from tensorflow import keras (train_input, train_target), (test_input, test_target)= keras.datasets.fashion_mnist.load_data() # load.data()함수는 훈련 데이터와 테스트 데이터를 나누어 반환한다.
데이터 확인
훈련 데이터
60,000개 이미지, 이미지 크기는 28x28
타깃은 60,000개 원소가 있는 1차원 배열
1
print(train_input.shape, train_target.shape)
(60000, 28, 28) (60000,)
테스트 세트
10,000개의 이미지로 이루어짐
1
print(test_input.shape, test_target.shape)
(10000, 28, 28) (10000,)
이미지 시각화
1 2 3 4 5 6
import matplotlib.pyplot as plt fig, axs = plt.subplots(1, 10, figsize=(10,10)) for i inrange(10): axs[i].imshow(train_input[i], cmap='gray_r') axs[i].axis('off') plt.show()
타겟 값 리스트
패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성된다.
같은 숫자가 나온다면 타깃이 같은 두 샘플은 같은 종류의 옷이다.
1
print([train_target[i] for i inrange(10)])
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
실제 타겟값의 값을 확인
각 라벨당 6000개의 이미지 존재 60,000개
즉, 각 의류마다 6,000개의 샘플이 들어있다.
1 2
import numpy as np print(np.unique(train_target, return_counts = True))
Flatten 클래스를 층처럼 입렬층과 은닉층 사잉에 추가하기 때문에 이를 층이라 부른다.
다음 코드처럼 입력층 바로 뒤에 추가한다.
1 2 3 4 5 6
model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) # 기존 코드 비교 model.add(keras.layers.Dense(100, activation='relu')) # relu 로 변경 model.add(keras.layers.Dense(10, activation='softmax'))
적응적 학습률을 사용하는 이 3개의 클래스는 learning_rate 매개변수의 기본값을 0.001로 두고 사용한다.
Adam 클래스의 매개변수 기본값을 사용해 패션 MNIST 모델을 훈련해본다.
일단 모델을 다시 생성한다.
1 2 3 4
model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) # 기존 코드 비교 model.add(keras.layers.Dense(100, activation='relu')) # relu 로 변경 model.add(keras.layers.Dense(10, activation='softmax'))
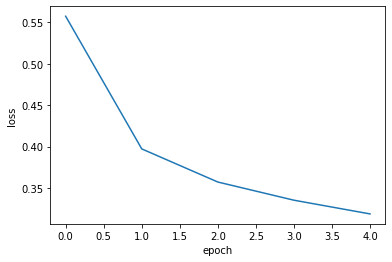
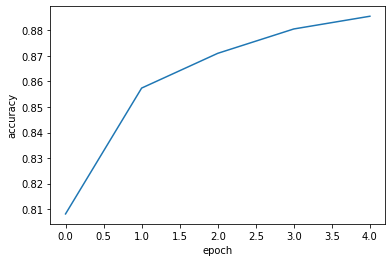
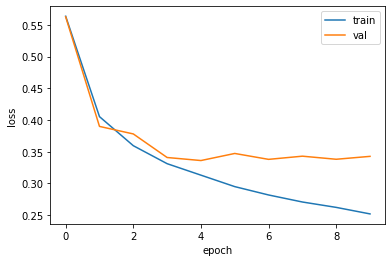
compile() 메서드의 optimizer를 ‘adam’으로 설정하고 5번의 에포크 동안 훈련한다.
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 1s 0us/step
26435584/26421880 [==============================] - 1s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
모델을 만든다.
사용자 정의함수를 작성함
if 구문을 제외하면 7-2의 코드와 동일하다.
if 구문의 역할은 model_fn() 함수에 케라스 층을 추가하면 은닉층 뒤어 또 하나의 층을 추가하는 것이다.
모델 구조를 출력해본다.
1 2 3 4 5 6 7 8 9 10
defmodel_fn(a_layer=None): model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) model.add(keras.layers.Dense(100, activation='relu')) if a_layer: model.add(a_layer) model.add(keras.layers.Dense(100, activation='softmax')) return model model = model_fn() model.summary()
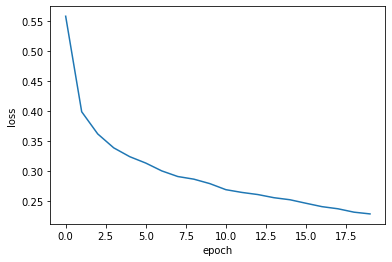
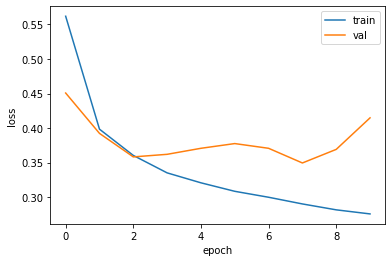
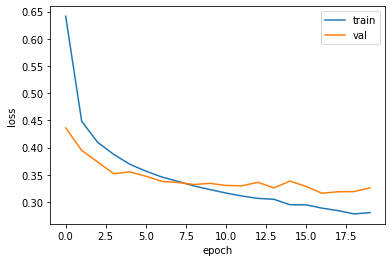
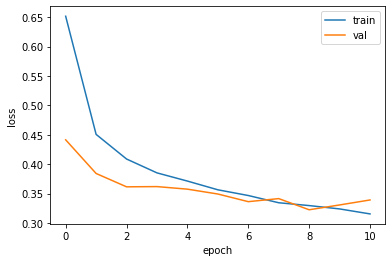
model = model_fn(keras.layers.Dropout(0.3)) # 30% 드롭아웃 model.compile(optimizer = 'adam', loss='sparse_categorical_crossentropy', metrics='accuracy') # adam 추가
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, # 수치 조정 validation_data=(val_scaled, val_target))