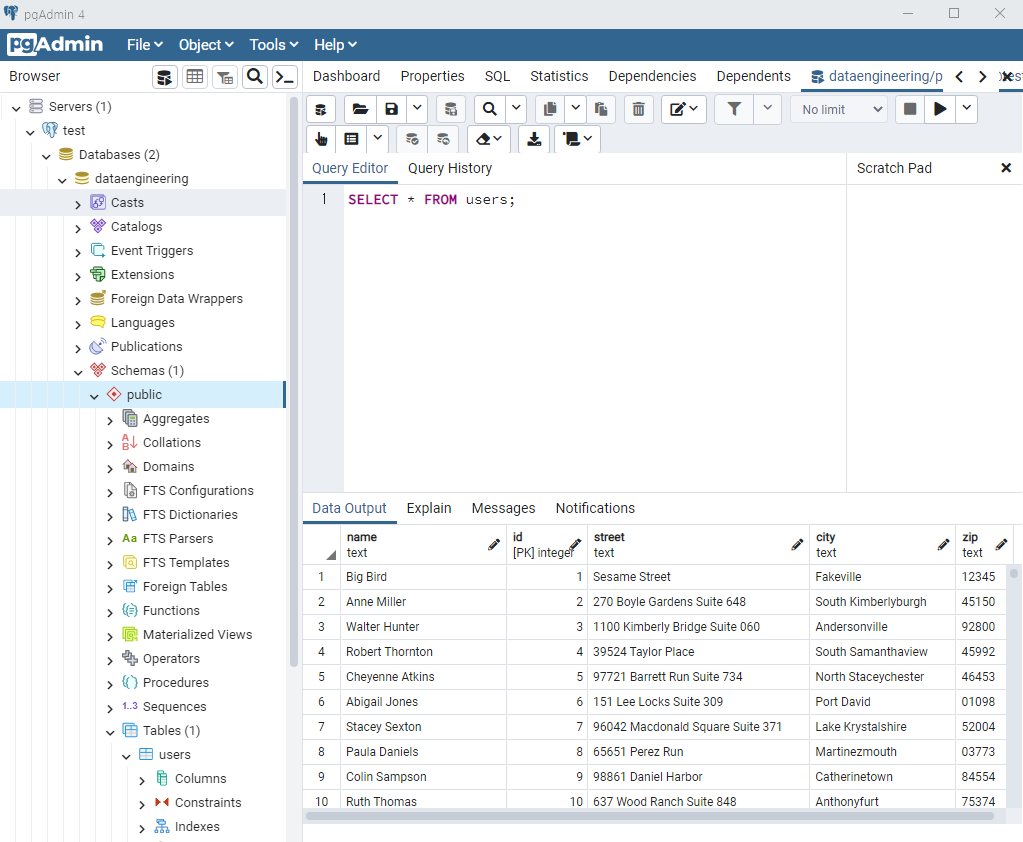
sql developer
sql developer에서 새로운 sql 워크시트를 생성한다.
도구 → sql워크시트 : ch05_0427
오라클 SQL과 PL/SQL을 다루는 기술
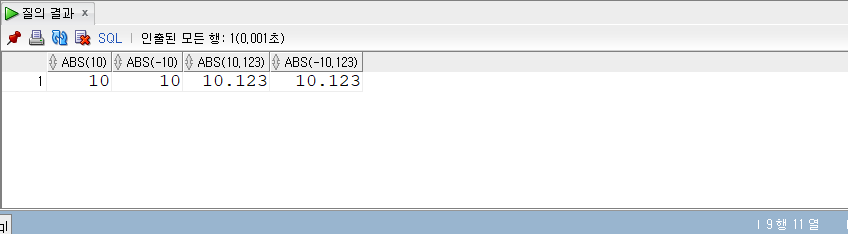
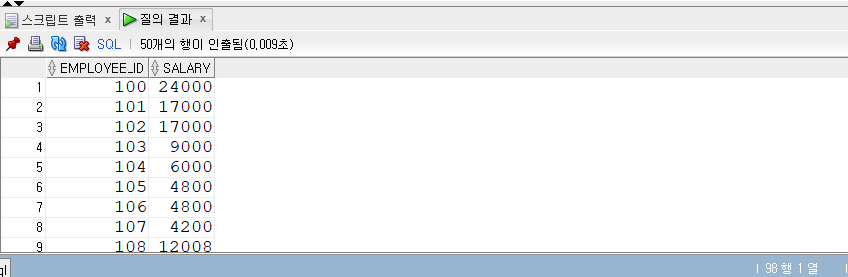
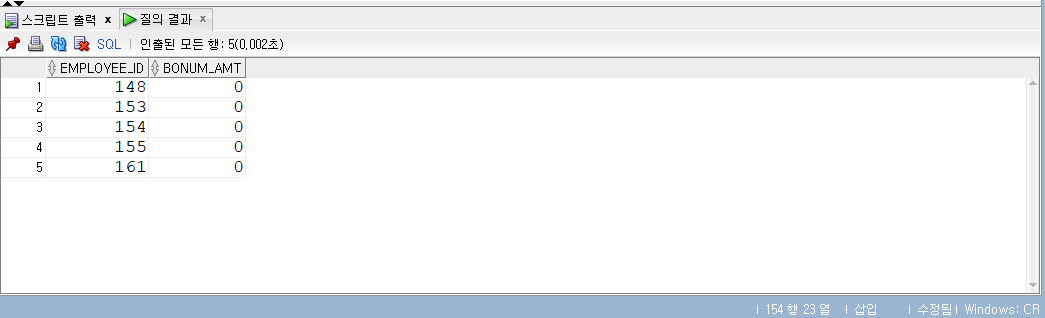
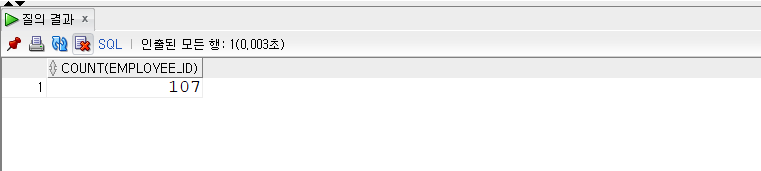
COUNT
- COUNT (expr)
- COUNT는 쿼리 결과 건수, 즉 전체 로우 수를 반환하는 집계 함수다.
- 테이블 전체 로우는 물론 WHERE 조건으로 걸러진 로우 수를 반환한다.
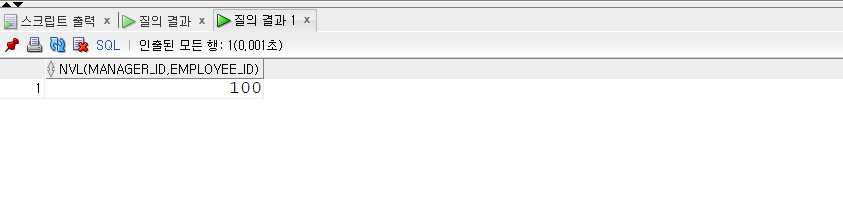
- 대부분은 COUNT() 형태로 사용하는데, ‘’ 대신 컬럼명을 넣기도 한다.
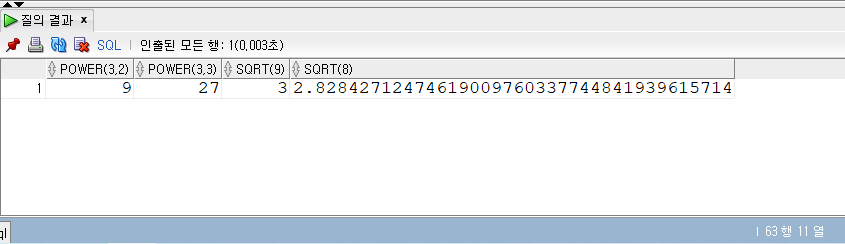
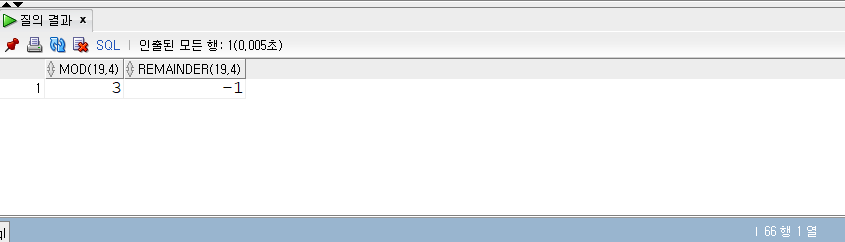
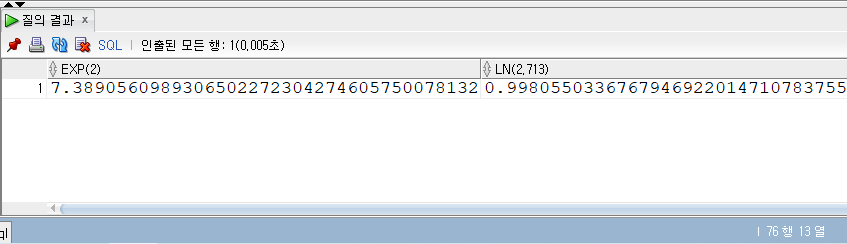
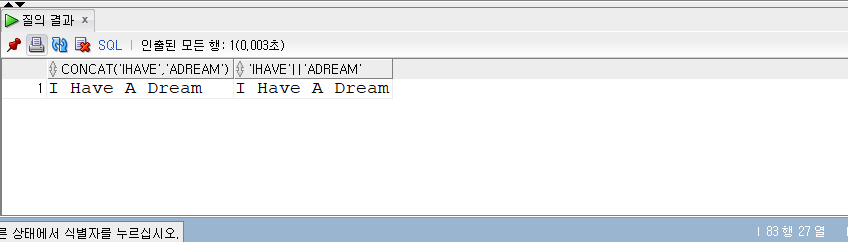
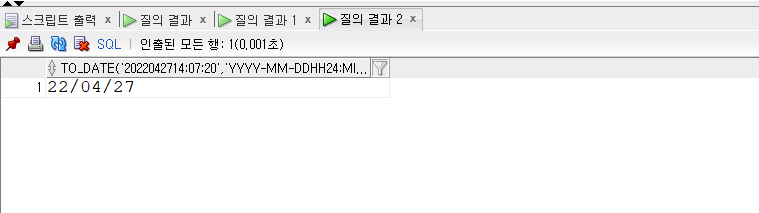
1 | -- 152p |
DISTINCT
- DISTINCT를 붙이면 뒤따라 나오는 컬럼에 있는 유일한 값만 조회된다.
1 | -- DISTINCT |
SUM
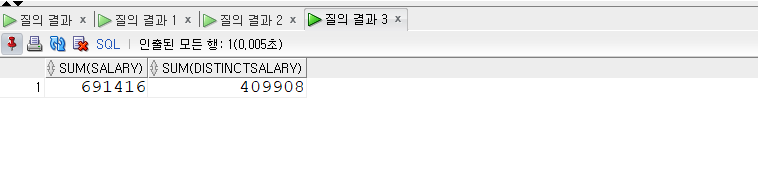
- SUM(expr)
- UM은 expr의 전체 합계를 반환하는 함수로 매개변수 expr에는 숫자형만 올 수 있다.
1 | -- SUM(expr) |
AVG
- AVG(expr)
- AVG는 매개변수 형태나 쓰임새는 COUNT, SUM과 동일하며 평균값을 반환한다.
1 | -- AVG(expr) |

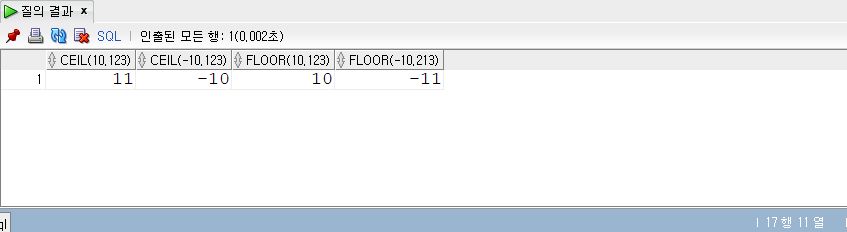
MIN, MAX
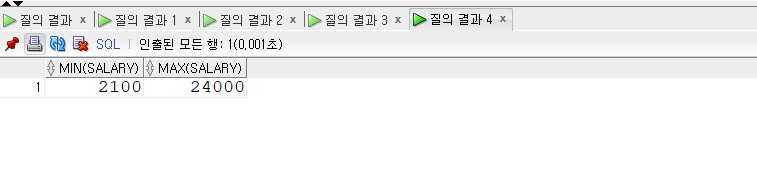
- MIN(expr)
- MIN은 최솟값을 반환한다.
- MAX(expr)
- MAX는 최댓값을 반환한다.
1 | -- MIN, MAX |
VARIANCE, STDDEV
- VARIANCE(expr)
- VARIANCE는 분산을 구해 반환한다.
- STDDEV(expr)
- STDDEV는 표준편차를 구해 반환한다.
1 | -- VARIANCE, STDDEV |

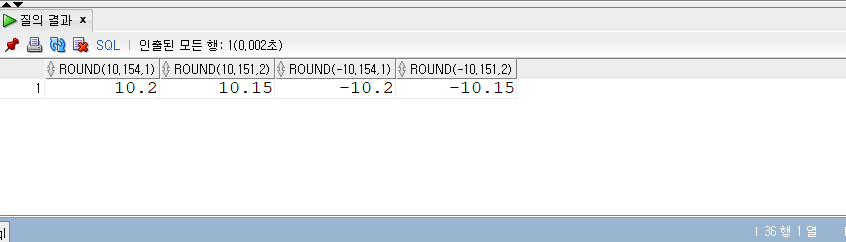
GROUP BY / HAVING
- GROUP BY
- 전체가 아닌 특정 그룹으로 묶어 데이터를 집계할 때 사용되는 구문이다.
- 그룹으로 묶을 컬럼명이나 표현식을 GROUP BY 절에 명시해서 사용한다.
- GROUP BY 구문은 WHERE와 ORDER BY절 사이에 위치한다.
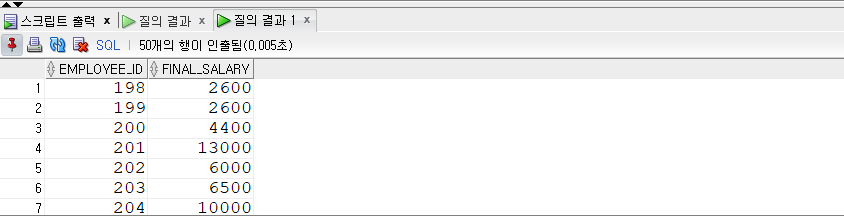
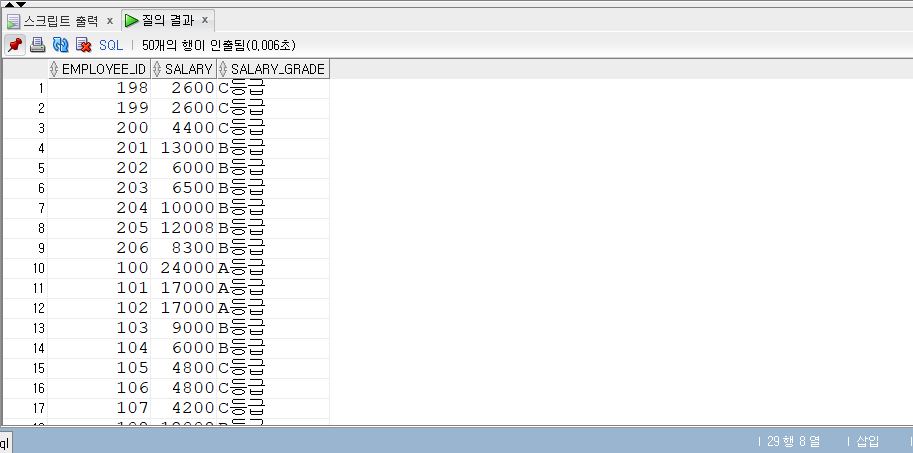
1 | SELECT |
- HAVING
- GROUP BY절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할을 수행.
- HAVING 필터 조건 형태로 사용한다.
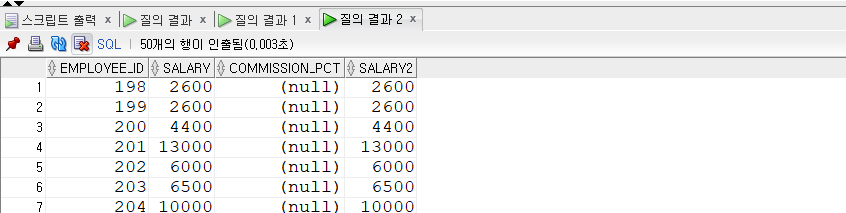
1 | SELECT |
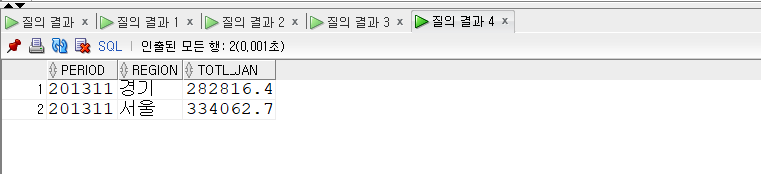
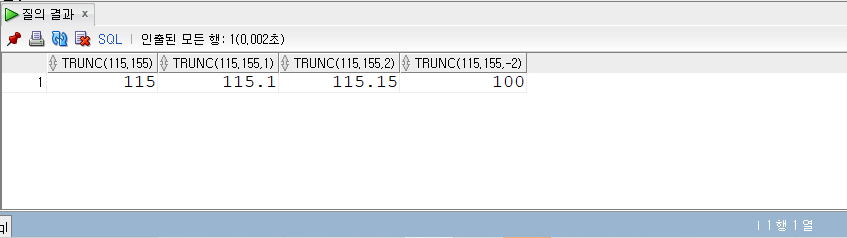
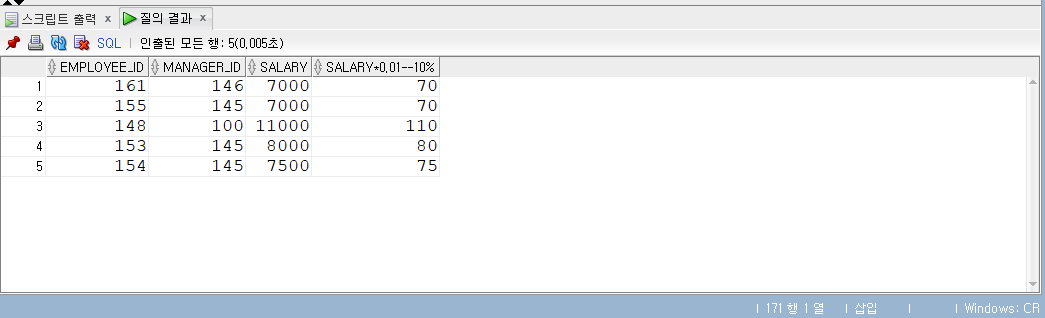
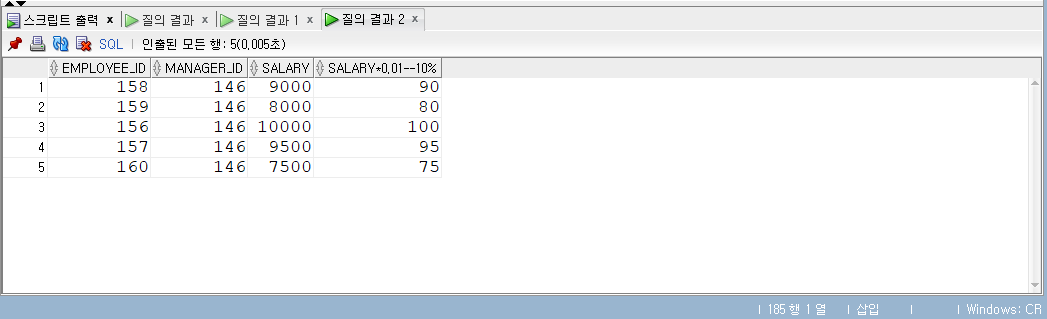
ROLLUP
- ROLLUP(expr1, expr2, …)
- ROLLUP은 expr로 명시한 표현식을 기준으로 집계한 결과, 즉 추가적인 집계 정보를 보여 준다.
- ROLLUP 절에 명시할 수 있는 표현식에는 그룹핑 대상, 즉 SELECT 리스트에서 집계 함수를 제외한 컬럼 등의 표현식이 올 수 있다.
- 명시한 표현식 수와 순서(오른쪽에서 왼쪽 순으로)에 따라 레벨 별로 집계한 결과가 반환된다.
- 표현식 개수가 n개이면 n+1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계된다.
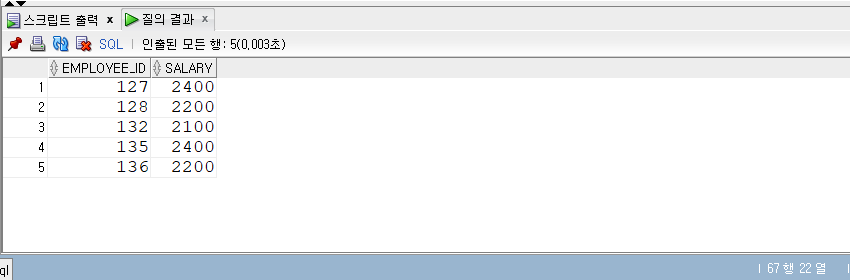
1 | -- 2013년 1개월 총 잔액만 구한다. |
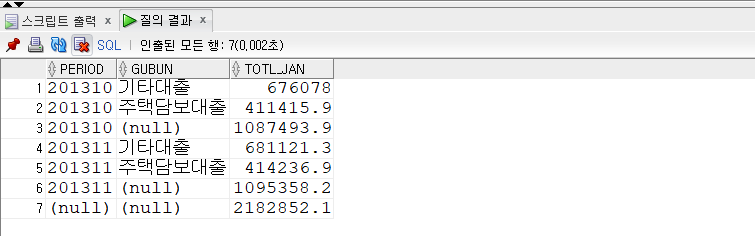
CUBE
- CUBE(expr1, expr2, …)
- ROLLUP과 CUBE는 GROUP BY절에서 사용되어 그룹별 소계를 추가로 보여 주는 역할을 한다.
- ROLLUP이 레벨별로 순차적 집계를 했다면, CUBE는 명시한 표현식 개수에 따라 가능한 모든 조합별로 집계한 결과를 반환한다.
- CUBE는 2의(expr 수)제곱 만큼 종류별로 집계 된다.
- 예를 들어, expr 수가 3이면, 집계 결과의 유형은 총 2^3 = 8개가 된다.
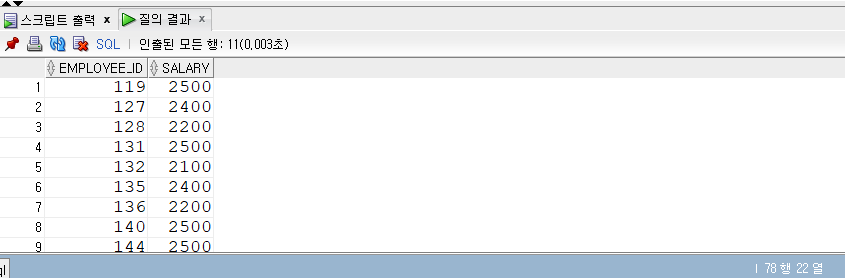
1 | -- CUBE |
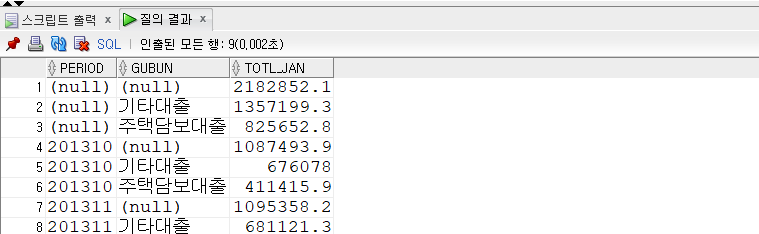
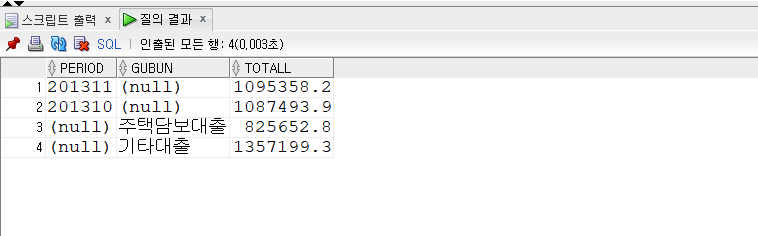
GROUPING SETS
- GROUPING SETS (expr1, expr2, expr3)
- ROLLUP이나 CUBE처럼 GROUP BY 절에 명시해서 그룹 쿼리에 사용되는 절이다.
- GROUP BY 절에 명시했을 때, 괄호 안에 있는 세 표현식별로 각각 집계가 이루어진다.
- 그러므로 쿼리 형태는 다음과 같다.
- ((GROUP BY expr1) UNION ALL (GROUP BY expr2) UNION ALL (GROUP BY expr3))
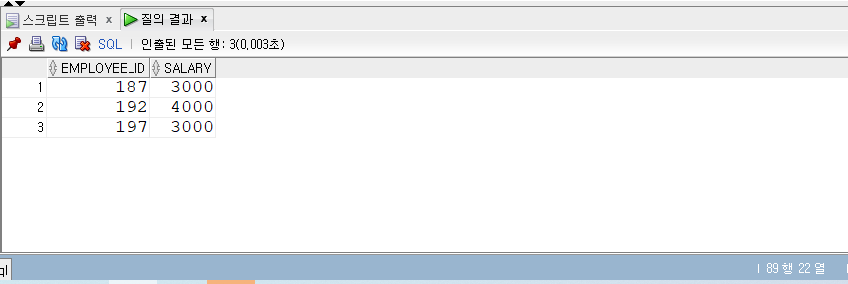
1 | -- GROUPing SETS |
집합 연산자
- 집합(Set) 연산자는 데이터 집합을 대상으로 연산을 수행하는 연산자아더,
- UNION, UNION ALL, INTERSECT, MINUS 등이 있다.
- 다음 데이터로 집합 연산자를 사용해본다.
1 | CREATE TABLE exp_goods_asia ( |
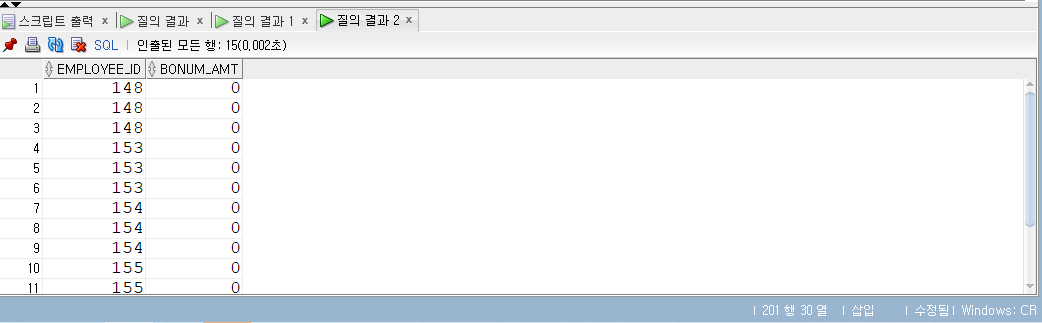
UNION
- UNON은 합집합을 의미한다.
- 예를 들어, 두 데이터 집합이 있으면 각 집합 원소(SELECT 결과)를 모두 포함한 결과가 반환된다.
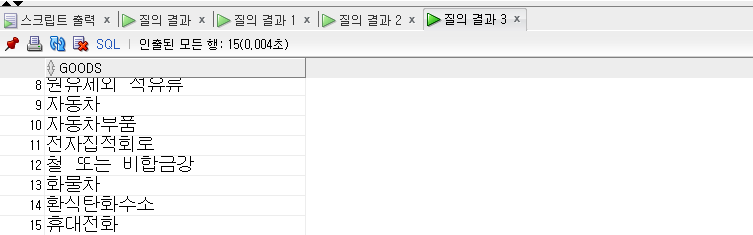
1 | -- UNION |
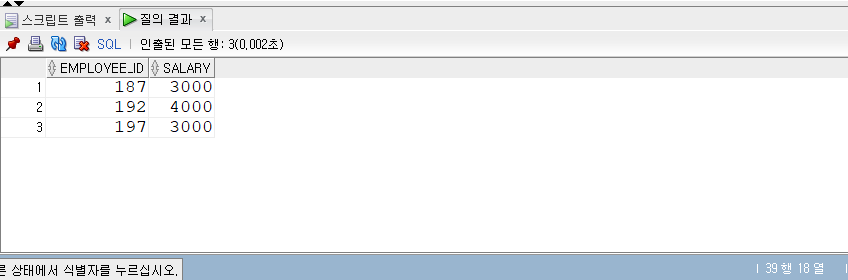
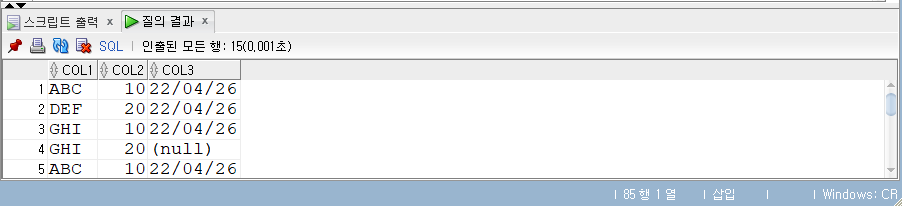
- 중복된 항목 5개를 제외한 15개가 출력되었다.
UNION ALL
- UNION ALL은 UNION과 비슷한데 한 가지 다른 것은 중복된 항목도 모두 조회된다는 점이다.
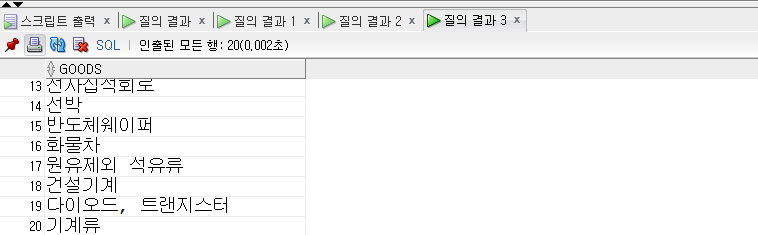
1 | -- UNION ALL |
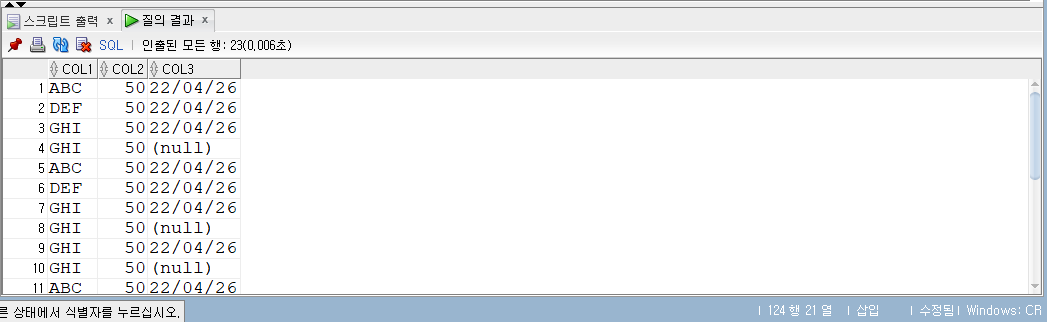
- 중복까지 포함하여 20개의 행의 출력되었다.
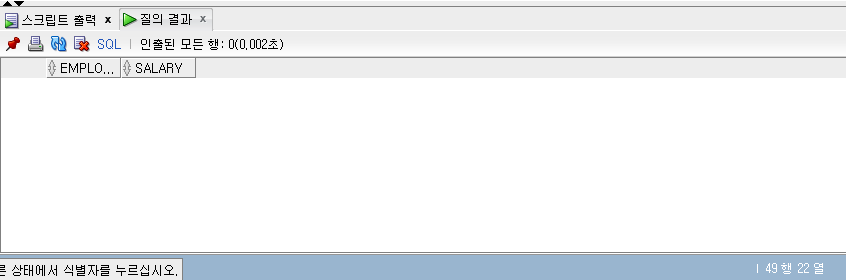
INTERSECT
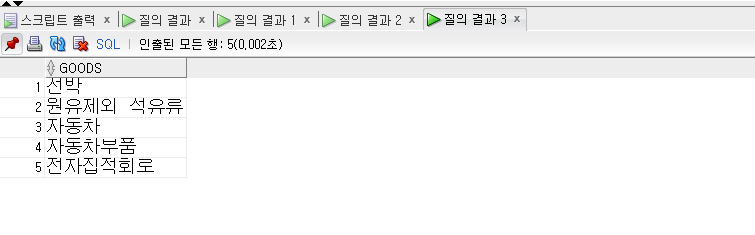
- INTERSECT는 합집합이 아닌 교집합을 의미한다.
- 즉 데이터 집합에서 공통된 항목만 추출해 낸다.
1 | -- INTERSECT |
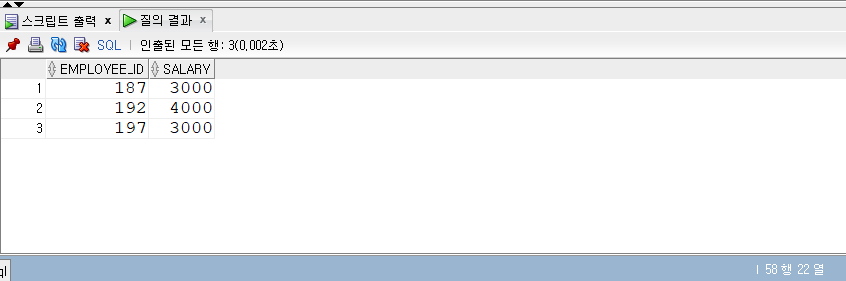
MINUS
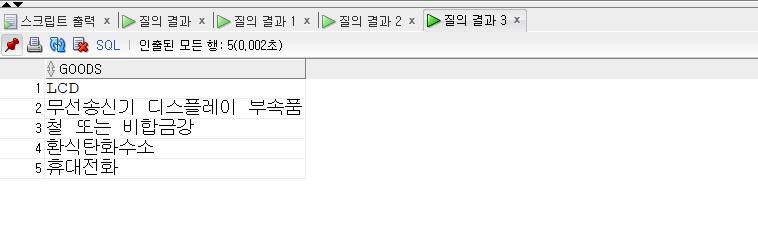
- MINUS는 차집합을 의미한다.
- 즉 한 데이터 집합을 기준으로 다른 데이터 집합과 공통된 항목을 제외한 결과만 추출해 낸다.
1 | -- MINUS |
- Reference : 오라클 SQL과 PL/SQL을 다루는 기술