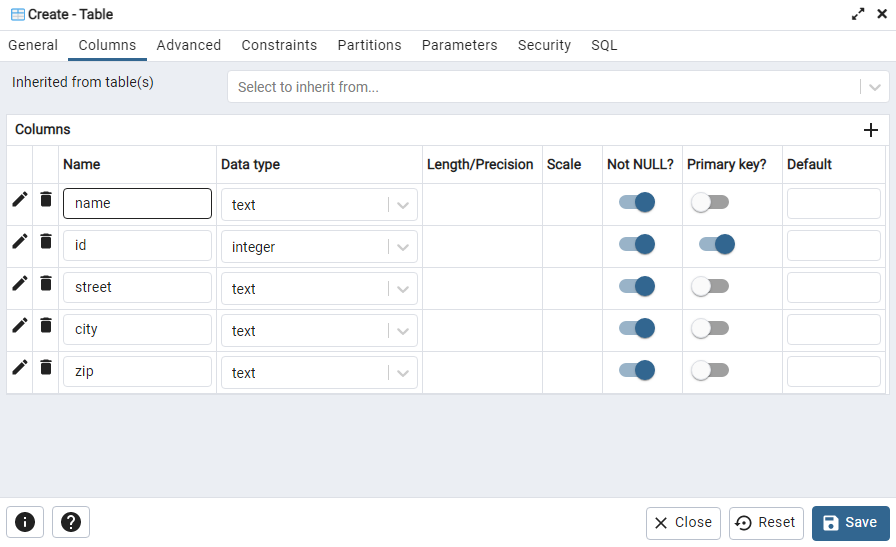
Airflow 재설치 및 데이터 파이프라인 구축
Setting up Apache-Airflow in Windows using WSL2 - Data Science | DSChloe
Airflow 데이터 파이프라인 구축 예제 - Data Science | DSChloe
- 체크포인트
가상환경을 만들 수 있는냐 (virtualenv 라이브러리)
경로 이동이 자유로운가? cd 사용
환경 변수를 이해하고 잡을 수 있는가?
vi 편집기를 자유자재로 쓸 수 있는가?
파이썬 라이브러리를 가상환경에 자유자재로 설치 할 수 있는가?
가상 환경에 자유롭게 출입할 수 있는가?
- 사전 준비
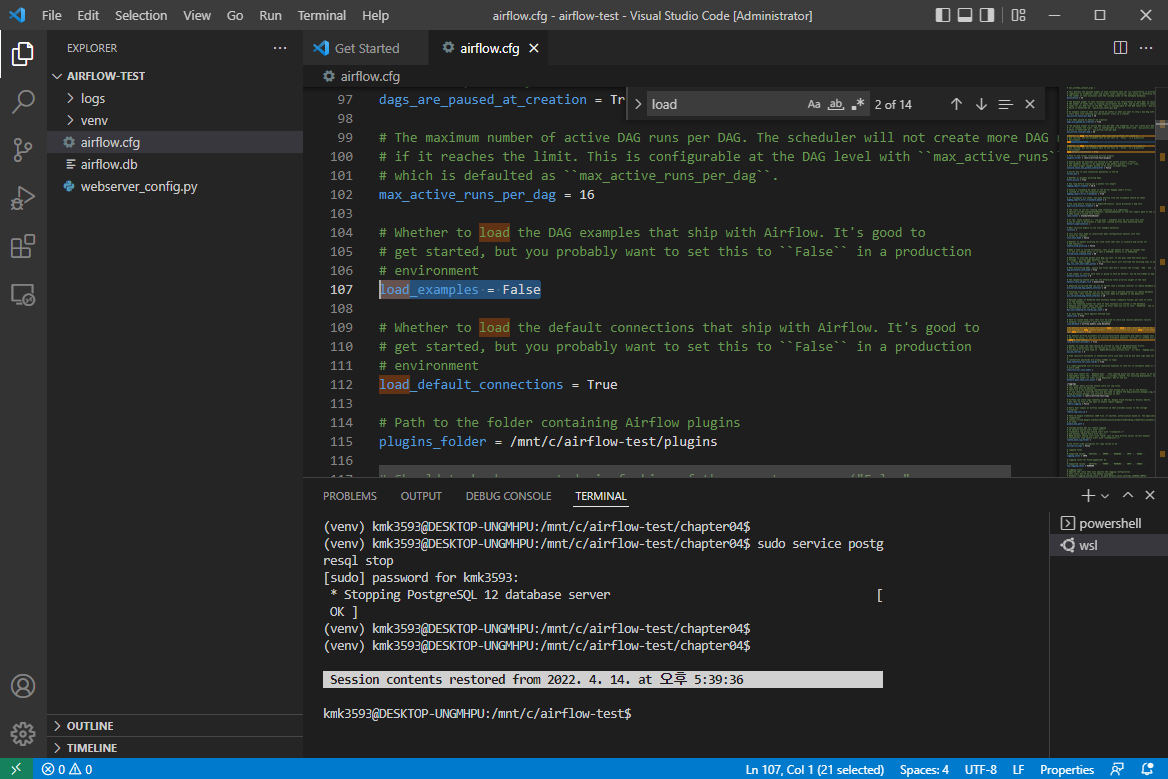
VSCord 의 airflow.cfg 에서 진행
→ 내용 변경 : load_examples = True ⇒ False
→ c드라이브 → airflow_test → dags와 chapter03, chapter04 를 배경화면에 빼둔다.
- airflow-test 내용물 삭제
Ubuntu 의 airflow 경로에서 진행
→deactivate
→sudo rm -rf *
- 다시 가상환경 생성
→virtualenv venv
→ls
- 필요한 내용이 작성되어 있는지 확인
→ vi ~/.bashrc
→ 내용 확인 : export AIRFLOW_HOME=/mnt/c/airflow-test
→ source ~/.bashrc
→ echo $AIRFLOW_HOME
→pwd
- 가상환경 on
→ source venv/bin/activate
- 라이브러리 설치
→ pip3 install 'apache-airflow[postgres, slack, celery]'
- db 설정
→ airflow db init
- 계정 등록
- firstname이 실행 결과에 영향을 주는가
→ airflow users create --username airflow --password airflow --firstname evan --lastname airflow --role Admin --email your_email@some.com
- VSCord 에서 진행
→ 폴더 생성 : ( file → open folder → airflow-test )
→ airflow.cfg 파일
→ 내용 변경 : load_examples=True ⇒ False
- Ubuntu 에서 진행
→ airflow db reset
→ 가상 환경 상태에서 다음 코드 실행
→ airflow webserver -p 8080
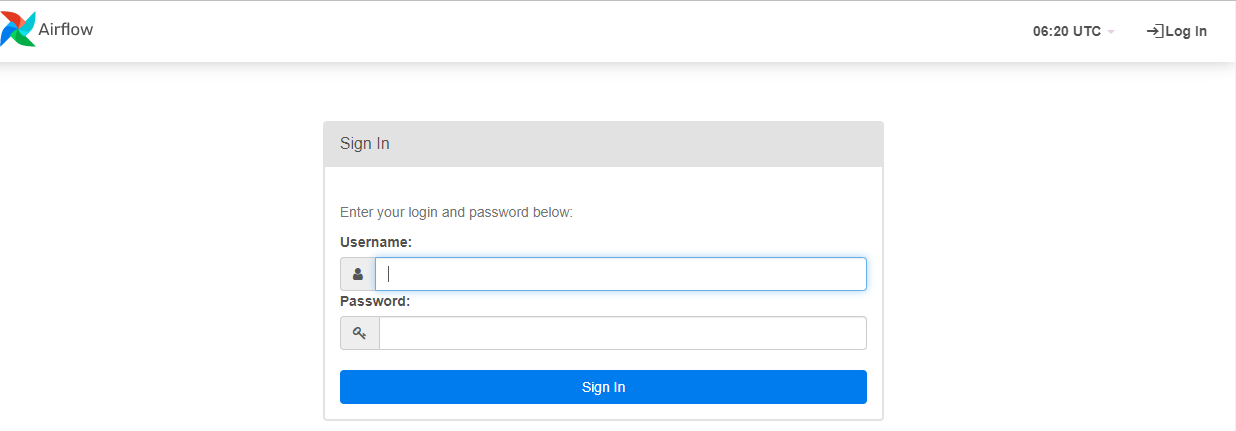
- 그리고, 해당 링크에 http://localhost:8080/login/ 접속하면 아래와 같은 화면이 나타난다.
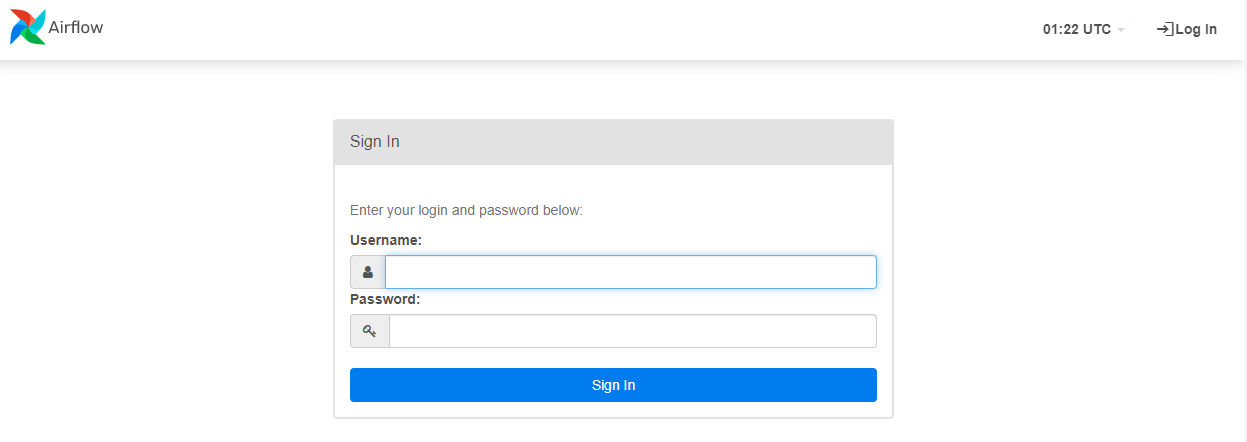
→ ctrl + c 로 빠져나온다.
데이터 파이프라인 구축
개요
- 이번에는 CSV-JSON으로 데이터를 변환하는 파이프라인을 구축하도록 한다.
Step 01. Dags 폴더 생성
프로젝트 Root 하단에 Dags 폴더를 만든다.
- dags 폴더를 확인한다.
dags 파일 생성
→mkdir dags
→ls
Step 02. 가상의 데이터 생성
- 라이브러리 설치
→ 가상 환경에서 진행
→ pip3 install faker pandas
- 폴더, 파일 생성
→ mkdir data
→ cd data
→ vi step01_writecsv.py
→ 코드 작성.
+ 앞으로는 이런 방식으로 코드를 작성한다.
+실무에서 필요한 습관이다.
- faker 라이브러리를 활용하여 가상의 데이터를 생성한다. (파일 경로 : data/step01_writecsv.py)
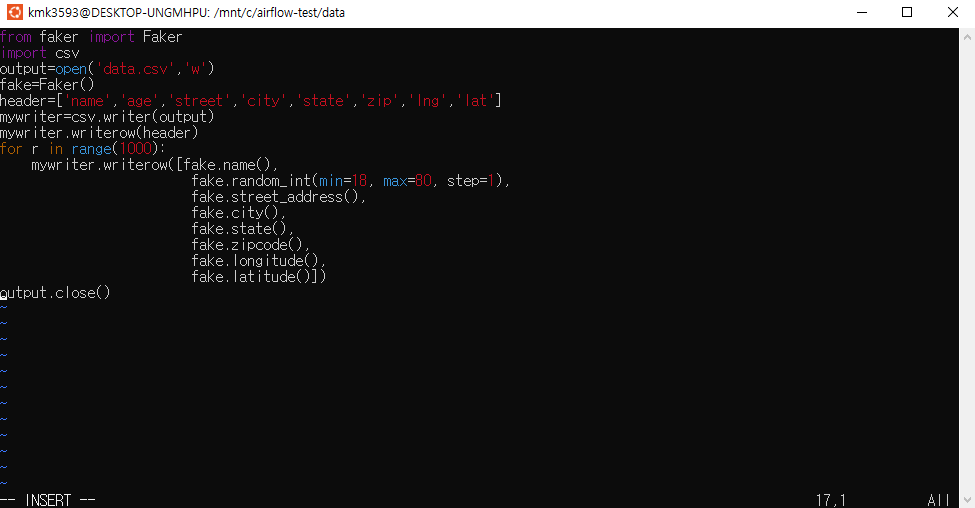
1 | from faker import Faker |
- 코드를 실행한다.
- VSCord에서 data.csv 파일이 생성되어야 한다.
→ python3 step01_writecsv.py
→ ls
→ cat data.csv
Step 03. csv2json 파일 구축
- 이번에는 CSV와 JSON 변환 파일을 구축하는 코드를 작성한다. (파일 경로 : dags/csv2json.py)\
- 주요 목적 함수 csvToJson()의 역할은
data/data.csv파일을 불러와서fromAirflow.json파일로 변경하는 것이다. - DAG는 csvToJson 함수를 하나의 작업으로 등록하는 과정을 담는다. 작업의 소유자, 시작일시, 실패 시 재시도 횟수, 재시도 지연시 시간을 지정한다.
- 자세한 옵션은 도움말을 참조한다. https://airflow.apache.org/docs/apache-airflow/stable/concepts/dags.html
print_starting >> csvJson에서>>는 하류 설정 연산자라고 부른다. (동의어 비트 자리이동 연산자)
→cd ..
→cd dags
→vi csv2json.py
1 | import datetime as dt |
- 코드를 실행한다.
- VSCord에서 json 파일이 생성되어야 한다.
→python3 csv2json.py
Step 04. Airflow Webserver 및 Scheduler 동시 실행
- 이제 웹서버와 스케쥴러를 동시에 실행한다. (터미널을 2개 열어야 함에 주의한다.)
VSCord 에서 WSL 터미널을 2개 띄운다.
→ airflow webserver -p 8080
→airflow scheduler
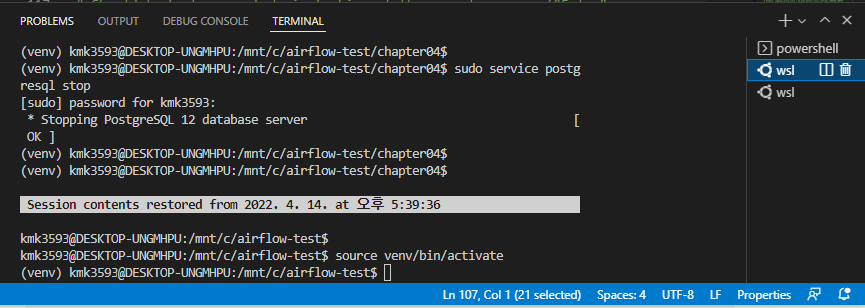
- error 발생할 경우 대처
airflow.cfg의 endproint_url = 8080 체크
→airflow db reset
→airflow webserver -p 8080
→airflow scheduler
→ 이 과정을 반복
→ 그래도 안 되면 airflow 지우고 다시 시작
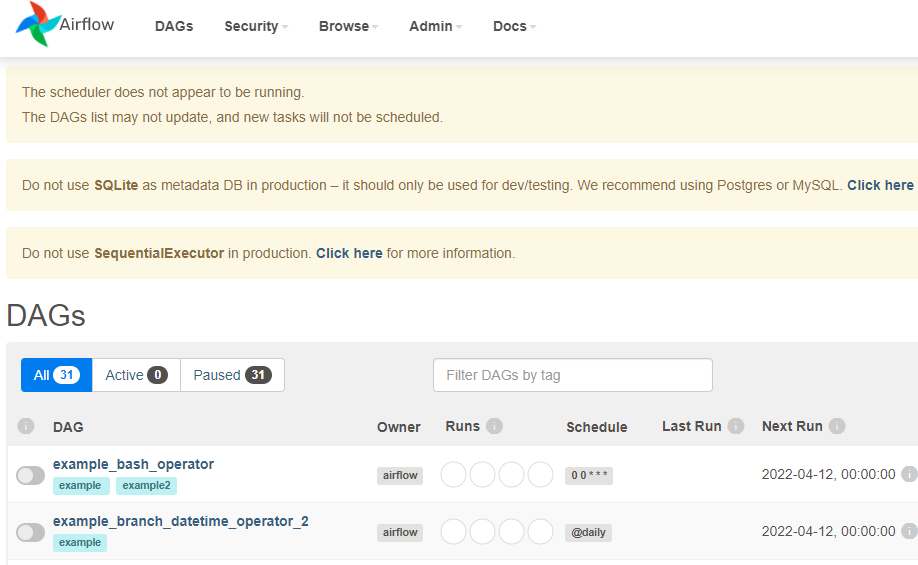
이제 WebUI를 확인하면 정상적으로 작동하는 것을 확인할 수 있다
Step 05. 작업 결과물 확인
최초 목적인
fromAirflow.json로 정상적으로 변환되었는지 확인하도록 한다.fromAirflow.json파일이 확인된다면, 정상적으로 작업이 끝난 것이다.
→
ls→ 다음 내용이 출력되면 성공
→
airflow-webserver.pid airflow.cfg airflow.db dags data fromAirflow.json logs venv webserver_config.py- 팁
human@DESKTOP-V24TVMS:/mnt/c/airflow$
export AIRFLOW_HOME="$(pwd)"human@DESKTOP-V24TVMS:/mnt/c/airflow$
echo $AIRFLOW_HOMEReference : 실무 예제로 배우는 데이터 공학