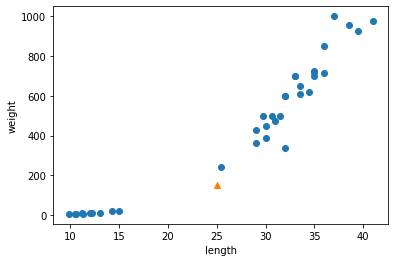
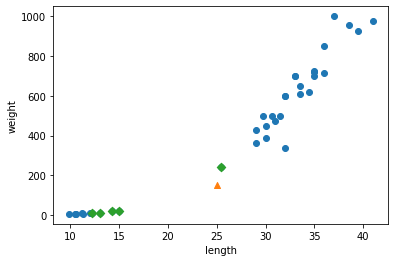
# OR 연산자(|) 를 사용하여 비교 결과를 합친다. bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt') train_bream_smelt = train_scaled[bream_smelt_indexes] target_bream_smelt = train_target[bream_smelt_indexes]
위에서 bream_smelt_indexes 배열은 도미와 빙어일 경우만 True값이 들어간다.
이 배열을 사용해 train_scaled와 train_targt 배열에 불리언 인덱싱을 적용하여 도미와 빙어 데이터만 골라낼 수 있다.
186p
모형 만들고 예측하기!
이제 이 데이터로 로지스틱 회귀 모델을 훈련한다.
1 2 3 4
from sklearn.linear_model import LogisticRegression lr = LogisticRegression() # 독립변수 종속변수 lr.fit(train_bream_smelt, target_bream_smelt)
LogisticRegression()
훈련한 모델을 사용해 train_bream_smelt에 있는 처음 5개 샘플을 예측한다.
1 2 3 4
# 예측하기 # 클래스로 분류 # 확률값 -> 0.5 print(lr.predict(train_bream_smelt[:5]))
['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
2 번째 샘플을 제외하고 모두 도미로 예측했다.
예측 확률은 predict_proba() 메서드에서 제공한다.
처음 5개 샘플의 예측 확률을 출력해 본다.
1 2
print(lr.predict_proba(train_bream_smelt[:5])) # predict_proba에서 예측 확률 제공 print(lr.classes_)
하지만 이런 모델은 훈련 세트에 너무 과대적합되므로 테스트 세트에서는 형편없는 점수를 만든다.
이 문제를 해결하기 위해 2가지 방법이 있다.
방법 1. 다시 특성을 줄인다.
방법 2. 규제를 사용한다.
규제 (regularization)
규제는 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말한다.
즉 모델이 훈련 세트에 과대적합되지 않도록 만드는 것이다.
회귀 모델의 경우 특성에 곱해지는 계수(또는 기울기)의 크기를 작게 만드는 일이다.
1 2 3 4 5 6
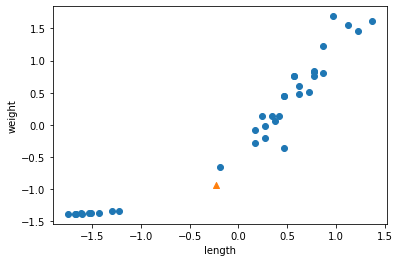
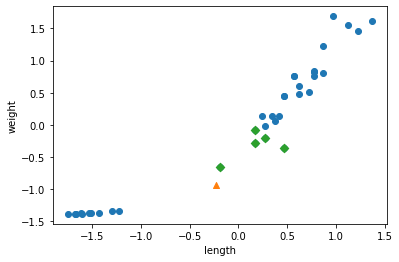
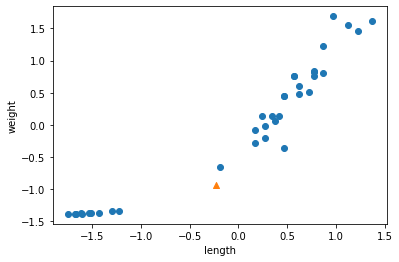
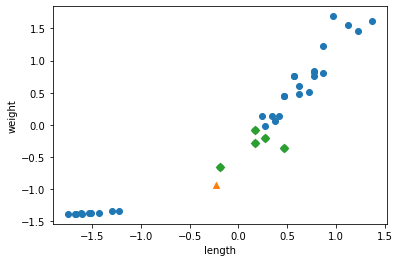
# 규제하기 전에 먼저 정규화를 진행한다. from sklearn.preprocessing import StandardScaler # 이 클래스는 변환기의 하나이다. ss = StandardScaler() ss.fit(train_poly) train_scaled = ss.transform(train_poly) test_scaled = ss.transform(test_poly)
StandardScaler 클래스의 객체 ss를 초기화한 후 PolynomialFeatures 클래스로 만든 train_poly를 사용해 이 객체를 훈련한다.
aplha 값이 작으면 계수를 줄이는 역할이 줄어들고 선형 회귀 모델과 유사해지므로 과대적합될 가능성이 크다.
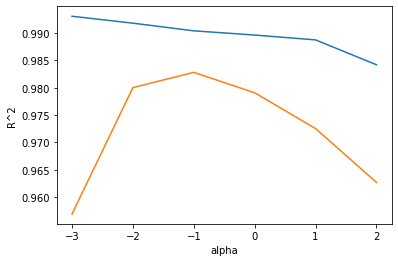
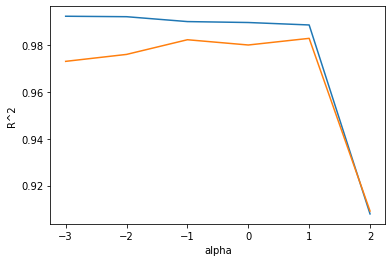
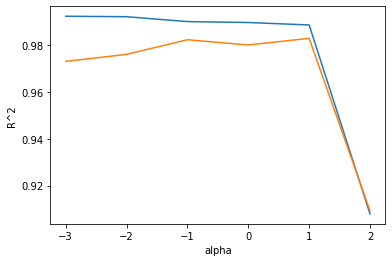
적절한 alpha값을 찾는 한 가지 방법은 alpha값에 R^2값의 그래프를 그려 보는 것이다.
훈련 세트와 테스트 세트의 점수가 가장 가까운 지점이 최적의 alpha 값이 된다.
alpha값을 바꿀 때마다 score() 메서드의 결과를 저장할 리스트를 만든다.
1 2 3
import matplotlib.pyplot as plt train_score = [] test_score = []
다음은 alpha를 0.001에서 100까지 10배씩 늘려가며 릿지 회귀 모델을 훈련한 다음 훈련 세트와 테스트 세트의 점수를 리스트에 저장한다.
사람이 직버 지정해야 하는 매개변수 (하이퍼 파라미터)
다 돌려봐서 성능이 놓은 alpha 값 찾기
경우의 수 (15가지)
A 조건 : 5가지
B 조건 : 3가지
1 2 3 4 5 6 7 8 9
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100] for alpha in alpha_list: # 릿지 모델을 만든다. ridge = Ridge(alpha=alpha) # 릿지 모델을 훈련한다. ridge.fit(train_scaled, train_target) # 훈련 점수와 테스트 점수를 저장한다. train_score.append(ridge.score(train_scaled, train_target)) test_score.append(ridge.score(test_scaled, test_target))
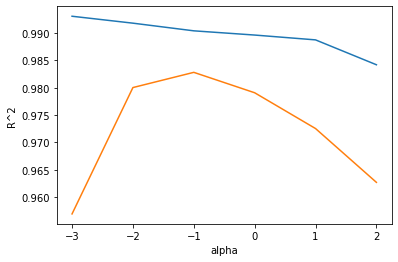
이제 그래프를 그려본다.
alpha 값을 10배씩 늘렸기 때문에 그래프 일부가 너무 촘촘해진다.
alpha_list에 있는 6개의 값을 동일한 간격으로 나타내기 위해 로그 함수로 바꾸어 지수로 표현한다.
앞에서와 같이 alpha값을 바꾸어 가며 훈련 세트와 테스트 세트에 대한 점수를 계산한다.
1 2 3 4 5 6 7 8 9 10 11
train_score = [] test_score = [] alpha_list = [0.001, 0.01, 0.1, 1, 10, 100] for alpha in alpha_list: # 라쏘 모델을 만든다. lasso = Lasso(alpha=alpha, max_iter = 10000) # 반복 횟수를 충분히 늘리기 위해 값을 지정. # 라쏘 모델을 훈련한다. lasso.fit(train_scaled, train_target) # 훈련 점수와 테스트 점수를 저장한다. train_score.append(lasso.score(train_scaled, train_target)) test_score.append(lasso.score(test_scaled, test_target))
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_coordinate_descent.py:648: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.878e+04, tolerance: 5.183e+02
coef_, l1_reg, l2_reg, X, y, max_iter, tol, rng, random, positive
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_coordinate_descent.py:648: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.297e+04, tolerance: 5.183e+02
coef_, l1_reg, l2_reg, X, y, max_iter, tol, rng, random, positive
0.990137631128448
0.9819405116249363
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_coordinate_descent.py:648: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 8.062e+02, tolerance: 5.183e+02
coef_, l1_reg, l2_reg, X, y, max_iter, tol, rng, random, positive
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100] for alpha in alpha_list: # 릿지 모델을 만듭니다 ridge = Ridge(alpha=alpha) # 릿지 모델을 훈련합니다 ridge.fit(train_scaled, train_target) # 훈련 점수와 테스트 점수를 저장합니다 train_score.append(ridge.score(train_scaled, train_target)) test_score.append(ridge.score(test_scaled, test_target))
0.9903815817570366
0.9827976465386926
0.989789897208096
0.9800593698421883
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_coordinate_descent.py:648: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.878e+04, tolerance: 5.183e+02
coef_, l1_reg, l2_reg, X, y, max_iter, tol, rng, random, positive
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_coordinate_descent.py:648: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.297e+04, tolerance: 5.183e+02
coef_, l1_reg, l2_reg, X, y, max_iter, tol, rng, random, positive
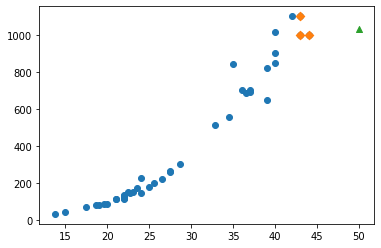
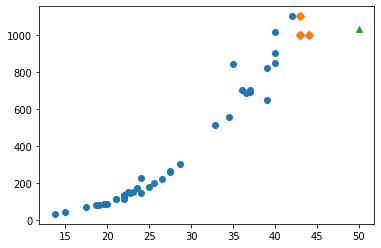
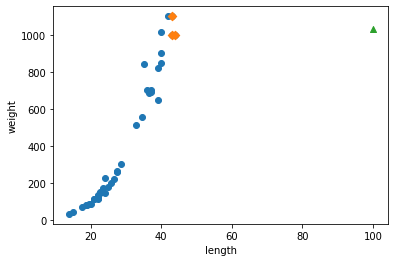
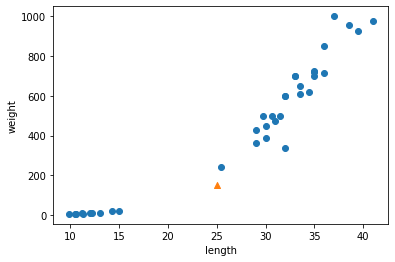
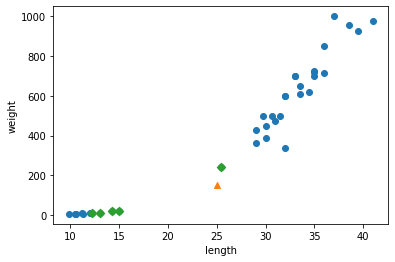
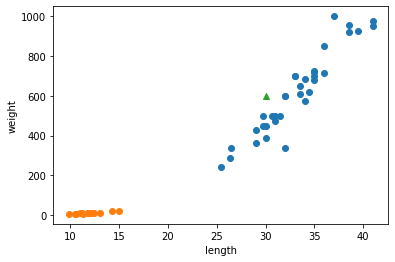
# 훈련 세트의 산점도를 그립니다 plt.scatter(train_input, train_target) # 훈련 세트 중에서 이웃 샘플만 다시 그립니다 plt.scatter(train_input[indexes], train_target[indexes], marker='D') # 50cm 농어 데이터 plt.scatter(50, 1033, marker='^') plt.xlabel('length') plt.ylabel('weight') plt.show()
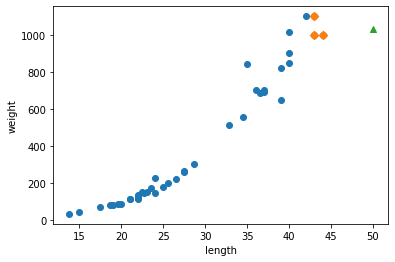
# 훈련 세트의 산점도를 그립니다 plt.scatter(train_input, train_target) # 훈련 세트 중에서 이웃 샘플만 다시 그립니다 plt.scatter(train_input[indexes], train_target[indexes], marker='D') # 100cm 농어 데이터 plt.scatter(100, 1033, marker='^') plt.xlabel('length') plt.ylabel('weight') plt.show()
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # 선형 회귀 모델 훈련 lr.fit(train_input, train_target)
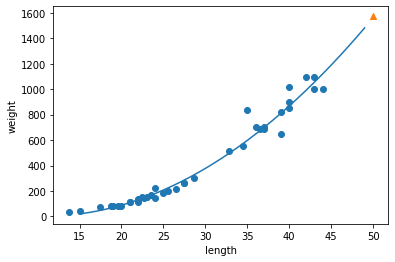
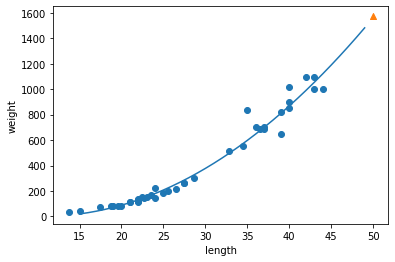
# 50cm 농어에 대한 예측 print(lr.predict([[50]]))
print(lr.coef_, lr.intercept_)
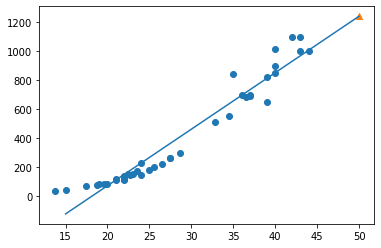
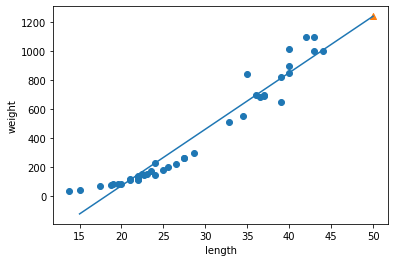
# 훈련 세트의 산점도를 그립니다 plt.scatter(train_input, train_target) # 15에서 50까지 1차 방정식 그래프를 그립니다 plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_]) # 50cm 농어 데이터 plt.scatter(50, 1241.8, marker='^') plt.xlabel('length') plt.ylabel('weight') plt.show()
for plot in ax.patches: # matplotlib 와 같은 역할을 수행한다. print(plot) height = plot.get_height() ax.text(plot.get_x() + plot.get_width()/2., height, height, ha = 'center', va = 'bottom')
import matplotlib.pyplot as plt import seaborn as sns import numpy as np from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter)
<script>
const buttonEl =
document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
13.Gotchas (잡았다!)
연산 수행 시 다음과 같은 예외 상황(Error)을 볼 수도 있다.
1 2
if pd.Series([False, True, False]): print("I was true")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-129-5c782b38cd2f> in <module>()
----> 1 if pd.Series([False, True, False]):
2 print("I was true")
/usr/local/lib/python3.7/dist-packages/pandas/core/generic.py in __nonzero__(self)
1536 def __nonzero__(self):
1537 raise ValueError(
-> 1538 f"The truth value of a {type(self).__name__} is ambiguous. "
1539 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1540 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
이런 경우에는 any(), all(), empty 등을 사용해서 무엇을 원하는지를 선택 (반영)해주어야 한다.
1 2
if pd.Series([False, True, False])isnotNone: print("I was not None")