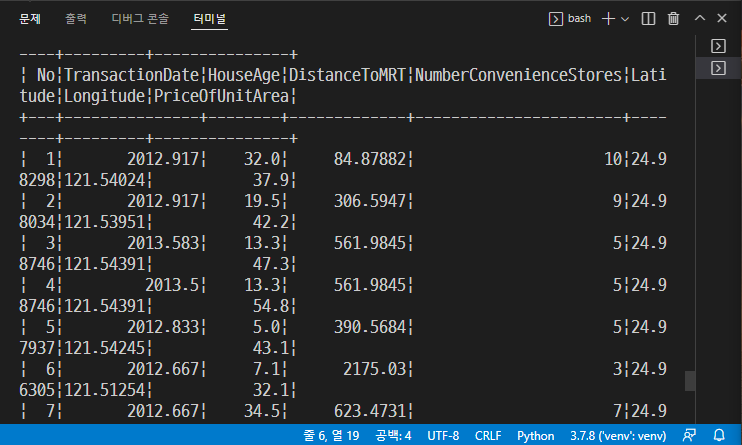
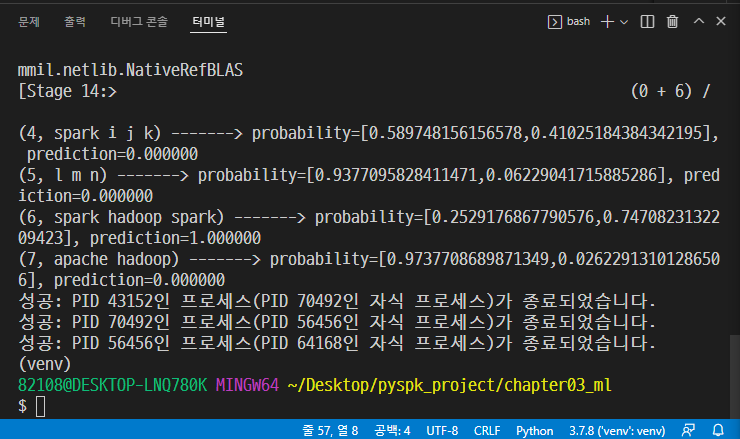
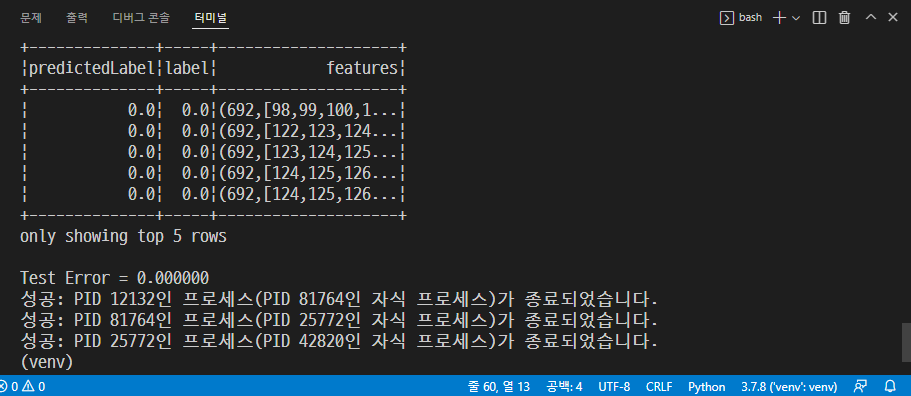
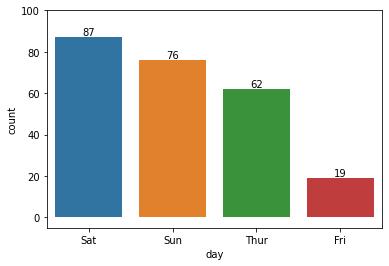from tokenize import Token from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer
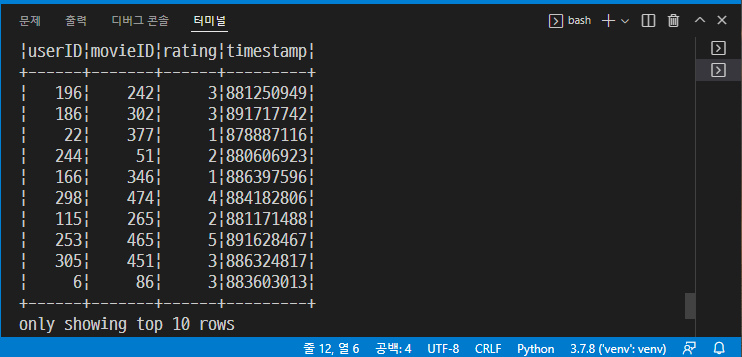
# 가상의 데이터 만들기 training = spark.createDataFrame([ (0, "a b c d e spark", 1.0), (1, "b d", 0.0), (2, "spark f g h", 1.0), (3, "hadoop mapreduce", 0.0) ], ["id", "text", "label"])
# Feature Engineering # 요리 작업
# 요리준비 1단계 : 텍스트를 단어로 분리 tokenizer = Tokenizer(inputCol='text', outputCol='words')
from struct import Struct from pyspark.sql import SparkSession from pyspark.sql import functions as func from pyspark.sql.types import StructType, StructField, IntegerType, LongType
from pyspark.sql import SparkSession from pyspark.sql import functions as func from pyspark.sql.types import StructType, StructField, IntegerType, LongType import codecs
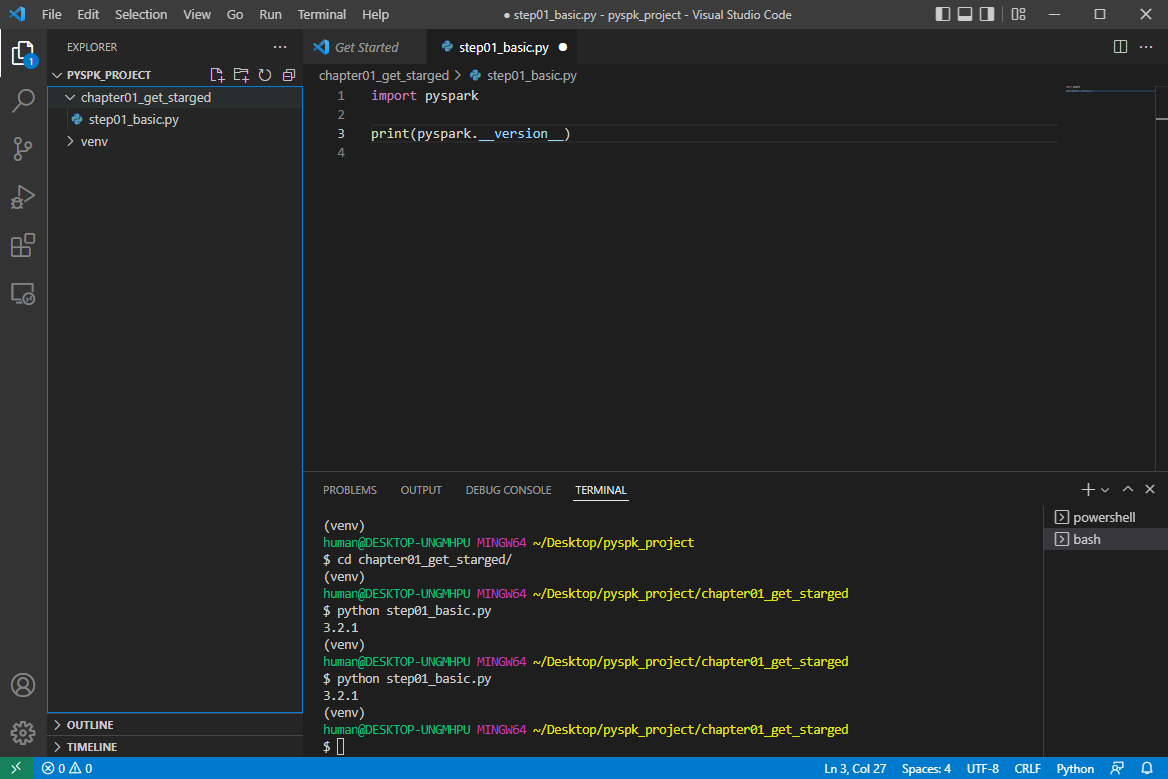
print("Hello")
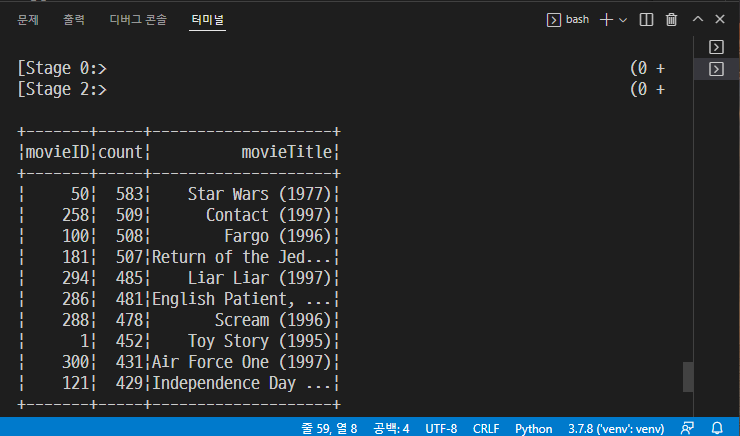
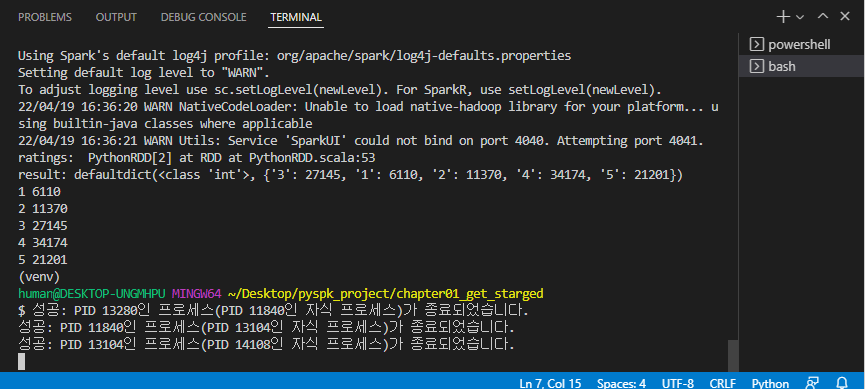
defloadMovieNames(): movieNames = {} with codecs.open("ml-100k/u.ITEM", "r", encoding="ISO-8859-1", errors="ignore") as f: for line in f: fields = line.split("|") movieNames[int(fields[0])] = fields[1] return movieNames
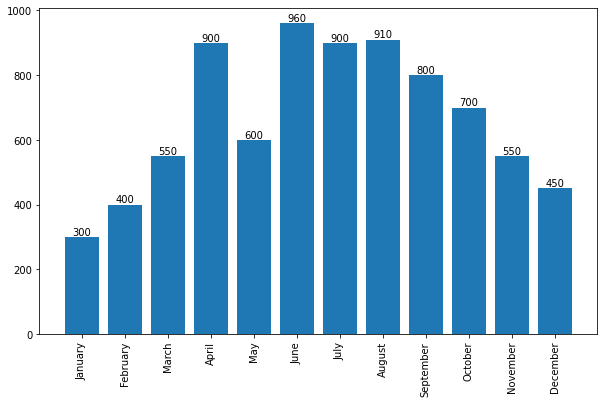
for plot in ax.patches: # matplotlib 와 같은 역할을 수행한다. print(plot) height = plot.get_height() ax.text(plot.get_x() + plot.get_width()/2., height, height, ha = 'center', va = 'bottom')
import matplotlib.pyplot as plt import seaborn as sns import numpy as np from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter)
<script>
const buttonEl =
document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
13.Gotchas (잡았다!)
연산 수행 시 다음과 같은 예외 상황(Error)을 볼 수도 있다.
1 2
if pd.Series([False, True, False]): print("I was true")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-129-5c782b38cd2f> in <module>()
----> 1 if pd.Series([False, True, False]):
2 print("I was true")
/usr/local/lib/python3.7/dist-packages/pandas/core/generic.py in __nonzero__(self)
1536 def __nonzero__(self):
1537 raise ValueError(
-> 1538 f"The truth value of a {type(self).__name__} is ambiguous. "
1539 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1540 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
이런 경우에는 any(), all(), empty 등을 사용해서 무엇을 원하는지를 선택 (반영)해주어야 한다.
1 2
if pd.Series([False, True, False])isnotNone: print("I was not None")
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:4: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
after removing the cwd from sys.path.
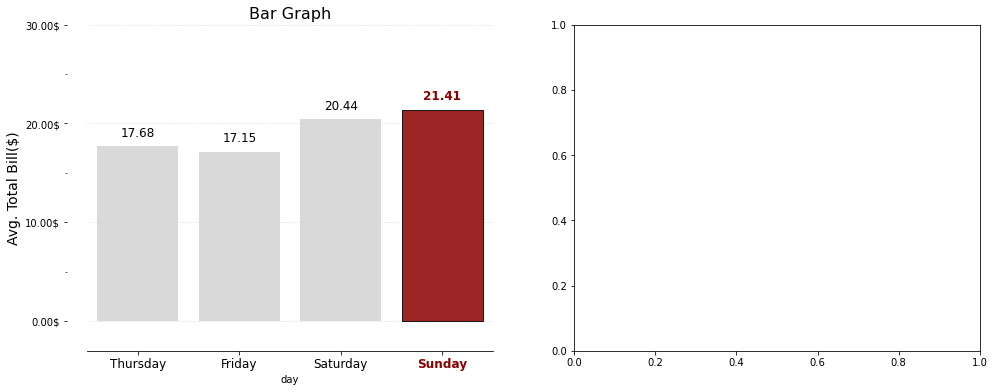
Revenue
Lemon
max
min
sum
mean
max
min
sum
mean
Location
Beach
95.5
43.0
1002.8
58.988235
162
76
2020
118.823529
Park
134.5
41.0
1178.2
78.546667
176
71
1697
113.133333
<script>
const buttonEl =
document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
# np.arange(5) -> 0 부터 시작하는 5개의 배열 생성 temp_arr = np.arange(5) temp_arr
array([0, 1, 2, 3, 4])
1 2 3
# np.arange(1, 11, 3) -> 1 부터 11까지 3만큼 차이나게 배열 생성 temp_arr = np.arange(1, 11, 3) temp_arr
array([ 1, 4, 7, 10])
1 2 3 4 5 6 7
# np.zeros -> 0으로 채운 배열 만들기 zero_arr = np.zeros((2,3)) print(zero_arr) print(type(zero_arr)) print(zero_arr.shape) print(zero_arr.ndim) print(zero_arr.dtype) # dype = data type
# 5보다 큰 값은 곱하기 2, 2보다 작은 값은 더하기 100 condlist = [temp_arr > 5, temp_arr <2] # 조건식 choielist = [temp_arr *2, temp_arr + 100] # 같은 위치의 조건 만족 시, 설정한 대로 변환 np.select(condlist, choielist, default = temp_arr)