pandas_tutorial_01
데이터 전처리
- 데이터 전처리의 기본
- garbage Data —[ Great Model ]—> Garbage Results
데이터 전처리의 주요 과정
- 데이터 전처리 수행 프로세스***(중요)***
- 1.중복값 제거 및 결측치 처리 -> 2.이상치 처리 -> 3.Feature Engineering
- 주요 목적 : 더 나은 분석 결과 도출 및 모형 성능 개선 실현
pandas 기본자료형
- 숫자, 문자 모두 들어간다.
- 중복이 불가능하다.
판다스
라이브러리 불러오기
1 | import pandas as pd |
1.3.5
테스트
1 | temp_dic = {"col1": [1,2,3], |
| col1 | col2 | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 4 |
| 2 | 3 | 5 |
<script>
const buttonEl =
document.querySelector('#df-5f12a67d-363f-495e-a8d6-e15402e0c5d6 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-5f12a67d-363f-495e-a8d6-e15402e0c5d6');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | print(type(df)) |
<class 'pandas.core.frame.DataFrame'>
1 | temp_dic = {'a':1, 'b':2, 'c':3} |
a 1
b 2
c 3
dtype: int64
<class 'pandas.core.series.Series'>
구글 드라이브 연동
- 구글 드라이브 → colab notebook → 새 폴더 생성 : data → 슬랙에서 다운 받은 lemonade.csv 파일을 올린다 -> 다음 코드를 실행
1 | from google.colab import drive |
Mounted at /content/drive
Mounted at ..drive 가 출력되었으므로 성공
현재 좌측에 폴더 그림 -> drive -> mydrive -> Colab Notebooks -> data -> Lemonade2016.csv를 찾아서 우클릭 -> 경로 복사 -> 다음 코드에 붙여넣어 사용
1 | DATA_PATH = '/content/drive/MyDrive/Colab Notebooks/data/Lemonade2016.csv' |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | |
|---|---|---|---|---|---|---|---|
| 0 | 7/1/2016 | Park | 97 | 67 | 70 | 90.0 | 0.25 |
| 1 | 7/2/2016 | Park | 98 | 67 | 72 | 90.0 | 0.25 |
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 |
| 3 | 7/4/2016 | Beach | 134 | 99 | 76 | 98.0 | 0.25 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 |
| 5 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 |
| 6 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 |
| 7 | 7/7/2016 | Beach | 143 | 101 | 81 | 135.0 | 0.25 |
| 8 | NaN | Beach | 123 | 86 | 82 | 113.0 | 0.25 |
| 9 | 7/9/2016 | Beach | 134 | 95 | 80 | 126.0 | 0.25 |
| 10 | 7/10/2016 | Beach | 140 | 98 | 82 | 131.0 | 0.25 |
| 11 | 7/11/2016 | Beach | 162 | 120 | 83 | 135.0 | 0.25 |
| 12 | 7/12/2016 | Beach | 130 | 95 | 84 | 99.0 | 0.25 |
| 13 | 7/13/2016 | Beach | 109 | 75 | 77 | 99.0 | 0.25 |
| 14 | 7/14/2016 | Beach | 122 | 85 | 78 | 113.0 | 0.25 |
| 15 | 7/15/2016 | Beach | 98 | 62 | 75 | 108.0 | 0.50 |
| 16 | 7/16/2016 | Beach | 81 | 50 | 74 | 90.0 | 0.50 |
| 17 | 7/17/2016 | Beach | 115 | 76 | 77 | 126.0 | 0.50 |
| 18 | 7/18/2016 | Park | 131 | 92 | 81 | 122.0 | 0.50 |
| 19 | 7/19/2016 | Park | 122 | 85 | 78 | 113.0 | 0.50 |
| 20 | 7/20/2016 | Park | 71 | 42 | 70 | NaN | 0.50 |
| 21 | 7/21/2016 | Park | 83 | 50 | 77 | 90.0 | 0.50 |
| 22 | 7/22/2016 | Park | 112 | 75 | 80 | 108.0 | 0.50 |
| 23 | 7/23/2016 | Park | 120 | 82 | 81 | 117.0 | 0.50 |
| 24 | 7/24/2016 | Park | 121 | 82 | 82 | 117.0 | 0.50 |
| 25 | 7/25/2016 | Park | 156 | 113 | 84 | 135.0 | 0.50 |
| 26 | 7/26/2016 | Park | 176 | 129 | 83 | 158.0 | 0.35 |
| 27 | 7/27/2016 | Park | 104 | 68 | 80 | 99.0 | 0.35 |
| 28 | 7/28/2016 | Park | 96 | 63 | 82 | 90.0 | 0.35 |
| 29 | 7/29/2016 | Park | 100 | 66 | 81 | 95.0 | 0.35 |
| 30 | 7/30/2016 | Beach | 88 | 57 | 82 | 81.0 | 0.35 |
| 31 | 7/31/2016 | Beach | 76 | 47 | 82 | 68.0 | 0.35 |
<script>
const buttonEl =
document.querySelector('#df-e4ed5b94-20e7-42ba-9f65-459f54e1728a button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-e4ed5b94-20e7-42ba-9f65-459f54e1728a');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
- 데이터를 불러왔다.
- 첫번째 파악해야 하는 것!
- 데이터 구조를 파악해보자
1 | juice.info() # 데이터 구조 파악 |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32 entries, 0 to 31
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 31 non-null object
1 Location 32 non-null object
2 Lemon 32 non-null int64
3 Orange 32 non-null int64
4 Temperature 32 non-null int64
5 Leaflets 31 non-null float64
6 Price 32 non-null float64
dtypes: float64(2), int64(3), object(2)
memory usage: 1.9+ KB
1 | juice.head() # 상위의 데이터를 여러개 불러온다. 디폴트 값이 5개. |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | |
|---|---|---|---|---|---|---|---|
| 0 | 7/1/2016 | Park | 97 | 67 | 70 | 90.0 | 0.25 |
| 1 | 7/2/2016 | Park | 98 | 67 | 72 | 90.0 | 0.25 |
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 |
| 3 | 7/4/2016 | Beach | 134 | 99 | 76 | 98.0 | 0.25 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 |
<script>
const buttonEl =
document.querySelector('#df-c3238942-1033-4010-80b8-10e94c66dc23 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-c3238942-1033-4010-80b8-10e94c66dc23');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | juice.tail() # 하위의 데이터를 여러개 불러온다. 디폴트 값이 5개 |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | |
|---|---|---|---|---|---|---|---|
| 27 | 7/27/2016 | Park | 104 | 68 | 80 | 99.0 | 0.35 |
| 28 | 7/28/2016 | Park | 96 | 63 | 82 | 90.0 | 0.35 |
| 29 | 7/29/2016 | Park | 100 | 66 | 81 | 95.0 | 0.35 |
| 30 | 7/30/2016 | Beach | 88 | 57 | 82 | 81.0 | 0.35 |
| 31 | 7/31/2016 | Beach | 76 | 47 | 82 | 68.0 | 0.35 |
<script>
const buttonEl =
document.querySelector('#df-cc60af2a-dd96-48c1-9398-546b4a947c77 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-cc60af2a-dd96-48c1-9398-546b4a947c77');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
- Describe() 함수
- 기술통계량 확인해주는 함수
1 | juice.describe() |
| Lemon | Orange | Temperature | Leaflets | Price | |
|---|---|---|---|---|---|
| count | 32.000000 | 32.000000 | 32.000000 | 31.000000 | 32.000000 |
| mean | 116.156250 | 80.000000 | 78.968750 | 108.548387 | 0.354687 |
| std | 25.823357 | 21.863211 | 4.067847 | 20.117718 | 0.113137 |
| min | 71.000000 | 42.000000 | 70.000000 | 68.000000 | 0.250000 |
| 25% | 98.000000 | 66.750000 | 77.000000 | 90.000000 | 0.250000 |
| 50% | 113.500000 | 76.500000 | 80.500000 | 108.000000 | 0.350000 |
| 75% | 131.750000 | 95.000000 | 82.000000 | 124.000000 | 0.500000 |
| max | 176.000000 | 129.000000 | 84.000000 | 158.000000 | 0.500000 |
<script>
const buttonEl =
document.querySelector('#df-bfd69db7-f9d2-49ea-84ed-2989ca9e02a8 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-bfd69db7-f9d2-49ea-84ed-2989ca9e02a8');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | type(juice.describe()) # Describe함수 결과물의 타입은 DataFrame 이다. |
pandas.core.frame.DataFrame
- value_counts()
1 | print(juice['Location'].value_counts()) |
Beach 17
Park 15
Name: Location, dtype: int64
<class 'pandas.core.series.Series'>
데이터 다뤄보기
- 행과 열을 핸들링 해보자.
1 | juice['Sold'] = 0 # sold 열 추가. |
Date Location Lemon Orange Temperature Leaflets Price Sold
0 7/1/2016 Park 97 67 70 90.0 0.25 0
1 7/2/2016 Park 98 67 72 90.0 0.25 0
2 7/3/2016 Park 110 77 71 104.0 0.25 0
1 | juice['Sold'] = juice['Lemon'] + juice['Orange'] # Sold에 값 설정 |
Date Location Lemon Orange Temperature Leaflets Price Sold
0 7/1/2016 Park 97 67 70 90.0 0.25 164
1 7/2/2016 Park 98 67 72 90.0 0.25 165
2 7/3/2016 Park 110 77 71 104.0 0.25 187
- 매출액 = 가격 x 판매량
- Revenue 로 만들어보자
1 | juice['Revenue'] = juice['Sold'] * juice['Price'] |
Date Location Lemon Orange Temperature Leaflets Price Sold \
0 7/1/2016 Park 97 67 70 90.0 0.25 164
1 7/2/2016 Park 98 67 72 90.0 0.25 165
2 7/3/2016 Park 110 77 71 104.0 0.25 187
Revenue
0 41.00
1 41.25
2 46.75
- drop(axis = 0|1)
- axis는 ‘축’을 의미한다. 한 축을 따라서 연산이 된다.
- axis를 0으로 설정 시, 행(=index)방향으로 drop() 실행
- axis를 1로 설정 시, 열방향으로 drop 수행함.
1 | juice_column_drop = juice.drop('Sold', axis = 1) |
Date Location Lemon Orange Temperature Leaflets Price Revenue
0 7/1/2016 Park 97 67 70 90.0 0.25 41.00
1 7/2/2016 Park 98 67 72 90.0 0.25 41.25
2 7/3/2016 Park 110 77 71 104.0 0.25 46.75
1 | juice_row_drop = juice.drop(0, axis = 0) |
Date Location Lemon Orange Temperature Leaflets Price Sold \
1 7/2/2016 Park 98 67 72 90.0 0.25 165
2 7/3/2016 Park 110 77 71 104.0 0.25 187
3 7/4/2016 Beach 134 99 76 98.0 0.25 233
Revenue
1 41.25
2 46.75
3 58.25
데이터 인덱싱
1 | juice[0:5] |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 7/1/2016 | Park | 97 | 67 | 70 | 90.0 | 0.25 | 164 | 41.00 |
| 1 | 7/2/2016 | Park | 98 | 67 | 72 | 90.0 | 0.25 | 165 | 41.25 |
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 | 187 | 46.75 |
| 3 | 7/4/2016 | Beach | 134 | 99 | 76 | 98.0 | 0.25 | 233 | 58.25 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 | 277 | 69.25 |
<script>
const buttonEl =
document.querySelector('#df-bfa3fabe-e933-4527-879f-12c188c0b8bd button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-bfa3fabe-e933-4527-879f-12c188c0b8bd');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
boolean 값을 활용한 데이터 추출
1 | # location이 Beach인 경우 |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 7/4/2016 | Beach | 134 | 99 | 76 | 98.0 | 0.25 | 233 | 58.25 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 | 277 | 69.25 |
| 5 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 | 172 | 43.00 |
| 6 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 | 172 | 43.00 |
| 7 | 7/7/2016 | Beach | 143 | 101 | 81 | 135.0 | 0.25 | 244 | 61.00 |
| 8 | NaN | Beach | 123 | 86 | 82 | 113.0 | 0.25 | 209 | 52.25 |
| 9 | 7/9/2016 | Beach | 134 | 95 | 80 | 126.0 | 0.25 | 229 | 57.25 |
| 10 | 7/10/2016 | Beach | 140 | 98 | 82 | 131.0 | 0.25 | 238 | 59.50 |
| 11 | 7/11/2016 | Beach | 162 | 120 | 83 | 135.0 | 0.25 | 282 | 70.50 |
| 12 | 7/12/2016 | Beach | 130 | 95 | 84 | 99.0 | 0.25 | 225 | 56.25 |
| 13 | 7/13/2016 | Beach | 109 | 75 | 77 | 99.0 | 0.25 | 184 | 46.00 |
| 14 | 7/14/2016 | Beach | 122 | 85 | 78 | 113.0 | 0.25 | 207 | 51.75 |
| 15 | 7/15/2016 | Beach | 98 | 62 | 75 | 108.0 | 0.50 | 160 | 80.00 |
| 16 | 7/16/2016 | Beach | 81 | 50 | 74 | 90.0 | 0.50 | 131 | 65.50 |
| 17 | 7/17/2016 | Beach | 115 | 76 | 77 | 126.0 | 0.50 | 191 | 95.50 |
| 30 | 7/30/2016 | Beach | 88 | 57 | 82 | 81.0 | 0.35 | 145 | 50.75 |
| 31 | 7/31/2016 | Beach | 76 | 47 | 82 | 68.0 | 0.35 | 123 | 43.05 |
<script>
const buttonEl =
document.querySelector('#df-f23f5092-ba57-4126-bdd5-ecc3581c90cd button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-f23f5092-ba57-4126-bdd5-ecc3581c90cd');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | # location이 Beach인 경우 |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 | 187 | 46.75 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 | 277 | 69.25 |
| 7 | 7/7/2016 | Beach | 143 | 101 | 81 | 135.0 | 0.25 | 244 | 61.00 |
| 8 | NaN | Beach | 123 | 86 | 82 | 113.0 | 0.25 | 209 | 52.25 |
| 9 | 7/9/2016 | Beach | 134 | 95 | 80 | 126.0 | 0.25 | 229 | 57.25 |
| 10 | 7/10/2016 | Beach | 140 | 98 | 82 | 131.0 | 0.25 | 238 | 59.50 |
| 11 | 7/11/2016 | Beach | 162 | 120 | 83 | 135.0 | 0.25 | 282 | 70.50 |
| 14 | 7/14/2016 | Beach | 122 | 85 | 78 | 113.0 | 0.25 | 207 | 51.75 |
| 15 | 7/15/2016 | Beach | 98 | 62 | 75 | 108.0 | 0.50 | 160 | 80.00 |
| 17 | 7/17/2016 | Beach | 115 | 76 | 77 | 126.0 | 0.50 | 191 | 95.50 |
| 18 | 7/18/2016 | Park | 131 | 92 | 81 | 122.0 | 0.50 | 223 | 111.50 |
| 19 | 7/19/2016 | Park | 122 | 85 | 78 | 113.0 | 0.50 | 207 | 103.50 |
| 22 | 7/22/2016 | Park | 112 | 75 | 80 | 108.0 | 0.50 | 187 | 93.50 |
| 23 | 7/23/2016 | Park | 120 | 82 | 81 | 117.0 | 0.50 | 202 | 101.00 |
| 24 | 7/24/2016 | Park | 121 | 82 | 82 | 117.0 | 0.50 | 203 | 101.50 |
| 25 | 7/25/2016 | Park | 156 | 113 | 84 | 135.0 | 0.50 | 269 | 134.50 |
| 26 | 7/26/2016 | Park | 176 | 129 | 83 | 158.0 | 0.35 | 305 | 106.75 |
<script>
const buttonEl =
document.querySelector('#df-080b31c4-9d87-4d46-a98d-5d6eec44b68f button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-080b31c4-9d87-4d46-a98d-5d6eec44b68f');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
iloc vs loc
- 차이를 확인한다!
1 | juice.head(3) |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 7/1/2016 | Park | 97 | 67 | 70 | 90.0 | 0.25 | 164 | 41.00 |
| 1 | 7/2/2016 | Park | 98 | 67 | 72 | 90.0 | 0.25 | 165 | 41.25 |
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 | 187 | 46.75 |
<script>
const buttonEl =
document.querySelector('#df-dadb1a11-c681-42a1-9b8b-85510d760ea0 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-dadb1a11-c681-42a1-9b8b-85510d760ea0');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
%%time
- 실행 시간 측정
- 코드의 효율을 살펴보자
1 | %%time |
CPU times: user 2.14 ms, sys: 0 ns, total: 2.14 ms
Wall time: 3.19 ms
| Date | Location | |
|---|---|---|
| 0 | 7/1/2016 | Park |
| 1 | 7/2/2016 | Park |
| 2 | 7/3/2016 | Park |
<script>
const buttonEl =
document.querySelector('#df-dfd7fd78-f2b8-491f-a422-bd0e37bc0297 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-dfd7fd78-f2b8-491f-a422-bd0e37bc0297');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
- loc
- -> 라벨 기반
1 | %%time |
CPU times: user 1.64 ms, sys: 0 ns, total: 1.64 ms
Wall time: 1.62 ms
| Date | Location | |
|---|---|---|
| 0 | 7/1/2016 | Park |
| 1 | 7/2/2016 | Park |
| 2 | 7/3/2016 | Park |
<script>
const buttonEl =
document.querySelector('#df-f63e27df-425e-4e52-acd7-6c213c3c886a button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-f63e27df-425e-4e52-acd7-6c213c3c886a');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | # juice[juice['Leaflets'] >= 100, 컬럼명 별도 추출] |
| Date | Location | |
|---|---|---|
| 2 | 7/3/2016 | Park |
| 4 | 7/5/2016 | Beach |
| 7 | 7/7/2016 | Beach |
| 8 | NaN | Beach |
| 9 | 7/9/2016 | Beach |
| 10 | 7/10/2016 | Beach |
| 11 | 7/11/2016 | Beach |
| 14 | 7/14/2016 | Beach |
| 15 | 7/15/2016 | Beach |
| 17 | 7/17/2016 | Beach |
| 18 | 7/18/2016 | Park |
| 19 | 7/19/2016 | Park |
| 22 | 7/22/2016 | Park |
| 23 | 7/23/2016 | Park |
| 24 | 7/24/2016 | Park |
| 25 | 7/25/2016 | Park |
| 26 | 7/26/2016 | Park |
<script>
const buttonEl =
document.querySelector('#df-80c7ea4c-f3b6-416c-90a6-935ca4d10c87 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-80c7ea4c-f3b6-416c-90a6-935ca4d10c87');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | juice.iloc[juice['Leaflets'] >= 100, 0:2] |
정렬
- sort_values()
1 | # 매출액 순서로 정렬 |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 25 | 7/25/2016 | Park | 156 | 113 | 84 | 135.0 | 0.50 | 269 | 134.50 |
| 18 | 7/18/2016 | Park | 131 | 92 | 81 | 122.0 | 0.50 | 223 | 111.50 |
| 26 | 7/26/2016 | Park | 176 | 129 | 83 | 158.0 | 0.35 | 305 | 106.75 |
<script>
const buttonEl =
document.querySelector('#df-d4ef77c6-8bab-4eae-9f75-40bfaf70f3b7 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-d4ef77c6-8bab-4eae-9f75-40bfaf70f3b7');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | # 2개 이상 기준으로 할 경우, 그룹화하여 정렬됨 |
| Date | Location | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|---|
| 25 | 7/25/2016 | Park | 156 | 113 | 84 | 135.0 | 0.50 | 269 | 134.50 |
| 24 | 7/24/2016 | Park | 121 | 82 | 82 | 117.0 | 0.50 | 203 | 101.50 |
| 18 | 7/18/2016 | Park | 131 | 92 | 81 | 122.0 | 0.50 | 223 | 111.50 |
| 23 | 7/23/2016 | Park | 120 | 82 | 81 | 117.0 | 0.50 | 202 | 101.00 |
| 22 | 7/22/2016 | Park | 112 | 75 | 80 | 108.0 | 0.50 | 187 | 93.50 |
| 19 | 7/19/2016 | Park | 122 | 85 | 78 | 113.0 | 0.50 | 207 | 103.50 |
| 17 | 7/17/2016 | Beach | 115 | 76 | 77 | 126.0 | 0.50 | 191 | 95.50 |
| 21 | 7/21/2016 | Park | 83 | 50 | 77 | 90.0 | 0.50 | 133 | 66.50 |
| 15 | 7/15/2016 | Beach | 98 | 62 | 75 | 108.0 | 0.50 | 160 | 80.00 |
| 16 | 7/16/2016 | Beach | 81 | 50 | 74 | 90.0 | 0.50 | 131 | 65.50 |
| 20 | 7/20/2016 | Park | 71 | 42 | 70 | NaN | 0.50 | 113 | 56.50 |
| 26 | 7/26/2016 | Park | 176 | 129 | 83 | 158.0 | 0.35 | 305 | 106.75 |
| 28 | 7/28/2016 | Park | 96 | 63 | 82 | 90.0 | 0.35 | 159 | 55.65 |
| 30 | 7/30/2016 | Beach | 88 | 57 | 82 | 81.0 | 0.35 | 145 | 50.75 |
| 31 | 7/31/2016 | Beach | 76 | 47 | 82 | 68.0 | 0.35 | 123 | 43.05 |
| 29 | 7/29/2016 | Park | 100 | 66 | 81 | 95.0 | 0.35 | 166 | 58.10 |
| 27 | 7/27/2016 | Park | 104 | 68 | 80 | 99.0 | 0.35 | 172 | 60.20 |
| 12 | 7/12/2016 | Beach | 130 | 95 | 84 | 99.0 | 0.25 | 225 | 56.25 |
| 11 | 7/11/2016 | Beach | 162 | 120 | 83 | 135.0 | 0.25 | 282 | 70.50 |
| 5 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 | 172 | 43.00 |
| 6 | 7/6/2016 | Beach | 103 | 69 | 82 | 90.0 | 0.25 | 172 | 43.00 |
| 8 | NaN | Beach | 123 | 86 | 82 | 113.0 | 0.25 | 209 | 52.25 |
| 10 | 7/10/2016 | Beach | 140 | 98 | 82 | 131.0 | 0.25 | 238 | 59.50 |
| 7 | 7/7/2016 | Beach | 143 | 101 | 81 | 135.0 | 0.25 | 244 | 61.00 |
| 9 | 7/9/2016 | Beach | 134 | 95 | 80 | 126.0 | 0.25 | 229 | 57.25 |
| 4 | 7/5/2016 | Beach | 159 | 118 | 78 | 135.0 | 0.25 | 277 | 69.25 |
| 14 | 7/14/2016 | Beach | 122 | 85 | 78 | 113.0 | 0.25 | 207 | 51.75 |
| 13 | 7/13/2016 | Beach | 109 | 75 | 77 | 99.0 | 0.25 | 184 | 46.00 |
| 3 | 7/4/2016 | Beach | 134 | 99 | 76 | 98.0 | 0.25 | 233 | 58.25 |
| 1 | 7/2/2016 | Park | 98 | 67 | 72 | 90.0 | 0.25 | 165 | 41.25 |
| 2 | 7/3/2016 | Park | 110 | 77 | 71 | 104.0 | 0.25 | 187 | 46.75 |
| 0 | 7/1/2016 | Park | 97 | 67 | 70 | 90.0 | 0.25 | 164 | 41.00 |
<script>
const buttonEl =
document.querySelector('#df-14051fd5-627b-4ebe-ab05-3415f55cc7f3 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-14051fd5-627b-4ebe-ab05-3415f55cc7f3');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
Group by
- R dplyr groupby() %>% summarize()
- -> 데이터 요약 -> 엑셀로 피벗 테이블
1 | # Location 항목을 카운트 |
| Date | Lemon | Orange | Temperature | Leaflets | Price | Sold | Revenue | |
|---|---|---|---|---|---|---|---|---|
| Location | ||||||||
| Beach | 16 | 17 | 17 | 17 | 17 | 17 | 17 | 17 |
| Park | 15 | 15 | 15 | 15 | 14 | 15 | 15 | 15 |
<script>
const buttonEl =
document.querySelector('#df-26afeca1-6bb7-494f-ba2d-92aab015b058 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-26afeca1-6bb7-494f-ba2d-92aab015b058');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | # 집계 함수 |
| max | min | sum | mean | |
|---|---|---|---|---|
| Location | ||||
| Beach | 95.5 | 43.0 | 1002.8 | 58.988235 |
| Park | 134.5 | 41.0 | 1178.2 | 78.546667 |
<script>
const buttonEl =
document.querySelector('#df-650575f1-c764-4097-b860-3fa1b26021c5 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-650575f1-c764-4097-b860-3fa1b26021c5');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1 | # 집계 함수 |
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:4: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
after removing the cwd from sys.path.
| Revenue | Lemon | |||||||
|---|---|---|---|---|---|---|---|---|
| max | min | sum | mean | max | min | sum | mean | |
| Location | ||||||||
| Beach | 95.5 | 43.0 | 1002.8 | 58.988235 | 162 | 76 | 2020 | 118.823529 |
| Park | 134.5 | 41.0 | 1178.2 | 78.546667 | 176 | 71 | 1697 | 113.133333 |
<script>
const buttonEl =
document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
파이썬_기초문법_3
클래스를 만드는 목적!
- 코드의 간결화!
- 코드를 재사용!
- 여러 라이브러리 –> 클래스로 구현이 됨
- list 클래스, str 클래스
- 객체로 사용
- 변수명으로 정의!
- 여러 클래스들이 모여서 하나의 라이브러리가 됨.
- 장고 / 웹개발 / 머신러닝 / 시각화 / 데이터 전처리
1 | class Person: # 클래스 이름 첫문자는 대문자로 설정 |
kim은 korean
Lee은 korean
instance 메서드 생성
- list.append(), list.extend()
1 | class Person: |
kim은 korean
Lee는 korean
Kim판매량 10된 A을 노래합니다.
lee판매량 200된 B을 노래합니다.
1 | name = "lee" |
lee B을 노래합니다.
클래스 상속
- 부모님 유산…
- 부모님 집 (냉장고, 세탁기, TV, etc)
- 사용은 같이 함
- 본인, 돈을 모음
- 개인 노트북 구매 ( 여러분 각자 방에 비치 )
- 노트분은 본인 것이지만 추가 가전 제품을 구매해서 확장!
1 | class Parent: |
1 | class Parent: |
Child Class is ON
kim 현재 춤을 춥니다.
kim된 연애을 노래합니다.
I am Fast Runner
None
I am child
I am Parent!!
1 | class TV: |
selling Price : 500
selling Price : 500
selling Price : 1000
자식 클래스가 많이 있는 라이브러리는 사용자가 스기 까다로울 것 같은데, 많이 써주는 이유는 자식클래스 이름마다 의미를 주려고 그런건가요?
- 특수 목적을 해결하기 위해서 라이브러리를 만듦
- 초기 버전은 3개 클래스 정도 만들면 해결이 되겠지?
- 버그 나오고, 이슈 터지고 –> 개발자들이 해결
- 2개 더 만들고 다시 배포
클래스 내부에 조건문
- init contsructor에 조건문을 써보자!
1 | class Employee: |
급여는 0원이 될 수 없습니다. 다시 입력해십시오!!
Evan
0
1500
4500
642.8571428571429
클래스 Doctring
- 문서화
- 문서화의 일반적인 과정
1 | class Person: |
My name is Evan. i am 20 years old.나의 직장은 00이야
Help on class Person in module __main__:
class Person(builtins.object)
| Person(name, age)
|
| 사람을 표현하는 클래스
| ...
|
| Attributes
| ----------
| name : str
| name of the person
|
| age : int
| age of the person
| ...
| ...
|
| Methods
| ----------
|
| info(additional=""):
| prints the person's name and age
|
| Methods defined here:
|
| __init__(self, name, age)
| Constructs all the neccessary attributes for the person object
|
| Parameters
| ----------
| name : str
| name of the person
|
| age : int
| age of the person
|
| info(self, additional=None)
| 귀찮음...
|
| Parameters
| ----------
| additional : str, optional
| more info to be displayed (Default is None)
|
| Returns
| -------
| None
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| person = <__main__.Person object>
클래스 실습
1 | # 더하기, 빼기 기능이 있는 클래스 |
3
7
3
10
1 | # 4칙연산 기능이 달린 클래스 정의 |
6
1 | # 4칙연산 기능이 달린 클래스 정의 |
8
2
2.0
생성자
- 위 함수의 setdata는 생성자의 역할을 한다.
- setdata를 생성자 __init__으로 바꿔도 정상 작동한다.
1 | # setdata를 생성자 __init__으로 변경 |
8
2
2.0
클래스의 상속
- FourCal 클래스는 만들어 놓았으므로 FourCal 클래스를 상속하는 MoreFourCal 클래스는 다음과 같이 간단하게 만들 수 있다.
1 | # 상속 |
6
python_numpy_01
라이브러리
- 여러가지 라이브러리를 사용해보자
Numpy
Q : what is numpy?
A : 배열 연산이다.
Q : why numpy?
A : 두개의 리스트 연산 시도 → Type Error → Numpy 도입
1 | # 다음 코드는 사용 시 error가 나온다. |
1 | # numpy 사용 시 정상적으로 작동한다. |
array([0.0625 , 0.08 , 0.08333333])
Reshape
사용 예시
- (2,3) 배열 -> np.reshape(3,2) -> (3,2)배열
사용 예시
- np.reshape(-1, 2)에서 -1의 의미
: 특정 차원에서 열은 2로 고정된 상태에서 행은 사이즈에 맞도록 자동으로 정렬해준다는 뜻
1 | import numpy as np |
array([[ 1, 2, 3, 4, 5, 6, 7, 8],
[ 9, 10, 11, 12, 13, 14, 15, 16]])
1 | # -1을 이용한 자동 정렬 |
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
조언
- 머신러닝 / 딥러닝
- 수학을 잘 하는 사람 vs 수학을 처음 하는 사람
- 머신러닝 / 딥러닝 (인간이 만든 수식!)
- 개념을 이해하고, 수식으로 이해하고, 코드로 그 수식을 구현해야
- 머신러닝과 딥러닝을 쓰기 위해서는 수학자만 해야되냐!?
- 결론은 아닙니다!
- 머신러닝 / 딥러닝의 주 목적이 인간 생활의 보편적인 무제 해결을 위해 나온 것
- 프레임워크로 형태로 내놨어요 (개념을 이해하고 있자!)
- 개념만 문자열 타입으로 매개변수를 잘 조정만 하면 모델 만들어짐!
- 성과를 내야 하는데 (개발자는 배포를 잘해야 함!)
- 이미지 인식 모델을 만듬 / (쓸데가 없음…) / 안드로이드 앱 / 웹앱에 탑재할줄만 알아도
- 기획 (어떤 문데를 풀까?)
- AutoML
- 코드를 4 ~ 5줄 치면 머신러닝 모델이 만들어짐!
- 하지만 이공계 출신이라면 수식도 나름대로 정리해 볼 것
라이브러리 설치 방법 (vs R)
1 | # R install.packages("패키지명") |
Numpy 라이브 불러오기
1 | # 다음과 같이 np 라고 줄여서 출력한다. |
1.21.5
배열로 변환
- 1부터 10까지의 리스트를 만든다.
- Numpy 배열로 변환해서 저장한다.
1 | temp = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
[ 1 2 3 4 5 6 7 8 9 10]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
1 | print(type(arr)) |
<class 'numpy.ndarray'>
<class 'list'>
- Numpy를 사용하여 기초 통계 함수를 사용한다.
1 | print(np.mean(arr)) |
5.5
55
5.5
2.8722813232690143
사칙연산
1 | math_scores = [90,80, 88] |
[90, 80, 88, 80, 70, 90]
1 | math_scores = [90,80, 88] |
array([170, 150, 178])
1 | np.min(total_scores) |
150
1 | np.max(total_scores) |
178
1 | math_scores = [2, 3, 4] |
덧셈 : [3 5 7]
뺄셈 : [1 1 1]
곱셈 : [ 2 6 12]
나눗셈 : [2. 1.5 1.33333333]
거듭제곱 : [ 2 9 64]
배열의 생성
- 0차원부터 3차원까지 생성하는 방법
1 | temp_arr = np.array(20) |
20
<class 'numpy.ndarray'>
()
1 | # 1차원 배열 |
[1 2 3]
<class 'numpy.ndarray'>
(3,)
1
1 | # 2차원 배열 |
[[1 2 3]
[4 5 6]]
<class 'numpy.ndarray'>
(2, 3)
2
1 | # 3차원 배열 |
[[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]]
<class 'numpy.ndarray'>
(2, 2, 3)
3
1 | temp_arr = np.array([1, 2, 3, 4], ndmin = 2) # 차원을 변경 가능 |
[[1 2 3 4]]
<class 'numpy.ndarray'>
(1, 4)
2
소수점 정렬
1 | temp_arr = np.trunc([-1.23, 1.23]) |
array([-1., 1.])
1 | temp_arr = np.fix([-1.23, 1.23]) |
array([-1., 1.])
1 | # 반올림 |
array([-1.6379, 1.2378])
1 | # 올림 |
array([-2., 1.])
1 | # 내림 |
array([-1., 2.])
- shape 높이 * 세로 * 가로 순인건가요?
- axis 축 설정
배열을 사용하는 다양한 방법들
1 | # np.arange(5) -> 0 부터 시작하는 5개의 배열 생성 |
array([0, 1, 2, 3, 4])
1 | # np.arange(1, 11, 3) -> 1 부터 11까지 3만큼 차이나게 배열 생성 |
array([ 1, 4, 7, 10])
1 | # np.zeros -> 0으로 채운 배열 만들기 |
[[0. 0. 0.]
[0. 0. 0.]]
<class 'numpy.ndarray'>
(2, 3)
2
float64
1 | # np.ones -> 1로 채운 배열 만들기 |
[[1 1 1 1 1]
[1 1 1 1 1]
[1 1 1 1 1]
[1 1 1 1 1]]
<class 'numpy.ndarray'>
(4, 5)
2
int32
1 | temp_arr = np.ones((2,6), dtype="int32") |
[[1 1 1 1 1 1]
[1 1 1 1 1 1]]
<class 'numpy.ndarray'>
(2, 6)
2
int32
1 | # reshape() 사용하여 배열 변환하기 |
[[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]]
<class 'numpy.ndarray'>
(4, 36)
2
int32
numpy 조건식
- where(a, b, c) 사용법
- a조건 True면 b로 변환, False이면 c로 변환
1 | temp_arr = np.arange(10) |
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
1 | # 5보다 작은 값은 원래값으로 변환 |
array([ 0, 1, 2, 3, 4, 50, 60, 70, 80, 90])
1 | # 0~100 까지의 배열 만들고, 50보다 작은 값은 곱하기 10, 나머지는 그냥 원래 값으로 반환 |
array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120,
130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240, 250,
260, 270, 280, 290, 300, 310, 320, 330, 340, 350, 360, 370, 380,
390, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100])
두가지 조건식을 사용해야 할 경우
- np.select
- 사용법은 다음 코드를 참고
1 | temp_arr = np.arange(10) |
array([100, 101, 2, 3, 4, 5, 12, 14, 16, 18])
브로드캐스팅
- 서로 다른 크기의 배열을 계산할 때 참고해야하는 내용이다.
Github Blog
깃허브 블로그
-IT 프로그래밍 관련
—> 소스 코드 / 결과 / 이미지
신입은 포폴 x
경력 이직 —> 직장에서 했던 프로젝트
—> 신기술을 써봤냐? 안 써봤냐? —> 깃허브로 증명 가능
깃 설치 이후에 다음 내용 진행.
구글링 : nodejs → LTS 버전 다운로드 → 경로 중 add path?에 놓는다.
→ ‘atuomatically install….’ 을 체크 → install
→ 바탕화면 —> 우클릭 → git bash here → node -v 입력 후 enter → v16.14.1 출력되면 성공
*컴퓨터 내에서 검색 : 자격 증명 → 자격 증명 관리자 → window 자격 증명’ 확인하기
*다음 링크 참조
https://dschloe.github.io/settings/hexo_blog/
바탕화면 우클릭 → git bash here
→ 다음을 복사 npm install -g hexo-cli
→ git bash here 에 Shift + insert 하여 붙여넣고 enter
→ (위 링크에 있는 몇몇 과정은 설명을 생략했다고 하심)
→ (~desktop 위치에서) hexo init myblog ### 다시 할 때는 여기부터
→ 바탕화면에 myblog 폴더가 생성되면 성공
→ myblog에 우클릭 후 ‘Open Folder as PyCharm Community…’ 클릭
→ 파이참 하단에 Terminal 클릭 → 옆에 화살표 눌러서 gitbash 켜기
→ hexo server 입력
→ 링크 클릭
→ 블로그 입장 성공
깃허브
→ 로그인
→ 우측상단 프로필 옆 클릭 → your repository → new
→ repository name에 myblog 입력 ( hexo init 명령에서 만든 폴더와 같아야 함 )
→ create repository
→ 파이참으로 이동
→echo "# myblog" >> [README.md](http://README.md)
→git init
→git add README.md
→git commit -m "first commit"
→ unable to auto-detect… 에러 발생 시 다음 입력
→ git config –global user.email “alsrbs0219@gmail.com”
→ git config –global user.name “kmk3593”
→ 다시 git commit -m "first commit"
→ git branch -M main
→ git remote add origin https://github.com/kmk3593/myblog.git
→ git push -u origin main ##깃허브에서 복붙으로 편하게 진행 가능
git add 파일명# ⇒ 해당 파일명을 내가 올리겠다.
git add .# ⇒ 모든 파일 올리겠다(띄어쓰기 주의)
git commint -m “updated”
git push # 최종 단계: 모든 파일을 깃허브(사이트)에 올려라
세팅 끝나면 다음 세 가지만 쓰면 된다.
git add README.md # 단, README 는 그때 그때 다르게 쓴다.
git commit -m "first commit" #단, first commit 은 그때 그때 다르게 쓴다.
git push -u origin main
ex) git add .
git commit -m "first commit"
git push
hexo server
→ 링크타고 이동
→ 파이참 왼쪽 목록에서 mblog → source → post → hello world 열기
→ 내용 써보기 #첫번째글 안녕하세요
→ 깃허브에서 source/_post를 클릭 → hello world .md 클릭 // 안녕하세요가 반영 안 되어있다. 반영해보자.
→git add . (파이참에서 실행)
git commit -m "update"
git push
→ 이제 깃허브를 다시 확인 → ‘안녕하세요’가 적혀있다면 성공
→ 다음을 입력하여 설치 (단, mblog 위치에서 해야 함 = cd mblog )
1 | $ npm install |
→ 파이참 왼쪽 목록에서 mblog → config.yml 열기
→ #URL 부분에 [https://kmk3593.github.io](https://kmk3593.github.io) 입력
→ config 맨 하단에 #Deployment 에서 다음과 같이 입력
1 | deploy: |
→ kmk3593.github.io 복사해서 → 깃허브 your repository → new에서 repository name에 붙여넣기
→ 생성
→ 파이참에서 hexo generate
→ hexo deploy
→ INFO Deploy INFO : git 이 출력되면 배포 성공. # 오류나면 npm install 3개를 다시 진행
→ 깃허브 새로고침
→ 깃허브에서 active 상태될 때까지 기다린다.
→ ****kmk3593.github.io를 복사해서 주소창에 입력**
→ 배포가 완료됬음을 확인 할 수 있다.
파이참
→ hexo new “MY New Post” # 새 파일 만들기
→ hexo server # 반영됬는지 링크타고 확인하자.
→ hexo generate --deploy # 배포 한 줄로 하기
→ 왠지 모르게 반영이 안된다. 일단 넘어가자.
테마 (이카루스)
https://ppoffice.github.io/hexo-theme-icarus/uncategorized/getting-started-with-icarus/#install-npm
링크 들어가서
→ 다음을 파이참에 붙여넣어 설치
→ npm install -S hexo-theme-icarus
→ hexo config theme icarus
→ config.yml이 변경되었음을 알 수 있다.
→ hexo server
→ 만약 에러 나오면) npm install --save bulma-stylus@0.8.0 hexo-renderer-inferno@^0.1.3
→ 만약 에러 나왔다면) 다시 hexo server
→ 나오는 링크타고 이동 → 제대로 페이지가 출력되면 성공
→ hexo clean ( 청소하기 )
→ hexo generate --deploy #배포 재시도
→ 링크 들어가서 확인
재확인하기
파일 내용 막 써보고
→ hexo server → 링크 들어가서 확인
→ hexo generate --deploy
→ ****kmk3593.github.io 들어가서 확인**
주의사항
- 데이터셋 or 파일크기 —> 50MB 이상은 깃허브에 올리면 안 됨
—> 못 올리나요? 추가적인 설정이 필요.
- 깃허브 상에 파일 편집 금지!! →> 아예 마우스로 건드리지 마시오
반영이 잘 안된다면
구글링 : github status 확인
R MarkDown 올리기
참고 : Hexo Blog 이미지 추가 - Data Science | DSChloe
temp프로젝트
→ R MakrDown → 저장 → knit 실행 → 저장한이름.html 생성됨
→ 다음과 같이 작성
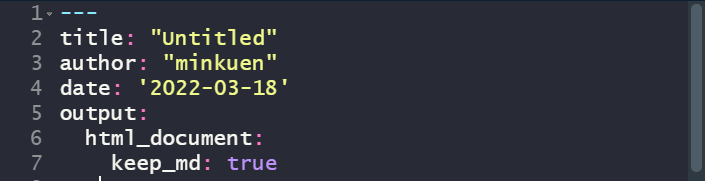
→ knit 실행 → 저장한 이름.md 생성됨
→ 다음과 같이 md 파일을 복사하여 다음 경로에 붙여넣기
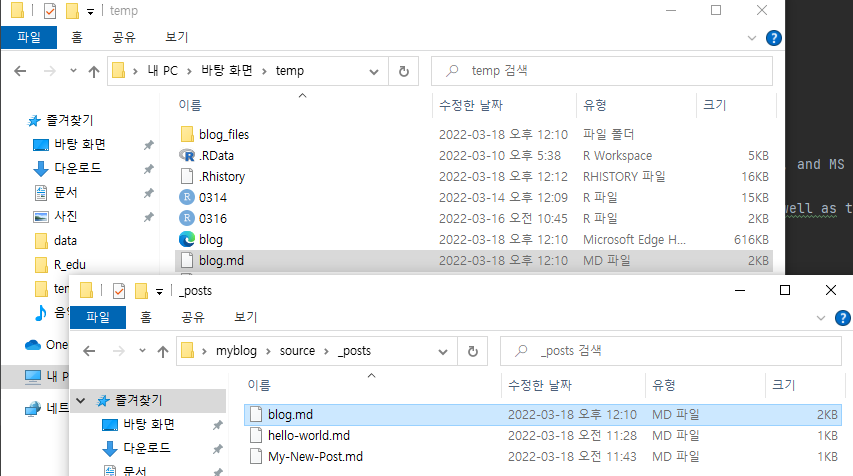
→ 파이참에 md 파일이 생성된다.
→ hexo server 하여 링크로 들어가 반영여부를 확인
→ 다음 경로에 images파일을 만들고 다음과 같이 blog_files를 복사하여 그 안에 넣는다.
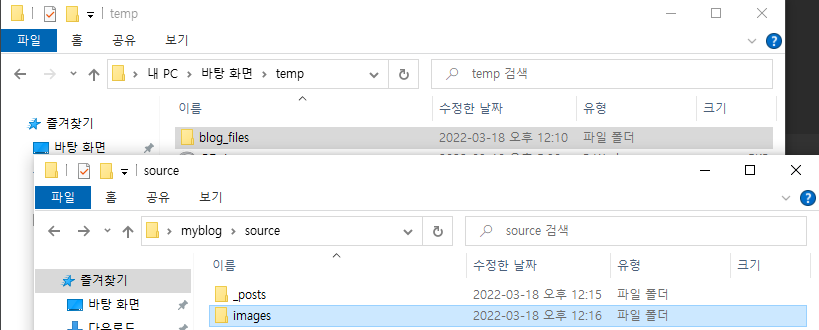
→ 파이참의 md파일에 /images/를 덧붙여서 다음과 같이 작성한다. *( ctrl+ R 로 하면 편리 )

→ hexo server 하여 링크로 확인.
→ 이미지가 추가되었다면 성공.
*’블로그 이름’폴더 → source → images 폴더 생성 → images안에 ‘블로그 이름’_files를 넣는게 핵심
[깃허브 블로그 실습]
이전에 과제로 작성한 R MarkDown파일인 stat_01을 깃허브에 올려보자.
→ 이미지가 없어서 그러지 images에 넣을 _files 폴더가 생성되지 않았다.
→ 배포까지 완료했다.
→ 성공
노션 올리기
노션
→ 올릴 페이지 선정
→ 다음 그림과 같이 우측 상단의 ººº 을 선택

→ 내보내기 → Markdown & CSV 선택 → 내보내기
→ 압축파일이 다운로드됨 → 압축해제 → 폴더 이름 재정의
→ Markdown 올리기와 똑같이 파일을 source와 images에 복사 붙여넣기한다.
→ 파이참에 md파일이 생겼을 것이다.
→ 맨 위에 세팅 부분이 없을 건데, 다음과 같은 형식으로 작성해준다.

→ 이미지링크를 수정해야한다 → 링크 복사 → images에 있는 해당 폴더를 우클릭
→ copy path/reference → Path From Repository Root
→ 다음과 같이 앞부분을 /images/파일명/ 으로 변경해야 한다.

→ hexo server 하여 반영되었는지 확인
→ hexo generate --deploy 하여 배포
파이썬 올리기
크롬 브라우저
→ 구글 검색 : google colab
→ 파일 → 다운로드 → ipynb 다운로드
→ 다운로드한 파일을 바탕화면으로 옮기고 colab_intro로 이름 변경
→ anaconda navigator 관리자 권한으로 켜기
→ JupyterLab
→ 이전에 다운받은 colab_intro 클릭
→ file → Save and Export Notebook As → Markdown
→ 파일이 다운된다. → 바탕화면으로 옮기고 압축 해제
→ markdown 때와 같이 폴더를 복사 붙여넣기
→ 파이참에서 md 파일 확인
→ 맨 위에 세팅 부분이 없을 건데, 다음과 같은 형식으로 작성해준다.

→ 이미지링크를 수정해야한다 → 링크 복사 → images에 있는 해당 폴더를 우클릭
→ copy path/reference → Path From Repository Root
→ 다음과 같이 앞부분을 /images/경로/파일명/ 으로 변경해야 한다.

→ hexo server 하여 반영되었는지 확인
→ hexo generate --deploy 하여 배포
태그 카테고리
hexo 블로그를 꾸며보자!! 카테고리 작업을 해보자!! — SteemCoinPan
-다음과 같이 tags와 categories를 써넣어라
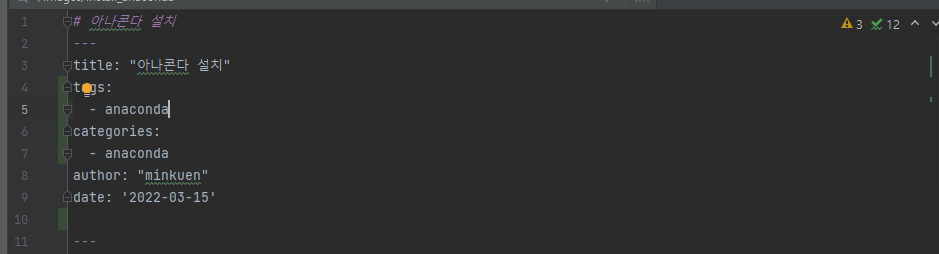
구글링 : hexo multiple categories
팁
-깃허브 프로젝트 주소
-깃허브 블로그 주소
이 2가지는 회사에 자기 PR 할 때는 발표자료에 적어야 한다.
그러니 반드시 배포까지 완료해야 한다.
파이썬_기초문법_2
기초 문법 리뷰
1 | # 리스트 |
조건문 & 반복문
1 | if True: |
1 | for idx in range(3): |
1 안녕하세요
2 안녕하세요
3 안녕하세요
1 | book_list = ["프로그래밍 R", "혼자 공부하는 머신러닝"] |
프로그래밍 R
혼자 공부하는 머신러닝
1 | strings01 = "Hello world" |
1 | num_tuple = (1, 2, 3, 4) |
1
2
3
4
1 | num_dict = {"A" : 1, "B" : 2} |
A
1
B
2
반복문의 필요성
1 | product_name = ["요구르트", "우유", "과자"] |
요구르트의 매출액은 5000원이다.
우유의 매출액은 4500원이다.
요구르트의 매출액은 5000원이다.
우유의 매출액은 4500원이다.
과자의 매출액은 8000원이다.
while
- 조건식이 들어간 반복문
(vs for-loop 범위!!!)
1 | count = 1 |
안녕하세요..
안녕하세요..
안녕하세요..
안녕하세요..
5 초과했군요..
1 | count = 3 |
안녕하세요..
2
안녕하세요..
1
안녕하세요..
0
0 미만이군요..
- 개발자를 지향한다!
- while 공부 좀 더 비중 있게 다루는 걸 추천
- 데이터 분석
- for-loop 공부를 좀 더 비중있게 하는 것 추천
사용자 정의 함수 (User-Defined Function)
- why?
클래스(Class)를 왜 쓸까?
- 코드의 반복성을 줄이기 위해서 사용!
len() –> 누군가가 만들었고, 우리는 그걸 그냥 쓰는 것
- 리스트의 길이 구할 때 사용
- 리스트 전체 길이를 구하겠다!? –> 1회성? 나만 쓰는가? no
1 | def 함수명(): |
1 | def add(a, b): |
add(10,5) = 15
minus(10,5) = 5
multiple(10,5) = 50
divide(10,5) = 2.0
1 |
|
jupyter notebook, ipynb 파일명
.py로 저장(PyCharm..)
1 | !which pyhon |
basic.py로 저장할 때, 예시
1 | # /usr/local/bin/python |
Help on function temp in module __main__:
temp(content, letter)
content 안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
content 안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
help()
- 위 코드에서 help()는 본인이 작성한 주석을 바탕으로 문서화한다.
리스트 컴프리헨션
- for-loop 반복문을 한 줄로 처리
- 리스트 안에 반복문을 작성할 수 있다
1 | my_list = [[10], [20,30]] |
[[10], [20, 30]]
[10]
10
[20, 30]
20
30
[10, 20, 30]
1 | my_list = [[10], [20, 30]] |
[10, 20, 30]
1 | letters = [] |
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
1 | letters2 = [char for char in "helloworld"] # 리스트 컴프리헨션 |
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
1 | value_list = [1, 2, 3, 4, 5, 6] |
avg: 3.5
3.5
4
1 | # 사용자 정의함수의 문서화 |
avg : 2.5714285714285716
median 2
- 데코레이터, 변수명 immutable or mutable, context manager는
jump to python 페이지에 없기에 따로 찾아 공부해야 한다.
함수 실습
여러 개의 입력값을 받는 함수
1 | # 여러 개의 입력값을 받는 함수 만들기 |
1 | # 위 함수를 이용해보자 |
6
55
1 | # 여러 개의 입력값을 받는 함수 만들기2 |
1 | # 위 함수를 이용해보자 |
15
120
키워드 파라미터 kwargs
- 키워드 파라미터를 사용할 때는 매개변수 앞에 별 두 개(**)를 붙인다.
1 | # 매개변수 kwargs를 출력하는 함수이다. |
{'a': 1}
{'name': 'foo', 'age': 3}
{'age': 3, 'name': 'foo'}
매개변수에 초깃값 미리 설정하기
1 | def say_myself(name, old, man=True): # boolean 값을 이용하여 설정 |
나의 이름은 박응용 입니다.
나이는 27살입니다.
남자입니다.
나의 이름은 박응용 입니다.
나이는 27살입니다.
남자입니다.
나의 이름은 박응용 입니다.
나이는 27살입니다.
여자입니다.
함수 안에서 선언한 변수의 효력 범위
1 | a = 1 |
1
함수 안에서 함수 밖의 변수를 변경하는 방법
- return 사용하기
- global 사용하기
1 | # return 사용하기 |
2
1 | # global 사용하기 |
2
lambda
- 함수를 생성할 때 사용하는 예약어로 def와 동일한 역할을 한다.
- 보통 함수를 한줄로 간결하게 만들 때 사용
1 | add = lambda a, b : a+b |
7
사용자 입력과 출력
사용자 입력
- input 사용
1 | number1 = input("숫자를 입력하세요... : ") |
숫자를 입력하세요... : 1
1
숫자를 입력하세요... : 4
4
print 자세히 알기
1 | # 큰따옴표로 둘러싸인 문자열은 + 연산과 동일하다 |
lifeistoo short
lifeistoo short
1 | # 문자열 띄어쓰기는 콤마로 한다 |
life is too short
1 | # 한 줄에 결괏값 출력하기 |
0 1 2 3 4 5 6 7 8 9
파일 생성하기
- 파일 열기 모드에는 다음과 같은 것이 있다.
- r : 읽기모드 - 파일을 읽기만 할 때 사용
- w : 쓰기모드 - 파일에 내용을 쓸 때 사용
- a : 추가모드 - 파일의 마지막에 새로운 내용을 추가 시킬 때 사용
1 | f = open("새파일.txt", 'w') |
1 | # 만약 새파일.txt 파일을 C:/doit 디렉터리에 생성하고 싶다면 다음과 같이 작성 |
1 | # 파일을 쓰기 모드로 열어 출력값 적기 |
1 | # 파일에 새로운 내용 추가하기 |
4장 연습문제
1 | # Q1 주어진 자연수가 홀수인지 짝수인지 판별해 주는 함수(is_odd)를 작성해 보자. |
자연수를 입력하세요...: 3
홀수입니다...
1 | # Q2 입력으로 들어오는 모든 수의 평균 값을 계산해 주는 함수를 작성해 보자. |
5.5
1 | # Q3 다음은 두 개의 숫자를 입력받아 더하여 돌려주는 프로그램이다. |
첫번째 숫자를 입력하세요:1
두번째 숫자를 입력하세요:4
두 수의 합은 5 입니다
1 | # Q4 다음 중 출력 결과가 다른 것 한 개를 골라 보자. |
youneedpython
youneedpython
you need python
youneedpython
1 | # Q5 다음은 "test.txt"라는 파일에 "Life is too short" 문자열을 저장한 후 다시 그 파일을 읽어서 출력하는 프로그램이다. |
Life is too short
1 | # Q6 사용자의 입력을 파일(test.txt)에 저장하는 프로그램을 작성해 보자. |
저장할 내용을 입력하세요:hihi
1 | # Q7 다음과 같은 내용을 지닌 파일 test.txt가 있다. 이 파일의 내용 중 "java"라는 문자열을 "python"으로 바꾸어서 저장해 보자. |
파이썬_기초문법_1
Hello world
1 | print("Hello, World") |
Hello, World
주석 처리
- 코드 작업 시, 특정 코드에 대해 설명
- 사용자 정의 함수 작성 시, 클래스 작성시.. (도움말 작성..)
1 | # 한 줄 주석 처리 |
Hello, World!
변수 (Scalar)
- 객체(Object)로 구현이 됨
- 하나의 자료형(Type)을 가진다.
- 클래스로 정의가 됨.
- 다양한 함수들이 존재 함.
int
- init 정수를 표현하는데 사용함.
1 | #데이터 전처리.. |
1
3
<class 'int'>
float
- 실수를 표현하는데 사용한다.
1 | num_float = 0.2 |
0.2
<class 'float'>
1 | ## bool |
1 | bool_true = True |
True
<class 'bool'>
None
- Null을 나타내는 자료형으로 None이라는 한 가지 값만 가집니다.
1 | none_x = None |
None
<class 'NoneType'>
사칙연산
- 정수형 사칙 연산
1 | a = 10 |
a + b = 15
a - b = 5
a * b = 50
a / b = 2.0
a // b = 2
a % b = 0
a ** b = 100000
실수형 사칙연산
1 | a = 10.0 |
a + b = 15.0
a - b = 5.0
a * b = 50.0
a / b = 2.0
a // b = 2.0
a % b = 0.0
a ** b = 100000.0
논리형 연산자
- Bool 형은 True와 False 값으로 정의
- AND / OR
1 | x = 5 > 4 # True |
비교 연산자
- 부등호를 의미합니다.
- 비교 연산자를 True와 False값을 도출
논리 & 비교 연산자 응용
1 | var = input("입력해주세요....") |
입력해주세요....1
<class 'str'>
- 형변환을 해준다.
- 문자열, 정수, 실수 등등등
1 | var = int("1") # 형변환 |
<class 'int'>
1 | var = int(input("숫자를 입력하여 주세요 : ")) # 형변환 |
숫자를 입력하여 주세요 : 1
<class 'int'>
1 | num1 = int(input("숫자를 입력하여 주세요... : ")) # 10 |
숫자를 입력하여 주세요... : 10
숫자를 입력하여 주세요... : 3
숫자를 입력하여 주세요... : 5
숫자를 입력하여 주세요... : 7
True
True
변수 ( Non Scalar)
- 문자열을 입력
1 | print("'Hello, world'") |
'Hello, world'
"Hello, world"
String 연산자
- 덧셈 연산자를 써보자.
1 | str1 = "Hello " |
Hello World!
- 곱셈 연산자를 사용해본다.
1 | greeting = str1 + str2 + str3 |
Hello World!
Hello World!
Hello World!
indexing
- 문자열 인덱싱은 각각의 문자열 안에서 범위를 지정하여 특정 문자를 추출한다.
1 | greeting = "Hello kaggle!" |
k
슬라이싱
- 범위를 지정하고 데이터를 가져온다.
1 | greeting |
Hello kaggle!
kaggle!
Hello
lo kag
Hlokg
리스트
- 시퀀스 데이터 타입
- 데이터에 순서가 존재하냐! 슬라이실이 가능해야 함.
- 대관호 ([‘값1’, ‘값2’, ‘값3’])
1 | a = [] # 빈 리스트 |
[]
[]
[1]
['apple']
[1, 2, ['apple']]
리스트 슬라이싱
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
1
[7, 8, 9, 10]
[1, 2, 3, 4, 5]
[4, 5]
[2, 4, 6, 8]
1 | a = [["apple", "banana", "cherry"], 1] |
['apple', 'banana', 'cherry']
cherry
e
e
e
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[1, 3, 5, 7, 9]
1 | ## 리스트 연산자 |
['john', 'evan', 'alice', 'eva']
1 | c = a * 3 |
a * 3 = ['john', 'evan', 'john', 'evan', 'john', 'evan']
b * 0 = []
리스트 수정 및 삭제
1 | a = [0, 1, 2] |
[0, 'b', 2]
리스트 값 추가하기
1 | a = [100, 200, 300] |
[100, 200, 300, 400]
[100, 200, 300, 400, [500, 600]]
[100, 200, 300, 400, [500, 600], 500, 600]
1 | a = [0, 1, 2] |
[0, 100, 1, 2]
리스트 값 삭제하기
1 | a = [4, 3, 2, 1, "A"] |
[4, 3, 2, 'A']
[4, 3, 2]
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
[1, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 7, 8, 9, 10]
1 | b = ["a", "b", "c", "d"] |
d
['a', 'b', 'c']
그 외 메서드
1 | a = [0, 1, 2, 3] |
[0, 1, 2, 3]
[]
1 | a = ["a", "a", "b", "b"] |
0
2
1 | a = [1, 4, 5, 2, 3] |
sort() : [1, 2, 3, 4, 5]
sort(reverse=True) : [5, 4, 3, 2, 1]
튜플
- List와 비슷하다.
- 슬라이싱, 인덱싱 등등
- (vs 리스트) : 튜플은 수정 삭제가 안된다.
1 | tuple1 = (0) # 끝에 코마(,)를 붙이지 않을 때 |
<class 'int'>
<class 'tuple'>
<class 'tuple'>
1 | a = (0, 1, 2, 3, 'a') |
<class 'tuple'>
(0, 1, 2, 3, 'a')
(5, 'b', 3, 2, 1)
튜플 인덱싱 및 슬라이싱 하기
1 | a = (0, 1, 2, 3, 'a') |
1
2
a
더하기 곱셈 연산자 사용
1 | t1 = (1, 2, 3) |
(1, 2, 3, 4, 5, 6)
(1, 2, 3, 1, 2, 3, 1, 2, 3)
()
딕셔너리
- key & value 값으로 나뉨.
1 | dict_01 = {'teacher' : 'evan', |
evan
601
['A', 'Z']
1 | print(dict_01.keys()) |
dict_keys(['teacher', 'class', 'students', '학생이름'])
['teacher', 'class', 'students', '학생이름']
1 | print(dict_01.values()) |
dict_values(['evan', 601, 24, ['A', 'Z']])
1 | dict_01.items() |
dict_items([('teacher', 'evan'), ('class', 601), ('students', 24), ('학생이름', ['A', 'Z'])])
1 | print(dict_01.get("teacher")) # get 메소드 |
evan
값 없음
601
24
조건문 & 반복분
- 일상에서 조건문 언제쓸까요?
1 | # 날씨가 맑다 --> 우산을 안 책겨간다 |
우산을 가져가지 않는다
1 | # 등급표 만들기 |
합격입니다.
1 | grade = int(input("숫자를 입력하여 주세요... : ")) |
숫자를 입력하여 주세요... : 10
불합격입니다.
1 | # 90점 이상은 A등급 |
숫자를 입력하여 주세요... : 85
B 등급입니다.
반복문
for문
1 | # 안녕하세요! 5번 반복하라 |
1 안녕하세요
2 안녕하세요
3 안녕하세요
4 안녕하세요
5 안녕하세요
1 | count = range(5) |
range(0, 5)
1번째
축구 슈팅
2번째
축구 슈팅
3번째
그만합니다
1 | a = "hello" |
h
e
while문
반복해서 문장을 수행해야 할 경우 while문을 사용한다.
1 | #열 번 찍어 안 넘어가는 나무 없다" |
나무를 1번 찍었습니다.
나무를 2번 찍었습니다.
나무를 3번 찍었습니다.
나무를 4번 찍었습니다.
나무를 5번 찍었습니다.
나무를 6번 찍었습니다.
나무를 7번 찍었습니다.
나무를 8번 찍었습니다.
나무를 9번 찍었습니다.
나무를 10번 찍었습니다.
나무 넘어갑니다.
1 | # while문 만들기 |
1 | number = 0 |
1.Add
2.Del
3.List
4.Quit
Enter number:
4
1 | # 커피 자판기 이야기 |
while문의 맨 처음으로 돌아가기 (continue)
1 | a = 0 |
1
3
5
7
9
무한 루프
1 | while True : |
문자열 포매팅
- 문자열 안의 특정한 값을 바꿔야 할 경우가 있을 때 이것을 가능하게 해주는 것이 바로 문자열 포매팅 기법이다.
- 숫자는 %d, 문자는 %s
1 | # 숫자 바로 대입 |
'I eat 3 apple.'
1 | # 문자열 바로 대입 |
'I eat five apples.'
1 | # 숫자 값을 나타내는 변수로 대입 |
'I eat 3 apples.'
1 | # 2개 이상의 값 넣기 |
'I ate 10 apples. so I was sick for three day'
1 | "I have %s apples" % 3 |
'rate is 3.234 '
format 함수를 사용한 포매팅
- 문자열의 format 함수를 사용하면 좀 더 발전된 스타일로 문자열 포맷을 지정할 수 있다.
1 | # 숫자 바로 대입하기 |
'I eat 3 apples'
1 | # 문자 바로 대입하기 |
'I eat five apples'
1 | # 숫자 값을 가진 변수로 대입하기 |
'I eat 3 apples'
1 | # 2개 이상의 값 넣기 |
'I ate 10 apples. so I was sick for three days. '
1 | # 이름으로 넣기 |
'I ate 10 apples. so I was sick for 3 days.'
1 | # 인덱스와 이름을 혼용해서 넣기 |
'I ate 10 apples. so I was sick for 3 days.'
1 | # 왼쪽 정렬 |
'hi '
1 | # 오른쪽 정렬 |
' hi'
1 | # 가운데 정렬 |
' hi '
1 | # 공백 채우기 |
'hi!!!!!!!!'
1 | # 소수점 표현하기 |
'3.4213'
1 | # 정렬과 소수점 표현 |
' 3.4213'
1 | # { 또는 } 문자 표현하기 |
'{ and }'
f 문자열 포매팅
- 파이썬 3.6 버전부터는 f 문자열 포매팅 기능을 사용할 수 있다.
- f 문자열 포매팅은 표현식을 지원한다.
- 표현식이란 문자열 안에서 변수와 +, -와 같은 수식을 함께 사용하는 것을 말한다.
1 | name = '홍길동' |
'나의 이름은 홍길동입니다. 나이는 30입니다.'
1 | age = 30 |
'나는 내년이면 31살이 된다.'
1 | # f 문자열 포매팅에서의 딕셔너리 |
'나의 이름은 홍길동입니다. 나이는 30입니다.'
1 | # f 문자열에서 정렬 |
' hi '
1 | # f 문자열에서 공백채우기 |
'hi!!!!!!!!'
1 | # f 문자열에서 소수점표현 |
' 3.4213'
1 | # f 문자열에서 { } 문자를 표시 |
'{ and }'
문자열 관련 함수들
- 문자열 자료형은 자체적으로 함수를 가지고 있다.
- 이들 함수를 다른 말로 문자열 내장 함수라 한다.
- 이 내장 함수를 사용하려면 문자열 변수 이름 뒤에 ‘.’를 붙인 다음에 함수 이름을 써주면 된다.
1 | # 문자 개수 세기 (count) |
2
1 | # 위치 알려주기1 (find) |
-1
1 | # 위치 알려주기2 (index) |
8
문자열 삽입(join)
1 | ",".join('abcd') |
'a,b,c,d'
1 | # 대문자를 소문자로 바꾸기 |
'hi'
1 | # 왼쪽 공백 지우기 |
'hi '
1 | # 오른쪽 공백 지우기(rstrip) |
' hi'
1 | # 양쪽 공백 지우기(strip) |
'hi'
문자열 바꾸기(replace)
1 | a = "Life is too short" |
'your leg is too short'
문자열 나누기(split)
1 | a = "Life is too short" |
['a', 'b', 'c', 'd']
1 | # |
2장 연습문제
- 파이썬 프로그래밍의 기초, 자료형
1 | # Q1 홍길동 씨의 과목별 점수는 다음과 같다. 홍길동 씨의 평균 점수를 구해 보자. |
70.0
1 | # Q2 자연수 13이 홀수인지 짝수인지 판별할 수 있는 방법에 대해 말해 보자.. |
13은 홀수이다
1 | # Q3 자연수 13이 홀수인지 짝수인지 판별할 수 있는 방법에 대해 말해 보자.. |
881120
1068234
1 | #Q4 주민등록번호에서 성별을 나타내는 숫자를 출력해 보자. |
1
1 | #Q5 다음과 같은 문자열 a:b:c:d가 있다. |
a:b:c:d
1 | #Q6 [1, 3, 5, 4, 2] 리스트를 [5, 4, 3, 2, 1]로 만들어 보자. |
[5, 4, 3, 2, 1]
1 | #Q7 ['Life', 'is', 'too', 'short'] 리스트를 Life is too short 문자열로 만들어 출력해 보자. |
Life is too short
1 | #Q8 (1,2,3) 튜플에 값 4를 추가하여 (1,2,3,4)를 만들어 출력해 보자. |
(1, 2, 3, 4)
Q9 다음과 같은 딕셔너리 a가 있다.
a = dict()
a
{}
다음 중 오류가 발생하는 경우를 고르고, 그 이유를 설명해 보자.
1.a[‘name’] = ‘python’
2.a[(‘a’,)] = ‘python’
3.a[[1]] = ‘python’
4.a[250] = ‘python’
1 | #Q9 1번과 3번에서 오류가 발생합니다. |
1 | #Q10 딕셔너리 a에서 'B'에 해당되는 값을 추출해 보자. |
{'A': 90, 'C': 70}
80
1 | #Q11 a 리스트에서 중복 숫자를 제거해 보자. |
[1, 2, 3, 4, 5]
Q12 파이썬은 다음처럼 동일한 값에 여러 개의 변수를 선언할 수 있다. 다음과 같이 a, b 변수를 선언한 후 a의 두 번째 요솟값을 변경하면 b 값은 어떻게 될까? 그리고 이런 결과가 오는 이유에 대해 설명해 보자.
a = b = [1, 2, 3]
a[1] = 4
print(b)
1 | #Q12 |
[1, 4, 3]
3장 연습문제
1 | #Q1 다음 코드의 결괏값은? |
shirt
1 | #Q2 while문을 사용해 1부터 1000까지의 자연수 중 3의 배수의 합을 구해 보자. |
166833
1 | #Q3 while문을 사용하여 다음과 같이 별(*)을 표시하는 프로그램을 작성해 보자. |
*
**
***
****
*****
1 | #Q4 for문을 사용해 1부터 100까지의 숫자를 출력해 보자. |
1 | #Q5 A 학급에 총 10명의 학생이 있다. 이 학생들의 중간고사 점수는 다음과 같다. |
79.0
1 | #Q6 리스트 중에서 홀수에만 2를 곱하여 저장하는 다음 코드가 있다. |
[2, 6, 10]
R 기초
*** R 기초 강의 내용을 정리한 글입니다.
==3.10==================================================
R 설치, 초기설정, 기초.
구글 검색 : R
English 버전으로 다운로드.
구글 검색 : Rstudio
IDE 다운로드 - Desktop 버전. free 다운로드
*가능하면 관리자 권한으로 설치하라
[Rstudio]
새 스크립트] new file → Rscript
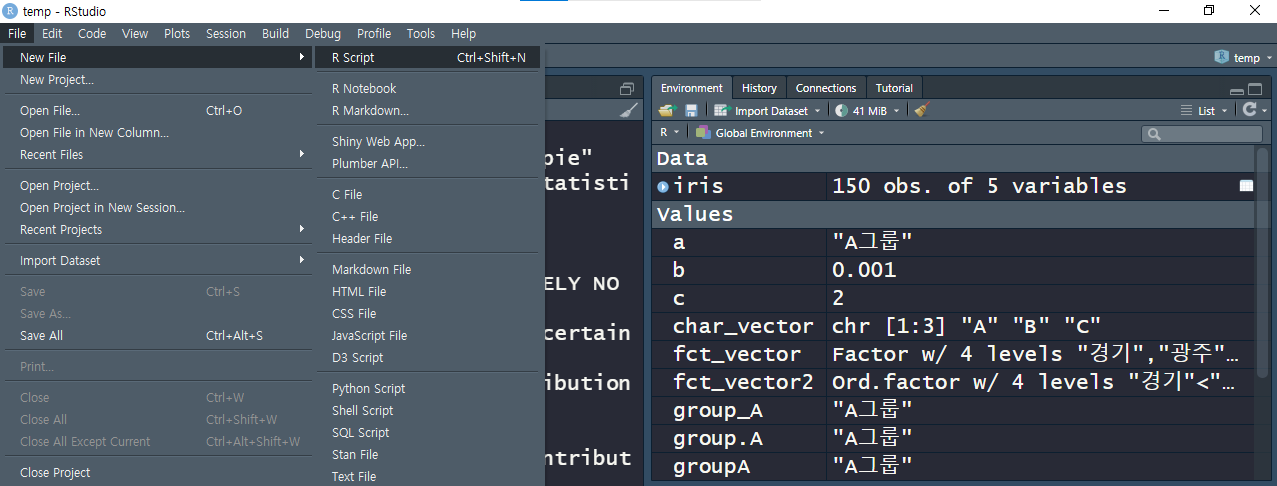
초기 설정] tools → gobal option → code → editing -> soft-wrap R source files 체크
→ saving → change → utf-8로 변경
글씨 조정 기능] tools → gobal option → appearance
코드 실행] ctrl + Enter
코드 저장] ctrl + s
프로젝트 생성] 우측 상단 : project : none ⇒ new project ⇒ new directory ⇒ new project
⇒ 파일이름 : temp 생성
스크립트 저장] 스크립트 생성 ⇒ ctrl + s ⇒ 이름 : ch01 생성
라이브러리 설치] 구글 검색 : Rtools → using rtools on window → 64bit 버전 다운로드
→관리자 권한으로 install 실행. → 에러 발생 시) 단체 채팅 방 링크로 들어가 4번 영상을 참고.
→ 에러 발생 시) 원 드라이브 비활성화
*경로에 한글이 있어도 에러.
라이브러리 사용] 스크립트에 다음 내용을 복사 붙여넣기 → 실행 → 저장 → 종료write('PATH="${RTOOLS40_HOME}\\usr\\bin;${PATH}"', file = "~/.Renviron", append = TRUE)
→ temp 파일 켜기 → 스크립트에 다음 내용을 복사 붙여넣기Sys.which("make")
→ 실행 → console 창에 sys.which(”make”) 가 출력되면 성공.
→ 다음 내용을 복사 붙여넣기install.packages("jsonlite", type = "source")
→ 실행 → DONE (jsonlite) 출력 시 성공.
→ 다음 내용을 복사 붙여넣기install.packages("tidyverse")
install.packages(”ggplot2”)
→ 실행 → 다운로드 완료 → 다음 내용을 복사 붙여넣고 각각 실행
library(ggplot2)library(tidyverse)iris <- iris
→ console 창에 iris←iris 가 출력되면 성공.→ 다음 내용을 복사 붙여넣기
ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width)) + geom_point()
→ 실행 → 우측의 plot에 그림이 출력되면 성공
[GitHub]
gitHub 회원가입
구글 검색 : git → git download → window → 64bit 다운로드
시스템 환경 변수 편집 → 시스템 환경 변수 → 시스템 변수 : path → 편집 → cmd있는지 확인
다음 링크 → code → 복사
https://github.com/dschloe/R_edu
바탕화면 → 우클릭 → git bench here → git 창에 다음 내용 입력.
→ 바탕화면 : R_edu 파일 생성 시 성공
$ git clone https://github.com/dschloe/R_edu.git
(cd Desktop에서 설치가 진행되어야 한다.)
바탕화면 → R_edu 파일 → R_edu 실행
[패키지]
여러 함수를 모아놓은 것
- 패키지 설치 : install.packages(”패키지 이름”)
- 패키지 구동 : library(패키지 이름)
다음 링크 → packeges → 원하는 것을 찾아 사용.
The Comprehensive R Archive Network (r-project.org)
예시) ggplot2의 패키지 → packages에서 ctrl + F 로 검색. → 메뉴얼 읽고 사용.
*ggplot2는 R참고서 201p에 기재되어있다.
사용 예시) The Comprehensive R Archive Network (r-project.org) → packages → Table of available packages, sorted by date of publication → (원하는 패키지를 ctrl + F로 찾아서 선택) ggplot2 → reference manual : ggplot2.pdf 를 클릭 → (index에서 원하는 함수를 선택해 이동)
→ Example 항목을 찾아서 복사 → 스크립트에 붙여넣기 → 스크립트 맨 위에 install.packagese(함수 이름) 작성 → 실행 → 사용 가능.
다음 명령을 스크립트에서 실행
library(ggplot2)
install packages(”writexl”)
library(writexl)
library(ggplot2) // 다운 받은 것을 가져와서 사용한다는 의미
ggplot()
*이후에 R 심화 과정을 원할 경우 참고 : 원서 https://r4ds.had.co.nz/
그래프 시각화 지원 https://www.r-graph-gallery.com/
[그래프 시각화 지원 plot 사용 ]
Basic ridgeline plot – the R Graph Gallery (r-graph-gallery.com)
위 링크의 코드 복사 → 스크립트에 붙여넣기 → 실행.
[치트 시트]
자주 사용하는 것들을 모아놓은 것.
Rstudio → help → cheat sheets → browser cheat sheets 또는 data visualization with ggplot2
위 과정대로 진행 시 cheat seet가 다운로드 됨.
chapter 1. 기초 문법
1 / 100 * 30
a <- 1 / 100 * 30
b <- 1 / 1000
a <- “A그룹” # (x)
a <- “A그룹”
groupA <- “A그룹”
group_A <- “A그룹”
group.A <- “A그룹”
r_basics <- 3
r_basics
변수 유형 확인 예시
class(r_basics)
class(group_A)
temp <- TRUE
class(temp)
[3장 데이터 타입]
R을 이용한 공공데이터 분석 36p.
chapter 2.벡터 만들기
num_vector = c(1,2,3)
print(num_vector)
class(num_vector)
char_vector = c(“A”,”B”,”C”)
print(char_vector)
class(char_vector)
logical_vector = c(TRUE, FALSE, FALSE)
print(logical_vector)
class(logical_vector)
(1) 예외
temp = c(1, “1”, 2)
print(temp)
class(temp) // 모두 문자화
temp = c(1, FALSE, TRUE)
print(temp)
class(temp) // 모두 숫자화
temp = c(“A”,FALSE, TRUE)
print(temp)
class(temp) // 모두 문자화
####(2) 범주형 변수 ####
#비서열 척도 = 명목형 척도
location_vector = c(“서울”, “경기”,”대구”, “광주”)
fct_vector = factor(location_vector)
print(fct_vector)
class(fct_vector)
결과)
print(fct_vector)
[1] 서울 경기 대구 광주
Levels: 경기 광주 대구 서울
class(fct_vector)
[1] “factor”
#서열 척도
fct_vector2 = factor(location_vector,ordered=TRUE)
print(fct_vector2)
class(fct_vector2)
결과)
print(fct_vector2)
[1] 서울 경기 대구 광주
Levels: 경기 < 광주 < 대구 < 서울
class(fct_vector2)
[1] “ordered” “factor”
==3.11==================================================
dplyr 함수 사용하기 & 어떤 로컬에 있든 불러오기 & 시각화
install.packages(“패키지명”)
library(dplyr) # 데이터 가공
이름 <- c(“evan”, “윤석열”, “이재명”)
나이 <- c(20, 30, 40)
지각 <- c(TRUE, FALSE, FALSE)
students <- data.frame(name = 이름,
age = 나이,
atte = 지각)
str(students)
#경로확인
getwd()
#파일저장
write.csv(x = students, file = “학생.csv”)
#엑셀로 내보내기
install.packages(”writexl”)
library(writexl)
write_xlsx(x=student, path= ”학생.xlsx”)
#모두 지우기
rm(list=ls())
#파일 불러오기
getwd()
students <- read.csv(“학생.csv”)
****중요
위 파란 부분이 가장 오래 걸리는 부분이다.
sql 문법과 유사하여, dplyr패키지를 배운 뒤,
sql을 배우면 보다 빠르게 쿼리 작성에 능숙해질 수 있음
#dplyr 패키지
library(dplyr)
iris ← iris
str(iris)
iris %>% #~에서 # 150개, 5개의 변수
select(Sepal.Length, Sepal.width) %>% # 150개, 2개
filter(Sepal.Length > 6) %>% # 61개, 2개의 변수
..
..
head(10) → iris2 # 10개, 2개의 변수
?head()
구글 검색 : dplyr → 쿠라레? → 다음링크 → dplyr.pdf
CRAN - Package dplyr (r-project.org)
로우데이터=가공되지 않은 데이터
dplyr = 데이터 가공
과제: 교재 98p에서부터 명령어 하나씩 써보기
과제: 하루에 코딩 5,6 시간
강사님이 카톡으로 전송한 data, solution 파일 다운로드
r_edu 파일로 실행 → 다음과 같은 경로로 폴더를 연다 → 1_2_dplyr 실행.
위 그림에서 ‘(톱니바퀴 모양) more’→ set as working directory # 경로 잡기
1_2_dplyr 파일에서 다음 내용을 실행
counties <- readxl::read_xlsx(“counties.xslx”, sheet = 1).
만약 에러나오면
다음과 같이 data/ 를 추가하거나, read의 괄호안에서 Tab으로 찾아라.
counties <- readxl::read_xlsx(“data/counties.xslx”, sheet = 1)
[restats 파일 부르기]
다음을 실행.
getwd()
stats <- read.csv(“data/restats.csv””) # restats.csv
[파일 미리보기]
glimpse(counties) 실행 → 안되면, library(dplyr) 실행 후에 다시 실행.
강사님이 카톡으로 전송한 public dataset 파일 다음 경로에 다운로드
바탕화면 → solution → data → () 여기에 다운로드.
새스크립트 : dplyr_practice 만들고 1 or 2 선택해서 해보기
책 99p에 있는 코드부터 알아서 실행해보기.
구글 검색:r-4 data → 5 data transformation 참고해서 실행해보기
QnA) 교재 104p 참고 → :: 에 대한 질문.
불러올 때는 더블콜론(::)을 이용해서 불러오시오
install.packages(”hflights”)
library(hflights) # 불러와서 씀
hflights = hflights::hflights # 임시로 잠깐 씀
둘다 비슷한 기능.
[불러오는 법]
- 경로는 more → set as working directory 에서 잡고
- 위치는 read.csv(””) 에서 tab으로 찾아 들어가라.
불러오는 법 ex)
- more → set as working directory
- 다음 같은 형식으로 실행.
getwd()
student <- read.csv(“source_2021/1_day_eda/data/student.csv”)
mpg1 <- read.csv(“source_2021/1_day_eda/data/public_dataset/mpg1.csv”)
강사님이랑
1_2_dplyr 스크립트의 내용을 따라감.
glimpse , select, arrange, filter, mutate 등 배움.
count, summarise 등 배움.
summarise에 앞서 엑셀의 피벗테이블 개념 숙지.
피벗테이블 = 엑셀에서 시트의 일부분을 엮어 세팅하는 정보 테이블
다음을 참고.
엑셀 | 피벗 테이블(Pivot Table) 만드는 방법 – ㈜소프트이천 (soft2000.com)
group by 사용 예시
counties %>%
select(state, population, private_work, public_work, self_employed) %>%
group_by(state) %>%
summarise(min_pop = min(population),
max_pop = max(population),
avg_pop = mean(population))
[시각화]
수많은 데이터를 분석해야 하지만 한 눈에 들어오도록 하는 것은 쉽지 않다.
방대한 데이터를 한 눈에 보이게 만드는 것이 시각화이다.
시각적 요소를 이용해 대량의 데이터를 강제로 인지시킨다고 한다.
*참고)
구글검색 : inf learn → 시각화
구글검색 : dacon → 시각화 경진대회 & 참가자 제출물 참고하기.
구직자를 위한 기업 트렌드 시각화 경진대회 - DACON
구글검색 : the R graph 갤러리, 유니콘
https://exts.ggplot2.tidyverse.org/gallery/
깃허브 : 강사님 깃
https://github.com/IndrajeetPatil/ggstatsplot
[시각화 코딩]
바탕화면 → R_edu → 금융데이터사이언스 스킬업.pdf → p51 참고
ggplot(data = data, aes(x = x축, y = y축)) + geon_poinrt() + ylim(3,6)

코딩 예시)
library(ggplot2)
iris <- iris
str(iris)
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width)) + geom_abline() + 옵션
[시각화 저장]
위 코드 실행 → plot에 시각화 자료 출력. → export → save as image
→ directory → 바탕화면으로 설정 → save
팁
?명령어 → 실행 → 해당 명령어의 메뉴얼이 출력된다.
==3.14==================================================
시각화.
나이팅게일
-간호사, 통계학자
-전쟁 중 사고 나서, 총이나 칼, 포탄 → 통념) 죽는 사람 많을 거라 생각.(현장 모르는 분)
-위생&부상 → 실제) 죽는 사람이 훨씬 많음(현장을 아는 분)
-제안 : 위생 강화 & 야전 병원을 좀 더 짓자 → 설득 : 그래프를 이용한 시각적 통계
시각화 표 : “금융데이터사이언스 스킬업.pdf” 53p 참고.
[시각화 실습]
질병 관련 통계.
temp 프로젝트 오픈. → 새 스크립트 → 0314.R 만들기.
바탕화면 → data → who_disease 불러와서 사용 .
데이터 불러오기
library(dplyr)
library(ggplot2)
library(readxl)
who_disease <- read_xlsx(“who_disease.xlsx”)
iris <- iris
glimpse(iris)
데이터 확인
glimpse(who_disease)
산점도 그려보기(의미없음)
ggplot(who_disease, aes(x=year,y=cases)) +
geom_point()
투명도 주기
ggplot(who_disease, aes(x=year,y=cases)) +
geom_point(alpha=0.3)
투명도,색 주기
ggplot(who_disease, aes(x=year,y=cases)) +
geom_point(alpha=0.3, colour = “red”, size=10)
그룹화
ggplot(who_disease, aes(x=year,y=cases,
colour=region))+
geom_point()
0314.R 에 다음 내용 복사 붙여 넣기.
R_edu → … → solution → 1_3_ggplot 의 ( 64 line~끝 line ) 까지 긁어서 실습.
install.packages(”waffle”)
install.packages(“carData”)
install.packages(“ggpol”)
install.packages(“ggcorrplot”)
install.packages(“mosaicData”)
install.packages(“visreg”)
install.packages(“gapminder”)
install.packages(“ggpubr”)
install.packages(“ggthemes”)
install.packages(“nycflights13”)
install.packages(“reshape”)
#install.packages(“gcookbook”)
install.packages(“ggthemes”)
*팁 : 구글 검색
- 영어로 검색하라.
- how to code 또는 how to write로 시작하라.
ex) how to write yaxis dollar sign ggplot2
[시각화 실습]
R_edu → … → solution → 1_4_ggplot 실습.
[옵션 이용하기]
*367p 참고
*메뉴얼 참고
R Markdown: The Definitive Guide (bookdown.org)
Rstudio → File 아래 (+)마크 클릭 → R Markdown
→ title, author 작성하고 OK → 생성됨 → 작명:report로 저장 → .rmd 확장자로 저장됨.
→ 톱니모양 옆에 ‘knit’ 클릭 → 관련 정보가 출력된다.

R Markdown 언어 작성 → (+)마트 달린 ‘c’ 아이콘을 클릭 → R 선택
→ R 작성 가능 창이 출력됨 → 입력 후 실행 → knit에 반영됨.
다음과 같은 식으로 report.Rmd에 적고 knit을 출력해보아라.
웹에서도 knit을 확인할 수 있다.
knit은 desktop→data→report.html 클릭→ view in web
*팁
아래의 R작성 가능 창에 install.packages를 올리지 말고 따로 install만 해놓면
library만 작성해도 잘 돌아간다.
4. 데이터 전처리
1) 분석파일을 R로 불러오기
1 | library(dplyr) |
2) 시각화 코드
- 데이터를 불러와서 Sepal.Length, Sepal.Width 두 변수에 관한 산점도 시각화를 작성한다.
1 | ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width)) + |
[배포]
knit 출력 → 우측 상단의 ‘publish’ → Rpubs (무료버전) → publish
→create an account → 내용을 임의로 작성하고 ‘continue’ → 주소를 복사해 카톡으로 전송
→본인 핸드폰으로 접속해본다. → 성공 시 knit 내용이 반영된 페이지에 접속됨.
→ 배포 : 페이지 게시 완료
[시각화 실습]
R_edu → … → solution → 1_5_ggplot 실습. → 125 line ~ end of document
구글링 : ggplot extensions → 마음에 드는 테마를 적용 가능.
→ 테마 이름을 참고하여 다운로드 ex) install.packages(“ggthemes”)
→ 사용 예시를 보고 사용 ex) p + theme_stata()
[시각화 실습]
R_edu → … → solution → 1_6_ggplot 실습 → 폰트 적용 연습
[R 참고서적]
추가적인 공부를 원할 때 참고하라.
-R data visualization
-데이터 시각화 교과서
-R을 활용한 데이터 시각화
==3.15==================================================
통계.
[데이터 분석]
-데이터수집
-데이터가공
-데이터시각화
-모델링 : 통계 모델링 / 머신러닝 모델링 / 딥러닝 모델링
-통계를 도대체 어디까지 알아야 하나?
-선형대수를 얼마나 알아야 하나?
-Top-Down방식 / Bottom-up방식
-모델링과 관련된 수식을 얼마나 알아야 하나?
[진로와 관련]
: 웹 개발자 → 라이브러리 자 갔다 쓰고, 배포 잘하면 끝.
: 데이터 분석가 → 마케터(기획) / 여론조사
-기본적인 통계(고재 8장 통계 분석)
-모수 검정 / 비모수 검정 —> 빈도 주의
-베이지안
: 머신러닝 엔지니어 / 딥러닝 엔지니어
-통계 / 선형대수 필요 / 모델링 수식 굳이…
-모형 만들고 배포를 잘해야 함(개발자)
-포폴 : 머신러닝 논문 정리(최신)
-라이브러리로 이미 만들어져 있음
-구글링 : paperswithcode → 딥러닝 관련내역
: 머신러닝 / 리서쳐 알고리즘 직접 구현
-최소 석사(관련 논문)
-네이버,카카오AI
-라이브러리를 직접 만드시는 분들
:Top-down 방식
-분석의 방향(수치 예측/분류 위주 예측)
-그룹간의 비교/인과관계
-산업분야
[ 기초 통계 ]
참고
temp → 2_day_stat_reggression → data → 기초 통계-평균,중간값,분산,표준편차.pdf

deviation: 편차
x1 : 개별 관찰값
x : 평균

vlariance : 분산 (= 편차 제곱의 평균)
x1: 개별 관찰값
x : 평균
분산값이 크다 —> 평균으로부터 멀어진 개별적인 데이터가 많다. = 흩어져있다.
분산값이 작다 —> 평균주위에 개별적인 데이터가 많다. = 평균쪽에 몰려있다.
즉, 분산은 평균으로부터 떨어진 거리를 나타냄.
모집단과 분산

*참고
temp → 2_day_stat_reggression → data → 기초 통계-변동계수.pdf

CV= 변동계수
RSD= 상대 표준 편차
평균 : u
표준편차 : o
install.packages(“tidyquant”)
install.packages(“reshape2”)
*참고
temp → 2_day_stat_reggression → data → 기초 통계-사분위수.pdf
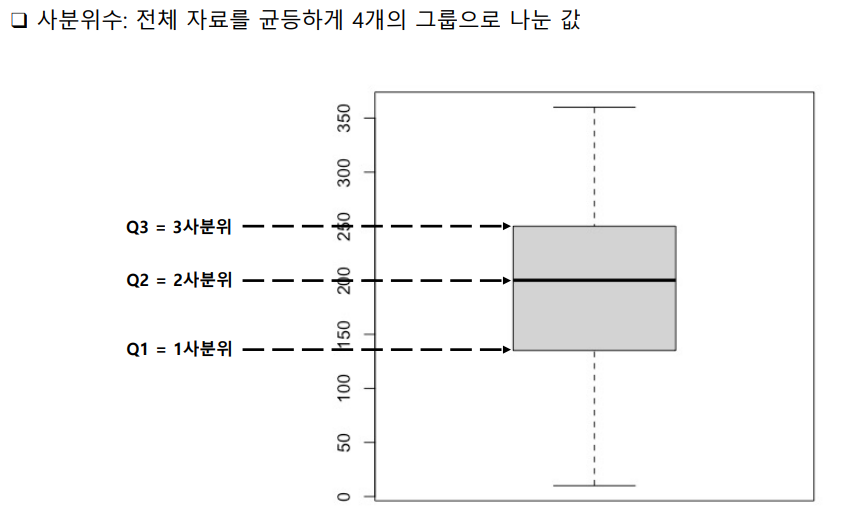
이상치 판별: 중심에서 많이 떨어진 값을 의미
이상치 하한 Q1 - 1.5x(Q3-Q1)
이상치 상한 Q3 + 1.5x(Q3-Q1)
[통계 실습]
슬랙 → #edu 채널 → 3/15에 게시된 ‘3교시 코드’ 참고
*참고
temp → 2_day_stat_reggression → data → 기초통계-z_score.pdf

X = 원 데이터
M = 평균
SD = 표준편차
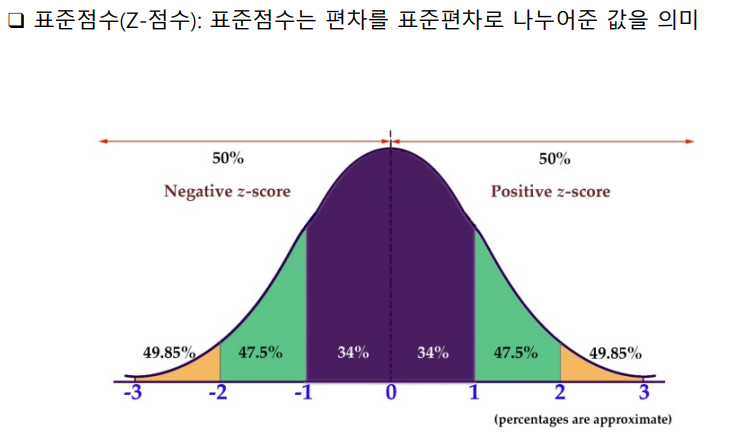
*참고
temp → 2_day_stat_reggression → data → 기초통계-z_test.pdf
❑ 가설검정(Hypothesis Testing)
-평균에 대한 가설 검정
-잘못된 가정: 대한민국 성인의 키는 크다
-올바른 가정: 대한민국 성인의 평균 키는 170cm 이다 .
❑귀무가설 및 대립가설
o 귀무가설(H0)
-내용: 대한민국 성인의 평균 키는 170cm이다.
-통계적 표시법: H0: u = 170
o 대립가설(H1)
- 내용
• 평균 키는 170이 아니다. = 제1형 = 양측검정
• 평균 키는 170보다 작다. = 제2형 = 단측검정 = 좌측 검정
• 평균 키는 170보다 크다. = 제3형 = 단측검정 = 우측 검정
❑ 가설 선택의 기준 수립
1종 오류(type 1 error)
→ 제1종 오류는 우리가 모집단에 효과가 진짜로 존재한다고 믿지만
사실은 아무런 효과도 없는 것이다.
2종 오류(type 2 error)
→ 제1종 오류와는 반대이다. 즉, 모집단에 실제로 효과가 존재하지만
우리는 모집단에 아무 효과도 존재하지 않는다고 믿는 것이 제2종 오류이다.
o 유의수준
- 제 1종 오류를 범할 확률의 최대 허용 한계 (유의수준 a)
표는 z_test.pdf 참고.
[통계 실습]
temp → 2_day_stat_reggression → source → 2_5_1_hypothesis_testing.R
temp → 2_day_stat_reggression → source → 2_5_2_one_sample.R
temp → 2_day_stat_reggression → source → 2_5_3_paired_t_test.R
*참고
temp → 2_day_stat_reggression → data → 기초통계-???
두 평균의 비교 (대응 표본 vs 독립표본)
단일 표본 T-Test
- 차이가 있는가? (모집단 vs 표본)
두개 표본 T-Test
대응표본 예시 : 신약 개발 시험 (사전 테스트 + 사후 테스트)
독립표본 예시 : 남자와 여자의 몸무게 비교
공통 사항 검정
- 정규성 검정 여부 확인
데이터 T-Test는 정규성 여부 확인을 전제로 만들어져서
단일 모집단 검정시에도 정규성 여부 조건을 확인해야 한다.
ex) 레벨이 부족할 때 고레벨 전용 아이템을 사용 못하는 것과 같다.
==3.16==================================================
R의 마지막
[전날 수업 내용 정리]
기초통계의 핵심 : 평균
편차 : 평균과 개별적인 데이터 사이의 거리
분사(variance) : 편차의 제곱합의 데이터 객수만큼 나눔
표준편차 : 분산에 루트 씌운다
표준편차 + 평균 활용
변동계수, z-score, 검정값, 표준오차
모수 검정
핵심: 두 그룹간의 평균의 차이를 검정
두 그룹간의 차이가 유의미하냐? 우연히, 어쩌다가 한 번 일어난거냐!
가정 : 데이터가 정규분표를 이룬다!
평균 비교
One Sample T Test : 모집단의 평균 ~ 샘플(표본)의 평균
대응표본 : 사전 표본의 평균(정책, 신약 투여 등등 시간이 지난 후) 사후 표본의 평균
독립표본 : A 그룹과 B그룹간의 평균 비교
결국은 평균을 비교하는 것.
귀무가설 ~ 대립가설
귀무가설 : 두 그룹가의 00평균의 차이가 없다!
대립가설 : 두 그룹간의 평균의 차이는 존재하더라!
t 통계량 / p-value
구글링 : 표준정규분포표 → 표를 보고 p-value값을 계산하면 된다
*팁
‘우리 나라 석사 학위 논문’
구글링 : RISS 하여 들어가서 찾아서 보면 된다.
논문은 별거 아니다.
다만, 데이터 수집하는 것이 가장 어렵다.
[기초통계-분산분석]
*참고
temp → 2_day_stat_reggression → data → 기초통계-분산분석.pdf
예를들어, 어느 학교의 3개의 반의 성적을 비교한다고 할 때, 3번을 비교해야한다.
분산분석
: 두 개 이상 다수의 집단을 서로 평균에서 분산값을 비교하기 위한 가설검정 방법
F분표
: 분산의 비교를 통해 얻어진 분표비율
계산식

-1학년 전체 학생 인원의 분산 : 300명 ( 분산=100) // 표본 내 분산
-각 반의 분산 // 표본 평균 간 분산
1반의 분산 90
2반의 분산 70
.
.
가설수립
-귀무가설 : 3학년 1,2,3반의 평균은 모두 같다.
-대립가설: 적어도 1개반의 평균은 다르다.
F통계량 공식
-F = 검정통계량
-F통계량은 오차의 평균제곱합과 처리의 평균제곱합의 비인 MST/MSE
-이를 나타내는 두 개의 자요도(k-1, n-k)를 모수로 하는 F-분포를 따르는 F 통계량
F = MST/MSE~F(k-1,m-k)
-MSE(오차 평균 제곱합) : 처리’내’ 제곱합을 자유도로 나눈 값
-MST(처리 평균 제곱합) : 처리’간’ 제곱합을 자유도로 나눈 값
일원분산분석 모형
검정통계량 구하기
-분산 : 각 개별 자료값과 평균과의 차이
-총편차 : 개별자료와 전체 평균(y)과의 차
- 총 제곱합 (SST) = 오차제곱합(SSE) + 처리제곱합(SST)
[통계 실습]
temp → 0314 스크립트 생성
분산분석
라이브러리 불러오기
library(dplyr)
library(ggplot2)
데이터 수집 및 가공
my_data = PlantGrowth
my_data$group <- ordered(my_data$group, levels=c(“ctrl”,”trt1”,”trt2”))
my_data %>%
group_by(group) %>%
summarise(
count = n(),
mean = mean(weight, na.rm= TRUE),
sd = sd(weight, na.rm = TRUE)
)
ggplot(my_data, aes(x=group, y=weight))+
geom_boxplot()
one=way ANOVA 테스트
오차제곱합(SSE)
ctrl <- my_data$weight[my_data$group==”ctrl”]
trt1 <- my_data$weight[my_data$group==”trt1”]
trt2 <- my_data$weight[my_data$group==”trt2”]
ctrl_mean = mean(ctrl)
trt1_mean = mean(trt1)
trt2_mean = mean(trt2)
각 처리별 제곱합
ctrl_sse = sum((ctrl-ctrl_mean)^2)
trt1_sse = sum((trt1-trt1_mean)^2)
trt2_sse = sum((trt2-trt2_mean)^2)
오차의 제곱합
sse <- ctrl_sse + trt1_sse + trt2_sse
sse
오차의 자유도
dfe <- (length(ctrl)-1) + (length(trt1)-1) + (length(trt2)-1)
처리의 제곱합 구하기 (SST)
total_mean = mean(my_data$weight)
ctrl_sst = length(ctrl) * sum((ctrl_mean - total_mean) ^ 2)
trt1_sst = length(trt1) * sum((trt1_mean - total_mean) ^ 2)
trt2_sst = length(trt2) * sum((trt2_mean - total_mean) ^ 2)
처리 제곱합
sst = ctrl_sst + trt1_sst + trt2_sst
처리 제곱합의 자유도
dft = length(levels(my_data$group)) - 1
전체 제곱합과 분해된 제곱합의 합 구하기
tsq = sum((my_data$weight - total_mean) ^ 2)
ss = sst + sse #총 제곱합
all.equal(tsq, ss) # TRUE
검정 통계량
mst = sst / dft
mse = sse / dfe
f.t = mst / mse
f.t
alpha = 0.5
tol <- qf(1-alpha, 2, 27)
tol
p.value = 1-pf(f.t, 2, 27)
p.value # 0.0159…
즉, 적어도 반 하나의 평균은 다르다.
위의 모든 과정을 아래의 코드로 축약 가능
res.aov <- aov(weight ~ group, data =my_data)
summary(res.aov) # p-value = 0.0159…
회귀식의 기본 공식
*참고
바탕화면 → R-edu → 금융데이터사이언스 스킬업.pdf → 101p 참고
회귀 : 이전 데이터를 바탕으로 앞으로의 일을 예상하는 것
예시) 날씨 & 온도 에 따른 아이스 아메리카노 판매량
온도, 강우, 위치 —> 설명변수, 독립변수
판매량 —> 종속변수, 반응변수
결과i = (model) + 오차i
model = 최소제곱법
model = 기울기 * 예측변수의 점수 + 절편 # 절편 = 기본으로(최소한도) 팔리는 아아 판매량
결정 계수( R-squared)
: 회귀모델의 추정된 회귀식이 관측된 데이터를 설명하고 있는 비율을 계수로 나타낸 것
: R 교재 186p 참고
팁
구글링 : wikidocs → Must learning With R (개정판) = e-book → 통계 관련 내용 참고
Must Learning with R (개정판) - WikiDocs
스캔파일 → 앤디 필드의 유쾌한 R 통계학 → 머신러닝 있어서 어려움 & 에러도 섞여있을 것.
유쾌한 알 통계학.pdf - OneDrive (live.com) 강의실 pc에 다운로드 완료
- Reference : R을 이용한 공공데이터 분석
Java Script
유튜브 영상인 ‘자바스크립트 입문’ 영상을 정리한 글입니다.
*참고 - 생활코딩 링크
https://opentutorials.org/course/1
=1번 영상============================================
[프로그래밍이란 무엇인가]
자바스크립트 = 웹브라우저 제작 가능한 언어
탈웹브라우저의 흐름 → 자바스크립트를 웹서버에서 사용
웹서버를 동작하는 도구로서의 자바스크립트 = 서버 사이드 스크립트
node.js = 서버 사이드 스크립트의 대표적 기술.
자바스크립트는 웹브라우저에서 동작하지만 시간이 흘러
자바스크립트를 웹서버에서 동작하게 하는 기술이 등장.
이 기술의 예시로는 PHP, JAVA, PYTHON, Node.js 등이 있으며
이중에서도 각광받고 있는 기술이 Node.js 이다.
또 하나의 자바스크립트의 중요한 흐름은 탈웹.
웹 밖에서도 자바스크립트가 사용되기 시작.
이 예시로는 google apps script가 있다.
언어 = 의사소통을 위한 ‘약속’
자바스크립트의 작동 환경 → 웹브라우저, nod.js, spreadSheet
웹브라우저에서 alert가 작동하고
node.js에서 write가 사용되며
spreadSheet 에서 msgBox가 이용됨.
=2번 영상============================================
[언어의 실행방법과 실습환경에 대해서 알아본다]
기본 에디터를 사용하여 자바스크립트를 실행하는 법을 공부.
윈도우 기준 → 텍스트에디터 = 메모장 사용
링크를 타고 해당 내용을 복사 붙여넣기.
`
`+→ alert 명령어는 경고창 형태로 띄우는 기능.
다른 이름으로 저장하기 → sample.html → 파일형식:모든 파일 → 인코딩:UTF-8
https://opentutorials.org/module/532/4646
해당 링크를 참고하라.
=3번 영상============================================
Chrome 크롬 브라우저 기준으로 설명.
개발자 도구를 킵니다 : 웹 브라우저 → 도구 → 개발자 도구
자바스크립트를 입력합니다 : 개발자 도구 → console → 자바스크립트 입력
더 자세한 정보는 해당 링크를 참고.
https://opentutorials.org/course/580
`
`해당 내용으로 메모장을 수정하고 저장만 하면 적용됨.
=4번 영상============================================
도구의 선택.
IDE = 통합 개발 환경
운영 체제에 맞는 IDE 를 사용해야 한다.
좋은 개발 도구를 사용하는 것은 좋은 코드를 작성하는 것만큼 중요.
https://opentutorials.org/module/406/3595
=5번 영상============================================
숫자와 문자 : 수의 표현
sublime Text를 설치.
파일 목록 표시 : view → show side view
사용할 파일 지정? : project → open project
입력할 창 생성 : 폴더에 우클릭 → new file
내용 입력 : 1. html 입력 후 Tab 키 = 기본적인 내용이 채워짐.
2. 빈 부분에 script 입력 후 Tab 키 = 추가로 내용이 채워짐.
3. 다음 캡처와 같이 정리하고 빈 칸에 원하는 내용 입력.
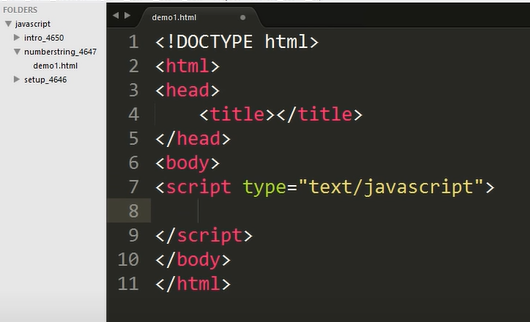
자바스크립트 입력 후 저장하면 적용된다.
ex) alert(1); alert(1.1); alert(1.1+1.1); alert(2*8)
1 → 정수
1.1 → 실수
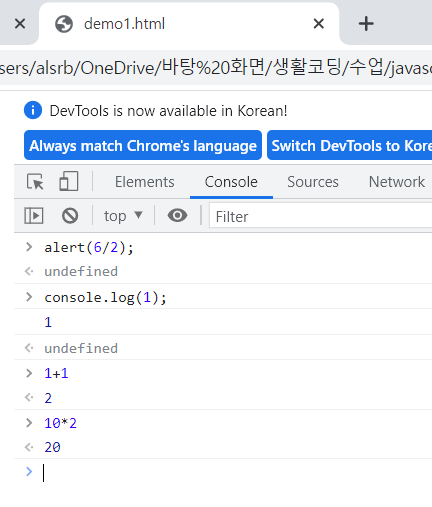
개발자 도구의 콘솔에서도 계산 가능.
=6번 영상============================================
수학 관련 명령어
수학 함수 Math 소개.
Math.pow(3,2); →>>> 3의 제곱은 9라는 내용.
→ 9
Math.round(10.6); →>>> 10.6의 반올림
→11
Math.ceil(10.2); →>>> 10.2의 올림.
→11
Math.floor(10.2); →>>> 10.2의 내림.
→ 10
Math.sqrt(9) →>>> 9의 제곱근.
→3
Math.random(); →>>> 1보다 작은 랜덤 실수.
100 * Math.random(); →>>> 100보다 작은 랜덤 실수.
Math.round( 100 * Math.random() ); →>>> 100 보다 작은 랜덤 정수
=7번 영상============================================
따옴표 사용.
따옴표 = 지금부터 작성하는 것은 문자임
작은 따옴표로 열은 문장은 작은 따옴표로 닫아야 한다.
큰 따옴표로 열은 문장은 큰 따옴표로 닫아야 한다.

*작은 따옴표 내에서 작은 따옴표 사용하기 ⇒ 역 슬래쉬 사용 ⇒ \ (escape)
*따옴표 내에 있다면 숫자라도 문자 취급 ⇒ ‘1’ 은 문자이다.
따라서 ‘1’+’1’ = ‘11’ 이다.
*타입 구분법 ⇒ typeof
ex) typeof 1, typeof ‘1’
=8번 영상============================================
개행 사용법.
개행 = 줄바꿈이란 의미 ⇒ \n
공백 생성법 ⇒ “ “ 와 + 를 사용.
ex) “coding” + “ “ + “everyday ⇒ coding everyday
길이 측정법 ⇒ length 를 사용
ex) “coding everybody”.length = 16
*자바스크립트 명령어 모음.
다음 링크를 참고하라.
https://opentutorials.org/course/50/37
문자 위치 출력 ⇒ indexOf 를 사용
ex) “code”.indexOf(”c”)=0, “code”.indexOf(”o”)=1,
“code”.indexOf(”d”)=2, “code”.indexOf(”e”)=3
=9번 영상============================================
변수.
변수 선언 예시 ⇒ var a = 1;
다음 같이 시행하면 경고창으로 10 이 출력된다.
다음과 같이 문자로도 사용 가능하다.
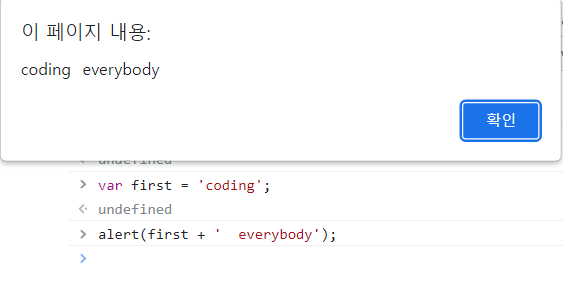
=10번 영상===========================================
[변수의 효용]
변수의 값을 바꾸면 해당 변수가 들어간 모든 식에 반영이 된다.
이것은 매우 편리하고 실용적인 기능이다. 변수를 쓰는 이유 중 하나이다.
변수 사용 팁 ⇒ 여러 줄로 이루어진 식이 있다면
변할 수 있는 부분과 변하지 않는 부분으로 나누어라.
직접 사용해보면 알겠지만 유지보수에 좋은 형태이다.
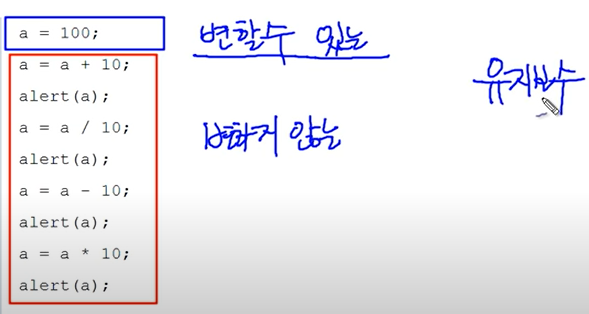
=11번 영상===========================================
[주석]
주석 ⇒ 코드의 실행에 관여하지 않는 설명문이다.
⇒ // 으로 사용가능.
⇒ ex) // 이 문장은 주석이다.
⇒ /* */ 으로도 사용 가능하다.
좋은 주석은 좋은 코드의 요인 중 하나이다.
미래의 타인이 되었을 자신을 위한 배려.
=12번 영상===========================================
[줄바꿈과 여백]
세미 콜론 ⇒ ; ⇒ 줄이 끝났다는 표시이다.
ex) var a = 1; alert(a); 이라 작성하면 서로 다른 줄로 인식도니다.
텝 ⇒ Tab ⇒ 들여쓰기가 된다.
⇒ 가독성을 높이기 위해 사용된다.
여러 줄을 드래그하고 텝하면 한 번에 들여쓰기가 적용된다.
=13번 영상===========================================
[연산자]

a=1 에서 =(equal) 은 대입 연산자이다.
다음 영상의 내용은 대입 연산자와 다른 개념인 비교 연산자이다.
=14번 영상===========================================
[ == 과 === ]
== (equal operator).
→ 동등 연산자.
→ 두 값을 비교하여 같다면 true, 틀리다면 false를 출력한다.
→ 문자도 비교 가능하다.
===( strict equal operator )
→ 일치 연산자.
→ 값은 물론이고, 데이터의 타입까지 같아야 true를 출력한다.
→ == 라면 true를 출력할 것도 false를 출력하기도 한다.
→ 말 그대로 엄격한 동등 연산자이다.
→ 한 치의 오차도 용납하지 않아야 하는 중요한 코드에 사용한다.
=15번 영상===========================================
===(일치 연산자)를 사용하자.
null = 값이 없다는 뜻.
undefined = 값이 정의되지 않았다는 뜻.
NaN = 숫자가 아니라는 뜻.
alert( undefined == null) →>>> true 가 경고창으로 출력된다.
alert( undefined === null) →>>> false 가 경고창으로 출력된다.
[type 타입]
boolean 의 예시 → true, false
number 의 예시 → -1, 0, 1, 2
string 의 예시 → “a”, “b”, “c”
null 의 예시 → null
undefined의 예시 → undefined
*주의 : alert( NaN === NaN ) 의 결과는 false. NaN 에만 해당함.
타입에 관한 자세한 정보는 다음을 참조하라.
https://opentutorials.org/module/532/4722
https://dorey.github.io/JavaScript-Equality-Table/
=16번 영상===========================================
부정과 부등호.
! = not = 부정을 의미한다.
alert( 1!= 2) 의 결과는 true이다.
부등호.
, =>, <, <=
=17번 영상===========================================
조건문이란.
조건문은 if로 시작한다.
**if**(**true**){
alert('result : true');
}
if 옆의 괄호 부분에 true가 되어야만
중괄호 안쪽의 조건문이 실행된다.
다음을 참고하라.
https://opentutorials.org/module/532/4724
=18번 영상===========================================
else, else if
else를 통해 예외를 선택해 실행할 수 있다.
**if**(**true**){
alert(1);
} **else** {
alert(2);
}
true일때는 if 부분을,
false일때는 else 부분을 실행한다.
else if는 조건문을 좀 더 풍부하게 사용할 수 있게 한다.
**if**(**false**){
alert(1);
} **else** **if**(**true**){
alert(2);
} **else** **if**(**true**){
alert(3);
} **else** {
alert(4);
}
처음으로 true가 나온 조건문만 실행한다.
위 코드의 결과는 2이다.
=19번 영상===========================================
조건문의 응용.
prompt = 스캔문이다.
사용자가 입력하는 정보를 받는 명령어다.
ex) alert( prompt(‘당신의 나이는?’)*2);
실행 시, 정보를 입력할 창이 나타난다.
사용자가 입력하는 값에 따라 출력되는 결과가 달라진다.
ex)
<!DOCTYPE html>
<**html**>
<**head**>
<**meta** charset="utf-8"/>
</**head**>
<**body**>
<**script**>
id = prompt('아이디를 입력해주세요.')
if(id=='egoing'){
alert('아이디가 일치 합니다.')
} else {
alert('아이디가 일치하지 않습니다.')
}
</**script**>
</**body**>
</**html**>
prompt의 입력창에서
입력하는 아이디가 정해진것과 같아야만
‘아이디가 일치 합니다.’ 라는 문구가 출력됩니다.
=20번 영상===========================================
논리연산자.
& = 엔퍼센트. 라고 읽는다.
&& = AND
= 모두 true 일때만 조건문 실행.
ex)
**if**(**true** && **true**){
alert(1);
}
|| = or
ex) 하나만 true 여도 조건문 실행.
**if**(**true** || **true**){
alert(1);
}
=21번 영상===========================================
boolean의 대체재.
0 = false
0이 아닌 값 = true
다음을 참고하라.
https://opentutorials.org/module/532/4724
=22번 영상===========================================
반복문.
반복분 = loop = iterator
https://opentutorials.org/module/532/4728
while 사용법.
while (조건){
반복해서 실행할 코드
}
조건이 true인한 계속해서 코드가 실행된다.
false가 된다면 코드의 반복이 종료된다.
[명령어]
document.write = 문구 출력
= 개행
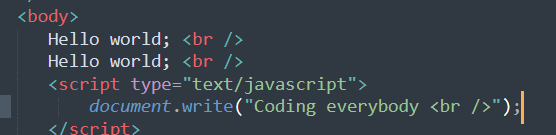
=23번 영상===========================================
반복조건.
다음과 같이 조건을 설정.
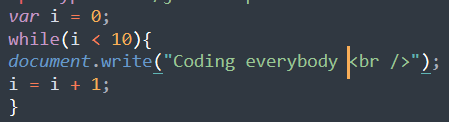
i가 0~9일 때는 반복이 실행되고
i 가 10이 되면 false가 되어 반복이 중지된다.
결과적으로 Coding everybody가 10번 출력된다.
=24번 영상===========================================
for문.
while보다 편리하다.
3가지 조건이 한 줄에 들어가기 때문.
for는 다음과 같이 사용한다.
for(초기화; 반복조건; 반복이 될 때마다 실행되는 코드){
반복해서 실행될 코드
}
ex) 이전 영상의 코드와 같은 결과를 낸다.

i++ →> 다음 라인부터 i=i+1
++i →> 현재 라인부터 i=i+1
=25번 영상===========================================
반복문의 효용.
조건에 따라 무수한 반복조건을 실행 가능.

=26번 영상===========================================
반복문의 제어.
break = 반복문을 종료.
continue = 현재 반복을 중지하고 다시 반복을 실행.
=27번 영상===========================================
반복문의 중첩.
다음과 같이 반복문 안에 반복문을 사용.
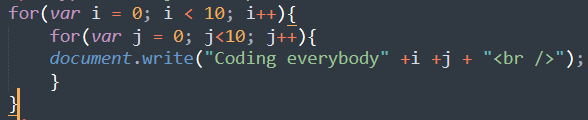
결과적으로 Coding everybody 0 ~ Coding everybody 99가 출력된다.
[디버그]
도구 → 개발자 도구 → Source → F5키.
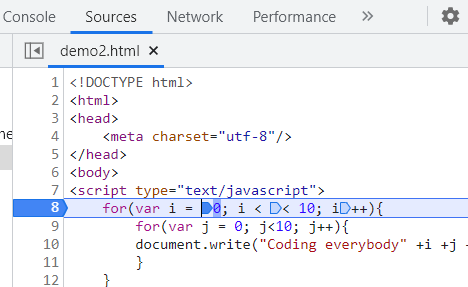
for가 있는 8번 라인을 클릭.
breakpoints에 for의 정보가 표시된다.
이 상태에서 F5키를 입력 → Pause in debugger 뜨면서 회색 화면 출력됨.
코드 실행이 8번까지 와서 멈춘 것이다.
해당 상태에서 아래쪽의 코드제어 도구들을 사용 가능하다.
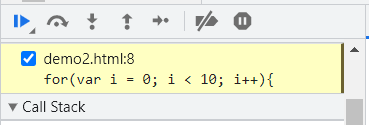
첫 번째 도구 = 코드 재실행.
두 번째 도구 =
세 번째 도구 = 다음 라인 실행
네 번째 도구 = 이전 라인 실행
코드제어 도구 옆 같에서 다음과 같이 표시 가능.
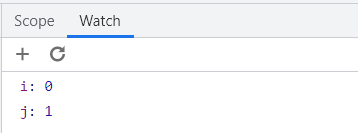
이 상태에서 벗어나기 = 8번 breakpoint를 클릭하고 첫 번째 도구를 누른다.
=28번 영상===========================================
함수.
재사용성이 높은 기능.
다음과 같이 사용한다.
function 함수명( [인자...[,인자]] ){
코드
**return** 반환값
}
ex) numbering이란 함수를 정의.
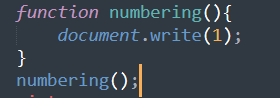
변수와 달리 옆에 괄호가 있어야 한다.
그래야 변수가 아닌 함수로 인식된다.
자세한 내용은 다음을 참고.
https://opentutorials.org/module/532/4729
=29번 영상===========================================
함수의 효용.
한 번 정의한 함수는 재사용성,
유지보수의 용이성, 가독성이 띄어나다.
=30번 영상===========================================
입력과 출력.
출력 = return
return = 출력과 동시에 함수를 종료시킨다.
function get_member1(){
**return** 'egoing';
}
function get_member2(){
**return** 'k8805';
}
alert(get_member1());
alert(get_member2());
출력 예시 = return에 의하여 alert가 egoing과 k8805를 출력된다.
=31번 영상===========================================
입력과 출력.
매개변수(parameter) = 입력받는 변수
인자(argument) = 함수로 유입되는 입력 값
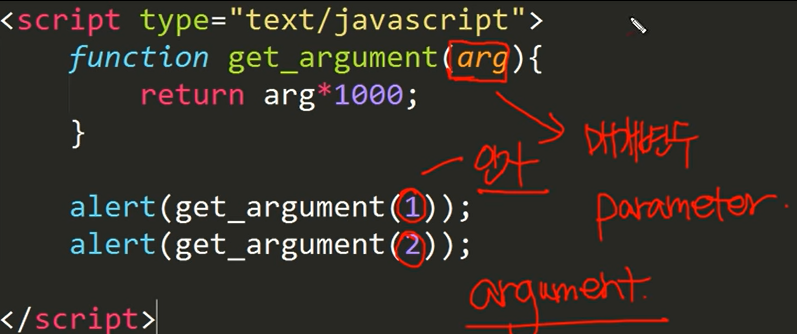
입력 예시 = alert의 실행에서 함수의 괄호에 든 값이 변수 arg에 입력된다.
=32번 영상===========================================
다양한 정의 방법.
정의 방법 예시.
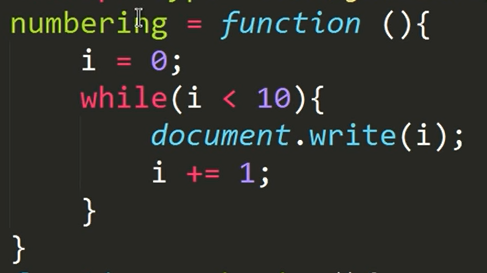
위 코드는 아래 코드와 같다고 볼 수 있다.
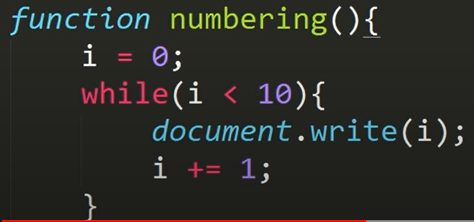
[익명함수]
다음과 같이 함수 전체를 괄호로 덮는 것이다.
함수정의와 동시에 ;옆의 ()에 의해 함수 호출이 발동.
즉, 함수 정의와 함수 호출이 동시에 되어 일회성으로 사용되는 함수가 된다.

=33번 영상===========================================
배열의 문법.
배열(array) = 연관된 데이터를 모아 관리하기 위한 데이터 타입.
= 변수가 하나의 데이터를 저장한다면 배열은 다수를 관리.
ex) **var**member = ['egoing', 'k8805', 'sorialgi']
- 위 코드의 member는 3개의 원소를 가진 배열이다.
- 배열에 담긴 원소는 0번, 1번, 2번….순서로 저장된다.
- 이 원소의 위치를 색인(index) 라고 한다.
=34번 영상===========================================
배열의 효용.
함수는 여러개의 입력이 가능한 것에 비해 출력은 하나만 가능하다.
그러나 배열을 이용해 return을 하면 여러 개의 출력이 가능해진다.
ex)
function get_members(){
**return** ['egoing', 'k8805', 'sorialgi'];
}
=35번 영상===========================================
배열과 반복문의 조우.
toUpperCase(); = 대문자로 바꿔주는 내장함수.
= 다음과 같이 사용 가능하다.
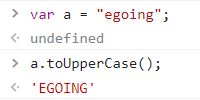
위 함수를 이용한 예시이다.
function get_members(){
**return** ['egoing', 'k8805', 'sorialgi'];
}
var members = get_members();
document.write(members[0]);
document.write(members[1]);
document.write(members[2]);
이 코드를 반복문을 통해 재구현하면 다음과 같다.
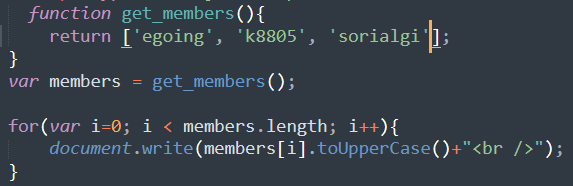
결과 : 배열의 원소들이 대문자로 출력된다.
=36번 영상===========================================
데이터의 추가.
push() = 배열에 원소 추가.
concat() = 배열에 복수의 원소 추가.
ex)
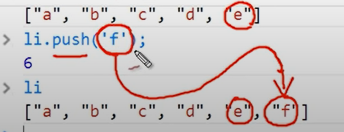
unshift() = 배열의 0번 자리에 원소 추가
ex)
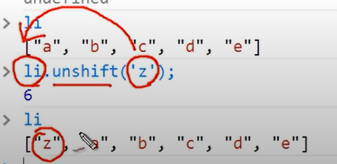
splice() = 배열의 중간에 추가
ex) splice(1,0,’d’) → 1번 자리에 원소를 0개 삭제하고 ‘d’를 추가

=37번 영상===========================================
제거와 정렬.
shift() = 배열의 0번 자리의 원소를 제거
ex)
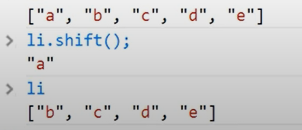
pop() = 배열의 끝의 원소를 제거
ex)
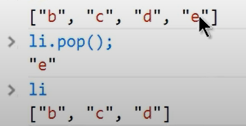
sort() = 배열의 원소를 정렬
ex)

reverse() = 배열의 원소를 거꾸로 정렬
ex)

=38번 영상===========================================
객체.
배열은 아이템에 대한 식별자로 숫자를 사용했다.
객체를 사용한다면 문자를 인덱스로 사용할 수 있다.
다음은 객체를 만드는 법이다.
**var**grades = {'egoing': 10, 'k8805': 6, 'sorialgi': 80};
위와 같이 인덱스와 값이 쌍을 이룬다. (key-value 쌍)
다음과 같이 객체를 만들 수도 있다.
var grades = {};
grades['egoing'] = 10;
grades['k8805'] = 6;
grades['sorialgi'] = 80;
만들어진 객체는 다음과 같이 이용할 수 있다.
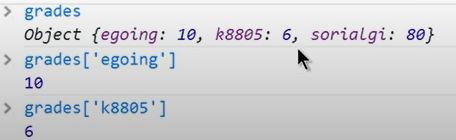
[ ]를 사용하면 다음같이 사용 가능.
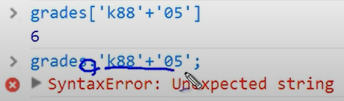
=39번 영상===========================================
객체와 반복문의 조우.
반복문에서 다음과 같이 사용.
참고로, 태크인
- ~
<li> ~ </li> 는 document.write로 작성한 부분이라 한다.
( li = list 의 약자)
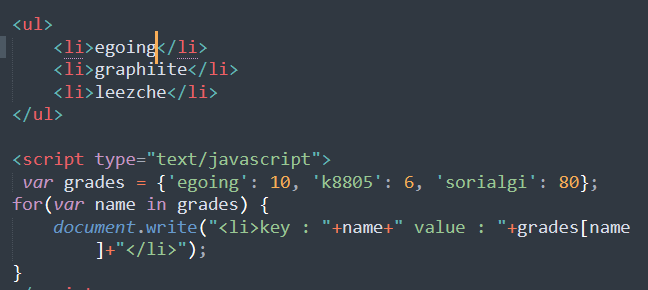
for문에 의해 반복마다 변수 name에 배열 grades의 원소가 입력된다.
결과는 다음과 같다.

다음과 같은 활용도 가능하다.
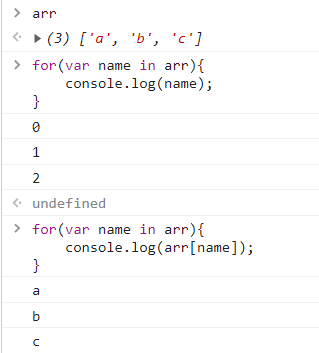
=40번 영상===========================================
객체지향 프로그래밍.
배열 안에 함수를 정의하는 법.
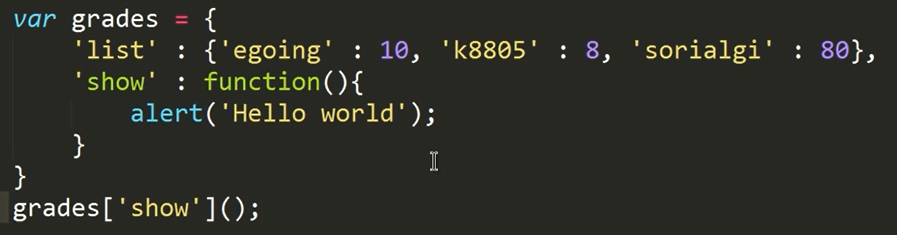
결과는 ‘Hello world’
또 다른 예시.
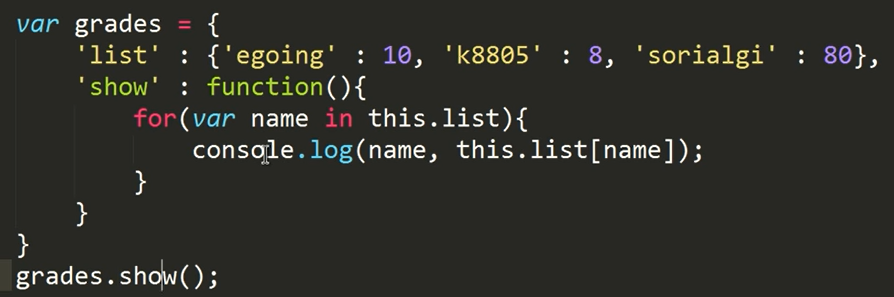
결과는 egoing 10
k8805 8
sorialgi 80
=41번 영상===========================================
모듈.
*모듈
부품. 작고 단순한 것에서 크고 복잡한 것으로 진화한다.
코드의 재활용성을 높이고, 유지보수를 쉽게 한다.
*묘듈의 장점
자주 사용되는 코드를 별도의 파일로 만들어서 필요할 때마다 활용 가능.
코드 수정 시에 필요한 로직을 빠르게 찾을 수 있다.
필요한 로직만을 로드해서 메모리의 낭비를 줄일 수 있다.
=42번 영상===========================================
모듈화.
main.html 파일 생성.
https://opentutorials.org/module/532/4750
링크의 코드 복사 붙여넣기.
src = “greeting.js” →>> 함수를 정의한 후에 호출하는 것과 같은 효과.
greeting.js 파일 생성.
파일에 함수 부분의 코드를 작성.
main.html의 함수 부분은 지운다.
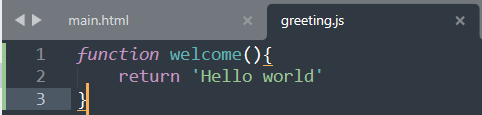
두 파일을 작성 완료했으면 main에서 실행.
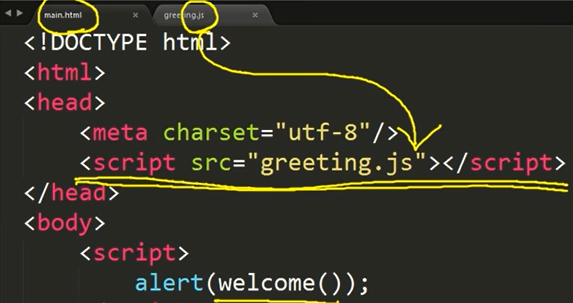
ctrl + o 를 통해 main.html을 열고 코드를 실행한다.
greeting.js이 호출되어 main에서 실행되는 결과가 나온다.
=43번 영상===========================================
Node.js의 모듈화.
다른 환경에서의 모듈은 다루는 방법이 다름.
이 영상에선 오직 그것만 인지하면 됨.
=44번 영상===========================================
라이브러리란?
[라이브러리]
- 모듈과 비슷한 개념.
- 자주 사용되는 로직을 재사용하기 편리하도록 정리한 코드들의 집합.
- 유명 라이브러리로는 jQuery 가 있다.
=45번 영상===========================================
라이브러리의 사용.
jQuery 사용법.
- jQuery에서 파일을 다운로드 받는다.
- API documentation을 보고 사용법을 숙지한다.
- 두 가지를 이용하여 라이브러리를 사용.
실제 사용법.
- 구글에서 jquery를 검색.
- jquery에서 파일을 다운받는다. https://code.jquery.com/jquery-3.6.0.js
- 다운받으면 나타나는 페이지를 전체 복사(Ctrl+A)
- jquery.js파일을 생성하고 복사한 내용을 붙여넣기.
- script 부분에 src=”jquery.js”를 작성하여 실행하면 jquery를 사용할 수 있다.
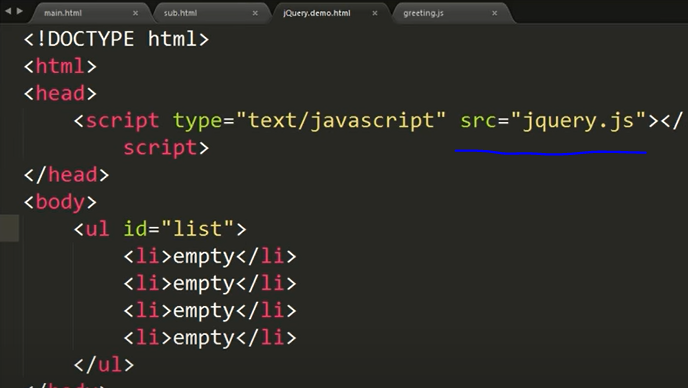
jquery 코드 작성
- jquery의 코드는 $로 시작한다.
다음은
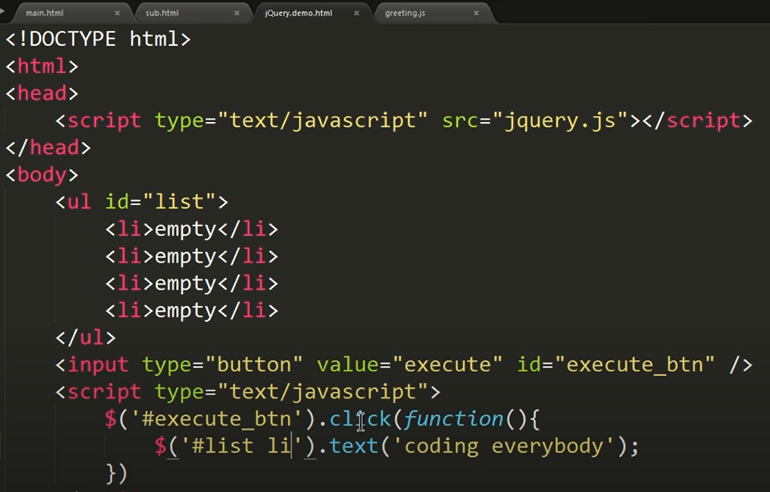
excute라는 버튼을 생성.
excute 버튼을 click시에 발동하는 함수 정의.
함수 내용은 li에 있는 텍스트를 coding everybody로 변경.
따라서 다음 결과가 나온다.
버튼을 누르면 다음과 같이 텍스트가 변경된다.

=46번 영상===========================================
JavaScript-UI,API 그리고 문서
https://opentutorials.org/module/532/6533
=47번 영상===========================================
UI와 API.
UI = User Interface
API = Application Programming Interface
UI는 코드를 모르는 사용자도 쉽게 다룰 수 있도록 해주는 편의성 중심 기술.
사용자의 의도를 손쉽게 pc에 전달하여 조작 난이도를 낮춰준다.
internet explore 의 주소창에 다음 명령어를 입력.
javascript.alert(“Hello world”);
경고창으로 Hello world가 출력된다.
이 경고창을 내가 만들었는지 시스템이 만들었는지는 애매하다.
하지만, 이 경고창의 ‘확인’에 커서를 갖다대면 색이 변하는 것이나
경고창이 뜨면서 나오는 경고음, 경고창의 위치 등은 확실하게
내가 만들었다고 할 수 없다.
이런 것들이 모두 API라고 할 수 있다.
물론 alert등의 명령어도 이에 포함된다.
정리하다면, 사용자는 UI를 통해 시스템을 사용하고
개발자는 UI와 API를 통해 시스템을 다룬다.
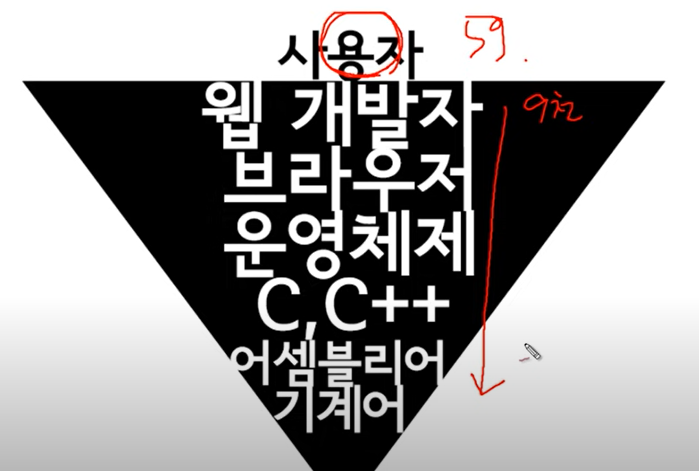
=48번 영상===========================================
문서 보는 법.
프로그래밍을 공부하기 위한 자료 - 레퍼런스, 튜토리얼
튜토리얼 = 언어의 문법을 설명.
레퍼런스 = 명령어의 사전.
자바스크립트 API는 크게 자바스크립트 자체의 API와
자바스크립트가 동작하는 호스트 환경의 API로 구분된다.
자바스크립트 API 문서 예시
- ECMA script (표준문서)
- 자바스트립트 사전 : https://opentutorials.org/course/50
- 자바스크립트 레퍼런스 (MDN)
- jscript 레퍼런스 (MSDN)
=49번 영상===========================================
정규표현식.
정규표현식은 문자열에서 특정한 문자를 찾아내는 도구다.
더 자세한 내용을 알고 싶다면 다음을 참고.
https://opentutorials.org/module/532/6580
https://opentutorials.org/course/909/5142
=50번 영상===========================================
정규표현식 : 패턴만들기
정규표현식 사용은 두가지 단계로 이루어짐.
[ 1단계 ] 컴파일 ⇒ 패턴을 찾는 것.
var str = “a”; 즉, a 라는 텍스트를 찾아내는 정규표현식을 만들어보자.
방법 1) 정규표현식 리터럴
**var**pattern = /a/
방법 2) 정규표현식 객체 생성자
var pattern = new RegExp('a');
[ 2단계 ] 실행 ⇒ 찾은 패턴을 구체화하는 것.
=51번 영상===========================================
정규표현식 : RegExp 객체의 정규 표현식
정규표현식을 컴파일해서 객체를 만들었다면
이제 문자열에서 원하는 문자를 찾아내야 한다.
RegExp.exec()
다음과 같이 사용한다.
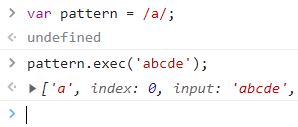
찾으려는 문자를 변수 pattern에 정의한 다음,
exec() 의 괄호에 아무 문자열이나 채워넣는다.
pattern.exec()를 실행하면 문자열중에서 pattern에 해당하는 문자를 찾아낸다.
RegExp.test()
다음과 같이 사용한다.
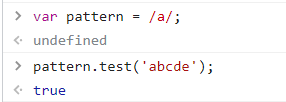
exec()와 같이 사용한다.
다만 결과는 boolean 값으로 출력된다.
찾는 문자가 있다면 true, 없다면 false.
=52번 영상===========================================
정규표현식 : String 객체의 정규 표현식
string.match()
다음과 같이 사용한다.

exec()와 비슷하다.
string.replace()
다음과 같이 사용한다.
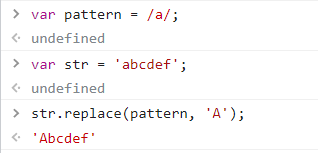
str에 입력된 문자열에서
replace()에 입력한 pattern을 찾은 후에
( )안의 인자로 대체한다.
=53번 영상===========================================
정규표현식 : 옵션
/i ⇒ 소문자 대문자 모두 찾는 옵션.
= a를 지정했음에도 “A”를 찾아 출력함.
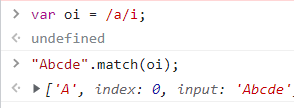
/g ⇒ 같은 문자가 여러 개 나와도 모두 찾는다. (글로벌)
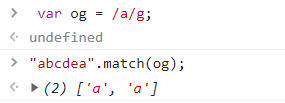
=54번 영상===========================================
정규표현식 : 캡처
괄호안의 패턴은 마치 변수처럼 재사용할 수 있다.
이 때 기호 $를 사용하는데 아래 코드는 coding과 everybody의 순서를 역전시킨다.
var pattern = /(\w+)\s(\w+)/;
var str = "coding everybody";
var result = str.replace(pattern, "$2, $1");
console.log(result);
(\w+)\s(\w+) ⇒ ‘문자+(공백)+문자’ 를 표현한 식이다.
이 식을 이용하여 다음 링크들을 살펴보자.
- 정규표현식 시각화 페이지
- 입력한 식을 시각화하여 보여준다.
- 정규표현식 빌더
- 텍스트박스에 식을 입력한다.
- 아래의 박스에 여러 단어를 입력한다.
- 텍스트박스의 식과 일치하는 아래 박스의 단어는 파랗게 빛난다.
=55번 영상===========================================
정규표현식 : 치환
다음 코드는 본문 중의 URL을 링크 html 태그로 교체한다.
var urlPattern = /\b(?:https?):\/\/[a-z0-9-+&@#\/%?=~_|!:,.;]*/gim;
var content = '생활코딩 : [http://opentutorials.org/course/1](http://opentutorials.org/course/1) 입니다. 네이버 : [http://naver.com](http://naver.com/) 입니다. ';
var result = content.replace(urlPattern, **function**(url){
**return** '<a href="'+url+'">'+url+'</a>';
});
console.log(result);
=56번 영상===========================================
유효범위 : 전역변수화 지역변수
https://opentutorials.org/module/532/6495
유효범위(Scope)는 변수의 수명을 위미.
var vscope = 'global';
function fscope(){
var vsope = 'local';
alert(vscope);
}
fscope();
함수 내에 선언된 vscope에 의해 local이 출력된다.
만약, 함수 내의 vscope이 없다면 함수 밖의 global이 출력된다.
함수 내에서 var로 변수 정의한 것은 ‘로컬(지역)변수’가 된다.
만약, var을 붙이지 않는다면 전역변수가 된다.
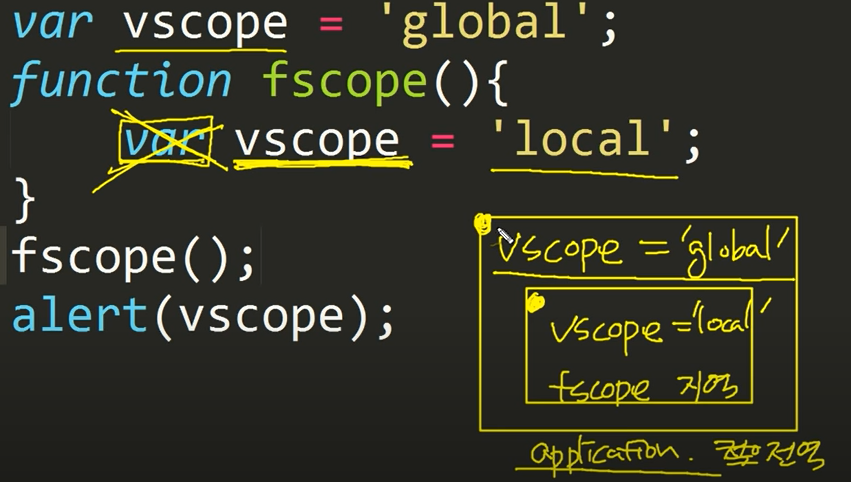
따라서, 위 코드에서 함수 내의 vscope=’local’에 의해
맽 윗줄의 var vscope 의 내용물은 ‘global’에서 ‘local’이 된다.
단, 같은 함수 내에 이미 같은 변수가 지역변수로 존재한다면
var이 안 붙어있어도 지역변수로 취급된다.
=57번 영상===========================================
유효범위 : 유효범위와 효용
아래 두개의 예제는 변수 i를 지역변수로 사용했을 때와 전역변수로 사용했을 때의 차이점을 보여준다. 전역변수는 각기 다른 로직에서 사용하는 같은 이름의 변수값을 변경시켜서 의도하지 않은 문제를 발생시킨다.
function a (){
**var** i = 0;
}
**for**(**var** i = 0; i < 5; i++){
a();
document.write(i);
}
결과 : 01234
function a (){
i = 0;
}
**for**(i = 0; i < 5; i++){
a();
document.write(i);
}
결과 : 무한반복
=58번 영상===========================================
유효범위 : 전역변수를 사용하는 법
불가피하게 전역변수를 사용해야 하는 경우는 하나의 객체를 전역변수로 만들고 객체의 속성으로 변수를 관리하는 방법을 사용한다.
다음은 전역변수 하나를 선언하고
나머지 변수는 전역변수의 소속변수로 둔 것이다.
따라서 다른 코드의 이름이 같은 변수와 충돌할 가능성을 줄일 수 있다.
var MYAPP = {}
MYAPP.calculator = {
'left' : **null**,
'right' : **null**
}
MYAPP.coordinate = {
'left' : **null**,
'right' : **null**
}
MYAPP.calculator.left = 10;
MYAPP.calculator.right = 20;
function sum(){
**return** MYAPP.calculator.left + MYAPP.calculator.right;
}
document.write(sum());
결과 : 10+20=30
=59번 영상===========================================
유효범위 : 유효범위의 대상
자바스크립트는 함수에 대한 유효범위만을 제공한다. 많은 언어들이 블록(대체로 {,})에 대한 유효범위를 제공하는 것과 다른 점이다. 아래 예제의 결과는 coding everybody이다.
**for**(**var** i = 0; i < 1; i++){
**var** name = 'coding everybody';
}
alert(name);
자바에서는 아래의 코드는 허용되지 않는다. name은 지역변수로 for 문 안에서 선언 되었는데 이를 for문 밖에서 호출하고 있기 때문이다
**for**(int i = 0; i < 10; i++){
String name = "egoing";
}
System.out.println(name);
=60번 영상===========================================
유효범위 : 정적 유효 범위
자바스크립트는 함수가 선언된 시점에서의 유효범위를 갖는다.
이러한 유효범위의 방식을 정적 유효범위(static scoping),
혹은 렉시컬(lexical scoping)이라고 한다.
var i = 5;
function a(){
**var** i = 10;
b();
}
function b(){
document.write(i);
}
a();
결과 : 5
[정적 유효범위 개념]
사용될 때가 아니라,
정의될 때를 기준으로 하기 때문에 결과는 5이다.
=61번 영상===========================================
값으로서의 함수와 콜백 : 함수의 용도1
https://opentutorials.org/module/532/6508
JavaScript에서는 함수도 객체다.
다시 말해서 일종의 값이다.
거의 모든 언어가 함수를 가지고 있다.
JavaScript의 함수가 다른 언어의 함수와 다른 점은
함수 자체 값이 될 수 있다는 점이다.
**function**a(){}
위 코드에서 함수 a는 변수 a에 담겨진 값이다.
또한 함수는 객체의 값으로 포함될 수 있다.
이렇게 객체의 속성 값으로 담겨진 함수를 메소드(method)라고 부른다.
a = {
b:**function**(){
}
};
위 코드에서 a안에 담긴 b라는 속성(property)이 있다고 볼 수 있으며,
중괄호 안의 함수 function은 메소드(method)이다.
객체 내에서 정의된 함수는 메소드이므로
a 라는 객체 안에서 정의된 함수 function은 메소드이다.
함수는 값이기 때문에 다른 함수의 인자로 전달 될수도 있다.
다음과 같이 사용 가능.
function cal(func, num){
**return** func(num)
}
function increase(num){
**return** num+1
}
function decrease(num){
**return** num-1
}
alert(cal(increase, 1));
alert(cal(decrease, 1));
=62번 영상===========================================
값으로서의 함수와 콜백 : 함수의 용도2
함수는 함수의 리턴 값으로도 사용할 수 있다.
function cal(mode){
**var** funcs = {
'plus' : **function**(left, right){**return** left + right},
'minus' : **function**(left, right){**return** left - right}
}
**return** funcs[mode];
}
alert(cal('plus')(2,1));
alert(cal('minus')(2,1));
결과 : 3, 1
배열의 값으로도 사용할 수 있다.
var process = [
**function**(input){ **return** input + 10;},
**function**(input){ **return** input * input;},
**function**(input){ **return** input / 2;}
];
var input = 1;
**for**(**var** i = 0; i < process.length; i++){
input = process[i](input);
}
alert(input);
for문에 의해 배열에 담긴 함수가 차례로 호출.
input=1 → input+10=11 → input*input=121 → input/2=60.5
결과 : 60.5
=63번 영상===========================================
값으로서 함수와 콜백 : 콜백
sort() 는 내장 메소드이다.
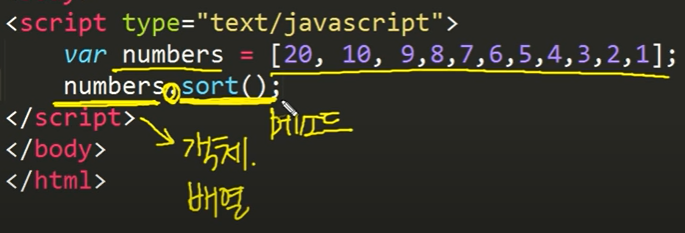
위 코드를 실행하면 sort()에 따라 배열이 정렬된다.
하지만 우리가 원하는 배열이 되지 않는다.

sort()는 앞에 온 문자로 순서를 판단하는 듯 하다.
크기 순서로 배열하려면 array()를 사용해야 한다.
자바스크립트 사전에서 array의 원리를 파악하고 코딩한 결과이다.
결과로 배열이 제대로 정렬되어 출력된다.
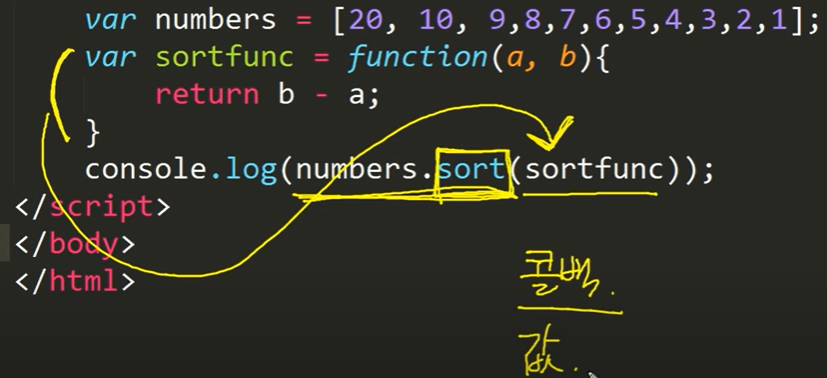
값으로 전달된 함수는 호출될 수 있기 때문에
이를 이용하면 함수의 동작을 완전히 바꿀 수 있다.
이것을 ‘콜백’이라고 하며,
이것이 가능한 것은 자바스크립트에서
함수가 값으로 취급되기 때문이다.
=64번 영상===========================================
값으로서 함수와 콜백 : 비동기 콜백
콜백은 ‘비동기처리’에서도 유용하게 사용된다.
시간이 오래걸리는 작업이 있을 때
이 작업이 완료된 후에 처리해야 할 일을 콜백으로 지정하면
해당 작업이 끝났을 때 미리 등록한 작업을 실행하도록 할 수 있다.
to-do와 비슷하다.
동기화는 비동기화의 반대되는 개념이다.
비동기 처리의 예시로는 Ajax가 있다.
Ajax = asynchronous java script and XML
( 비동기 )
=65번 영상===========================================
클로저 : 외부함수와 내부함수
https://opentutorials.org/module/532/6544
클로저(closure)는 내부함수가
외부함수의 맥락(context)에
접근할 수 있는 것을 가르킨다.
function outter(){
**function** inner(){
**var** title = 'coding everybody';
alert(title);
}
inner();
}
outter();
위 코드에서 inner()는 내부함수,
outer()는 외부함수이다.
내부함수는 외부함수의 지역변수에 접근할 수 있다.
function outter(){
**var** title = 'coding everybody';
**function** inner(){
alert(title);
}
inner();
}
outter();
결과 : coding everybody
이 결과는 inner() 외부함수의 지역변수인 var title에
접근할 수 있음을 알려준다.
=66번 영상===========================================
클로저 : 클로저란
클로저(closure)는 내부함수와 밀접한 관계를 가지고 있는 주제다.
내부함수는 외부함수의 지역변수에 접근 할 수 있는데
외부함수의 실행이 끝나서 외부함수가 소멸된 이후에도
내부함수가 외부함수의 변수에 접근 할 수 있다.
이러한 메커니즘을 클로저라고 한다.
function outter(){
**var** title = 'coding everybody';
**return** **function**(){
alert(title);
}
}
inner = outter();
inner();
결과 : coding everybody
=67번 영상===========================================
클로저 : private variable
다음은 클로저를 이용해 영화의 제목을 저장하고 있는 객체를 정의하고 있다.
function factory_movie(title){
**return** {
get_title : **function** (){
**return** title;
},
set_title : **function**(_title){
title = _title
}
}
}
ghost = factory_movie('Ghost in the shell');
matrix = factory_movie('Matrix');
alert(ghost.get_title()); → Ghost in the shell
alert(matrix.get_title()); → Matrix
ghost.set_title('공각기동대');
alert(ghost.get_title()); → 공각기동대
alert(matrix.get_title()); → Matrix
각각 자신이 실행된 시점에서의 title값에 접근한다.
private variable = 비밀변수.
private variable의 개념으로 title이란 변수를 안전하게 저장한 것이다.
=68번 영상===========================================
클로저 : 클로저의 응용
클로저 사용 시 주의점.
var arr = []
**for**(**var** i = 0; i < 5; i++){
arr[i] = **function**(){
**return** i;
}
}
**for**(**var** index **in** arr) {
console.log(arr[index]());
}
결과 : 5 5 5 5 5
- 설명이 이해가 되지 않았다. 다시 보자.
=69번 영상===========================================
arguments : arguments란?
arguments는 배열과 유사하지만, 배열은 아니다.
실제로는 arguments 객체의 인스턴스다.
function sum(){
**var** i, _sum = 0;
**for**(i = 0; i < arguments.length; i++){
document.write(i+' : '+arguments[i]+'<br />');
_sum += arguments[i];
}
**return** _sum;
}
document.write('result : ' + sum(1,2,3,4));
arguments의 자체적인 기능으로 인해
sum() 안에 몇 개의 인자가 담겨있는지 파악이 가능하다.
그렇기에 위 코드 실행 시, argument.length = 4 가 된다.
=70번 영상===========================================
arguments : function length
매개변수와 관련된 두가지 수가 있다.
하나는 함수.length, 다른 하나는 arguments.length이다.
arguments.length는 함수로 전달된 실제 인자의 수를 의미하고,
함수.length는 함수에 정의된 인자의 수를 의미한다.
function zero(){
console.log(
'zero.length', zero.length,
'arguments', arguments.length
);
}
function one(arg1){
console.log(
'one.length', one.length,
'arguments', arguments.length
);
}
function two(arg1, arg2){
console.log(
'two.length', two.length,
'arguments', arguments.length
);
}
zero(); // zero.length 0 arguments 0
one('val1', 'val2'); // one.length 1 arguments 2
two('val1'); // two.length 2 arguments 1
=71번 영상===========================================
함수의 호출 : apply 소개
https://opentutorials.org/module/532/6550
함수를 호출하는 가장 기본적인 방법이다
function func(){
}
func();
함수 func는 Function이라는 객체의 인스턴스다.
따라서 func는 객체 Function이 가지고 있는 메소드들을 상속하고 있다.
해당 영상에서 이야기하려는 메소드는 Function.apply과 Function.call이다
function sum(arg1, arg2){
**return** arg1+arg2;
}
alert(sum.apply(**null**, [1,2])) → 3
함수 sum은 Function 객체의 인스턴스다.
그렇기 때문에 객체 Function 의 메소드 apply를 호출 할 수 있다.
apply 메소드는 두개의 인자를 가질 수 있는데,
첫번째 인자는 함수(sum)가 실행될 맥락이다.
두번째 인자는 배열인데,
이 배열의 담겨있는 원소가 함수(sum)의 인자로 순차적으로 대입된다.
=72번 영상===========================================
함수의 호출 : apply의 사용
this는 호출할 때 결정된다.
o1 = {val1:1, val2:2, val3:3}
o2 = {v1:10, v2:50, v3:100, v4:25}
function sum(){
**var** _sum = 0;
**for**(name **in** **this**){ → 코드 실행 시, var this = o1 이 된다.
_sum += **this**[name];
}
**return** _sum;
}
alert(sum.apply(o1)) // 6
alert(sum.apply(o2)) // 185
=73번 영상===========================================
객체지향프로그래밍 : 오리엔테이션
https://opentutorials.org/module/532/6553
객체지향 프로그래밍(Object-Oriented Programming)
객체는 틀이다.
붕어빵을 만드는 틀과 같이 정해진 형태가 있으며,
틀에서 만들어진 붕어빵과 같이
객체 역시 자신과 같은 형태를 계속해서 찍어낼 수 있다.
=74번 영상===========================================
객체지향프로그래밍 : 추상화
좋은 객체를 만들기 위해서는 설계가 중요하다.
좋은 설계는 현실을 잘 반영해야 한다.
현실은 복잡하지만 그 복잡함 전체가 필요한 것은 아니다.
지하철 노선도를 떠올리면 간단하다.
노선도마냥 알기 쉽게하는 과정을 ‘추상화(abstract)’라고 한다.
=75번 영상===========================================
객체지향프로그래밍 : 부품화
객체 지향은 ‘부품화’의 정점이라고 할 수 있다.
배운 것 중에서 부품화의 특성을 보여줄 수 있는 기능을 생각해보자.
메소드는 부품화의 예라고 할 수 있다.
메소드를 사용하는 기본 취지는
연관되어 있는 로직들을 결합해서 메소드라는 완제품을 만드는 것이다.
그리고 이 메소드들을 부품으로 해서
하나의 완제품인 독립된 프로그램을 만드는 것이다.
메소드를 사용하면 코드의 양을 극적으로 줄일 수 있고,
메소드 별로 기능이 분류되어 있기 때문에
필요한 코드를 찾기도 쉽고 문제의 진단도 빨라진다.
=76번 영상===========================================
생성자와 new : 소개
https://opentutorials.org/module/532/6570
자바스크립트 = prototype-based programming.
자바스크립트의 객체 지향 사용법을 알아보자.
다른 언어와 사용법이 다르다고 하니 주의.
=77번 영상===========================================
생성자와 new : 객체생성
객체란 서로 연관된 변수와 함수를 그룹핑한 그릇이라고 할 수 있다.
객체 내의 변수를 프로퍼티(property) 함수를 메소드(method)라고 부른다.
객체를 만들어보자.
var person = {}
person.name = 'egoing';
person.introduce = **function**(){
**return** 'My name is '+**this**.name;
}
document.write(person.introduce()); → My name is egoing
이런 형태로 코드를 작성하다 보면 중복이 발생할 수 있다.
그것을 막기 위해서 생성자를 사용해야 한다.
=78번 영상===========================================
생성자와 new : 생성자와 new
생성자(constructor)는 객체를 만드는 역할을 하는 함수다.
자바스크립트에서 함수는 재사용 가능한 로직의 묶음이 아니라
객체를 만드는 창조자라고 할 수 있다.
생성자는 new를 사용한다.
function Person(){}
var p = new Person();
p.name = 'egoing';
p.introduce = **function**(){
**return** 'My name is '+this.name;
}
document.write(p.introduce());
자바스크립트에서 생성자는 소속이 없다.
생성자는 함수일 뿐이다.
자바스크립트에선 클래스라는 것이 없다.
다음은 생성자를 이용해 재사용성이 높은 코드를 작성한 것이다.
function Person(name){
**this**.name = name;
**this**.introduce = **function**(){
**return** 'My name is '+**this**.name;
}
}
var p1 = **new** Person('egoing');
document.write(p1.introduce()+"<br />");
var p2 = **new** Person('leezche');
document.write(p2.introduce());
생성자 내에서 이 객체의 프로퍼티를 정의하고 있다.
이러한 작업을 초기화(initalize)라고 한다.
이를 통해서 코드의 재사용성이 대폭 높아졌다.
코드를 통해서 알 수 있듯이 생성자 함수는
일반함수와 구분하기 위해서 첫글자를 대문자로 표시한다.
=79번 영상===========================================
전역객체
https://opentutorials.org/module/532/6577
전역객체(Global object)는 특수한 객체다.
모든 객체는 이 전역객체의 프로퍼티다.
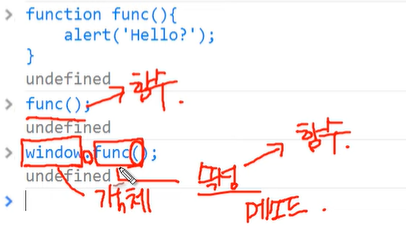
window는 전역 객체이다.
window.func()와 func()는 같은 명령이며 window는 생략하여 사용이 가능하다.
우리는 우리도 모르게 window를 사용하고 있었다.
=80번 영상===========================================
this : 함수와 this
https://opentutorials.org/module/532/6571
this는 함수 내에서 함수 호출 맥락(context)를 의미한다.
맥락이라는 것은 상황에 따라서 달라진다는 의미이다.
즉 함수를 어떻게 호출하느냐에 따라서
this가 가리키는 대상이 달라진다는 뜻이다.
this는 전역객체인 window와 같다.
function func(){
**if**(window === **this**){
document.write("window === this");
}
}
func(); →>> window === this
=81번 영상===========================================
this : 메소드와 this
객체의 소속인 메소드의 this는 그 객체를 가르킨다.
var o = {
func : **function**(){
**if**(o === **this**){
document.write("o === this");
}
}
}
o.func(); →>> o === this
=82번 영상===========================================
this : 생성자와 this
아래 코드는 함수를 호출했을 때와
new를 이용해서 생성자를 호출했을 때의 차이를 보여준다.
var funcThis = **null**;
function Func(){
funcThis = **this**;
}
var o1 = Func();
**if**(funcThis === window){
document.write('window <br />'); →>> window
}
var o2 = **new** Func();
**if**(funcThis === o2){
document.write('o2 <br />'); →>> o2
}
=83번 영상===========================================
this : 객체로서 함수
함수가 객체인 것에 대한 설명.
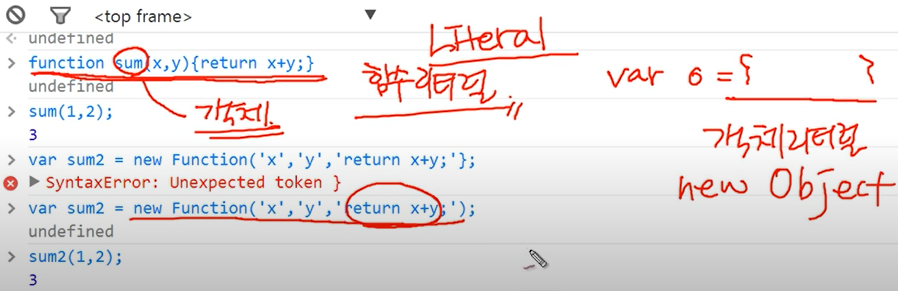
=84번 영상===========================================
this : apply와 this
함수의 메소드인 apply, call을 이용하면 this의 값을 제어할 수 있다.
var o = {}
var p = {}
function func(){
**switch**(**this**){
**case** o:
document.write('o<br />');
**break**;
**case** p:
document.write('p<br />');
**break**;
**case** window:
document.write('window<br />');
**break**;
}
}
func(); →>> window
func.apply(o); →>> o
func.apply(p); →>> p
=85번 영상===========================================
상속 : 상속이란?
https://opentutorials.org/module/532/6572
객체는 연관된 로직들로 이루어진 작은 프로그램이라고 할 수 있다.
상속은 객체의 로직을 그대로 물려 받는
또 다른 객체를 만들 수 있는 기능을 의미한다.
단순히 물려받는 것이라면 의미가 없을 것이다.
기존의 로직을 수정하고 변경해서 파생된 새로운 객체를 만들 수 있게 해준다.
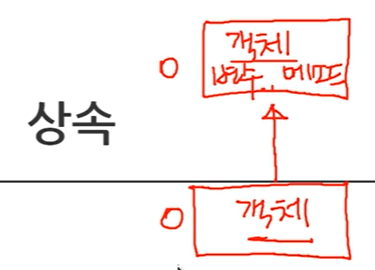
=86번 영상===========================================
상속 : 상속의 사용방법
function Person(name){ // 생성자
**this**.name = name;
}
Person.prototype.name=**null**;
Person.prototype.introduce = **function**(){
**return** 'My name is '+**this**.name;
}
function Programmer(name){ // 객체화
**this**.name = name;
}
Programmer.prototype = **new** Person(); // 상속
var p1 = **new** Programmer('egoing');
document.write(p1.introduce()+"<br />"); // 상속으로 introduce 사용 가능
=87번 영상===========================================
상속 : 기능의 추가
다음 코드에서 Programmer는 Person의 기능을 가지고 있으면서
Person이 가지고 있지 않은 기능인 메소드 coding을 가지고 있다.
function Person(name){
**this**.name = name;
}
Person.prototype.name=**null**;
Person.prototype.introduce = **function**(){
**return** 'My name is '+**this**.name;
}
function Programmer(name){
**this**.name = name;
}
Programmer.prototype = **new** Person();
Programmer.prototype.coding = **function**(){
**return** "hello world";
}
var p1 = **new** Programmer('egoing');
document.write(p1.introduce()+"<br />"); // my name is egoing
document.write(p1.coding()+"<br />"); // hello world
=88번 영상===========================================
prototype : prototype이란?
https://opentutorials.org/module/532/6573
prototype = 상속의 구체적인 수단이다.
prototype은 말 그대로 객체의 원형이라고 할 수 있다.
함수는 객체다. 그러므로 생성자로 사용될 함수도 객체다.
객체는 프로퍼티를 가질 수 있는데 prototype이라는 프로퍼티는
그 용도가 약속되어 있는 특수한 프로퍼티다.
prototype에 저장된 속성들은 생성자를 통해서
객체가 만들어질 때 그 객체에 연결된다.
function Ultra(){}
Ultra.prototype.ultraProp = **true**;
function Super(){}
Super.prototype = **new** Ultra();
function Sub(){}
Sub.prototype = **new** Super();
var o = **new** Sub();
console.log(o.ultraProp); // true
=89번 영상===========================================
prototype : prototype chain
위 코드에서 생성자 Sub를 통해서 만들어진 객체 o가
Ultra의 프로퍼티 ultraProp에 접근 가능한 것은
prototype 체인으로 Sub와 Ultra가 연결되어 있기 때문이다.
내부적으로는 아래와 같은 일이 일어난다.
- 객체 o에서 ultraProp를 찾는다.
- 없다면 Sub.prototype.ultraProp를 찾는다.
- 없다면 Super.prototype.ultraProp를 찾는다.
- 없다면 Ultra.prototype.ultraProp를 찾는다.
prototype는 객체와 객체를 연결하는 체인의 역할을 하는 것이다.
이러한 관계를 prototype chain이라고 한다.
=90번 영상===========================================
표준 내장 객체의 확장 : 표준 내장 객체란?
https://opentutorials.org/module/532/6475
표준 내장 객체(Standard Built-in Object)는
자바스크립트가 기본적으로 가지고 있는 객체들을 의미한다.
내장 객체가 중요한 이유는 프로그래밍을 하는데
기본적으로 필요한 도구들이기 때문에다.
자바스크립트는 아래와 같은 내장 객체를 가지고 있다.
- Object
- Function
- Array
- String
- Boolean
- Number
- Math
- Date
- RegExp
=91번 영상===========================================
표준 내장 객체의 확장 : 배열의 확장1
배열을 확장해보자.
아래 코드는 배열에서 특정한 값을 랜덤하게 추출하는 코드다.
var arr = **new** Array('seoul','new york','ladarkh','pusan', 'Tsukuba');
function getRandomValueFromArray(haystack){
**var** index = Math.floor(haystack.length*Math.random());// 스택길이x난수
**return** haystack[index];
}
console.log(getRandomValueFromArray(arr)); // 배열 중 랜덤으로 하나 출력
=92번 영상===========================================
표준 내장 객체의 확장 : 배열의 확장2
prototype을 사용해 위와 같은 것을 구현.
가독성이 더 좋아졌다.
Array.prototype.rand = **function**(){
**var** index = Math.floor(**this**.length*Math.random());
**return** **this**[index];
}
var arr = **new** Array('seoul','new york','ladarkh','pusan', 'Tsukuba');
console.log(arr.rand()); // 배열 중 랜덤으로 하나 출력
=93번 영상===========================================
Object : Object란?
https://opentutorials.org/module/532/6578
Object 객체는 객체의 가장 기본적인 형태를 가지고 있는 객체이다.
다시 말해서 아무것도 상속받지 않는 순수한 객체다.
자바스크립트에서는 값을 저장하는 기본적인 단위로 Object를 사용한다.
**var**grades = {'egoing': 10, 'k8805': 6, 'sorialgi': 80};
동시에 자바스크립트의 모든 객체는 Object 객체를 상속 받는데,
그런 이유로 모든 객체는 Object 객체의 프로퍼티를 가지고 있다.
=94번 영상===========================================
Object : Object API
object 객체의 메뉴얼 읽는 법.
다음 페이지에서 원하는 객체를 찾아 읽고 사용.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference
ex) 메뉴얼 예시
Object.key() 페이지.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/keys
Object.prototype.toString() 페이지
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/toString
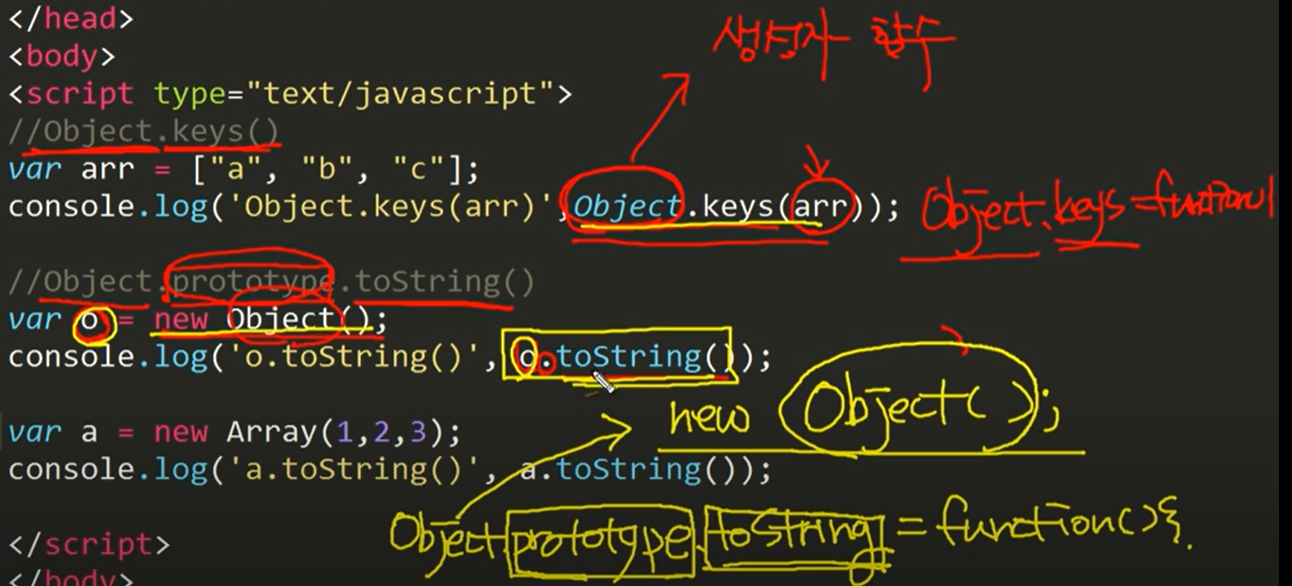
p.s) specification 란에서 버전 확인 가능.
명시된 버전에서만 객체 사용 가능.
=95번 영상===========================================
Object : Object 확장
object, prototype 으로 배열에 포함된 문자 찾기 기능 제작.
Object.prototype.contain = **function**(neddle) {//needle:바늘찾기로 작명
**for**(**var** name **in** **this**){
**if**(**this**[name] === neddle){
**return** **true**;
}
}
**return** **false**;
}
var o = {'name':'egoing', 'city':'seoul'}
console.log(o.contain('egoing')); // true
var a = ['egoing','leezche','grapittie'];
console.log(a.contain('leezche')); // true
=96번 영상===========================================
Object : Object 확장의 위험
위 코드와 같은 확장은 위험하다.
모든 코드에 영향을 주기 때믄이다.
따라서 해당사용법에는 주의를 기울여야 한다.
**for**(var name **in** o){
console.log(name);
} // name
contain
객체가 기본적으로 가지고 있을 것으로 예상하고 있는 객체 외에
다른 객체를 가지고 있는 것은 개발자들에게 혼란을 준다.
이 문제를 회피하기 위해서는 프로퍼티의 해당 객체의 소속인지를
체크해볼 수 있는 hasOwnProperty를 사용하면 된다.
**for**(**var** name **in** o){
**if**(o.hasOwnProperty(name))
console.log(name);
}
hasOwnProperty는 인자로 전달된 속성의 이름이
객체의 속성인지 여부를 판단한다.
만약 prototype으로 상속 받은 객체라면 false가 된다
.
=97번 영상===========================================
데이터 타입 : 원시 데이터 타입과 객체
https://opentutorials.org/module/532/6579
데이터 타입이란 데이터의 형태를 의미한다.
데이터 타입은 크게 두가지로 구분할 수 있다.
객체와 객체가 아닌 것.
객체 데이터 타입 vs 원시 데이터 타입(primitive)
객체가 아닌 것 = 원시 데이터 타입
- 숫자
- 문자열
- 불리언(true/false)
- null
- undefined
=98번 영상===========================================
데이터 타입 : 래퍼 객체
래퍼 객체.
var str = 'coding';
console.log(str.length); // 6
console.log(str.charAt(0)); // "C"
문자열은 분명히 프로퍼티와 메소드가 있다.
그렇다면 객체다.
그런데 왜 문자열이 객체가 아니라고 할까?
그것은 내부적으로 문자열이 원시 데이터 타입이고
문자열과 관련된 어떤 작업을 하려고 할 때
자바스크립트는 임시로 문자열 객체를 만들고
사용이 끝나면 제거하기 때문이다.
var str = 'coding';
str.prop = 'everybody';
console.log(str.prop); // undefined
tr.prop를 하는 순간에 자바스크립트 내부적으로 String 객체가 만들어진다.
prop 프로퍼티는 이 객체에 저장되고 이 객체는 곧 제거 된다.
그렇기 때문에 prop라는 속성이 저장된 객체는 존재하지 않게된다.
이러한 특징은 일반적인 객체의 동작 방법과는 다르다.
하지만 문자열과 관련해서 필요한 기능성을
객체지향적으로 제공해야 하는 필요 또한 있기 때문에
원시 데이터 형을 객체처럼 다룰 수 있도록 하기 위한 객체를
자바스크립트는 제공하고 있는데 그것이 레퍼객체(wrapper object)다.
=99번 영상===========================================
참조 : 복제란?
https://opentutorials.org/module/532/6507
전자화된 시스템의 가장 중요한 특징은 복제다.
현실의 사물과 다르게 전자화된 시스템 위의 데이터를
복제 하는데는 비용이 거의 들지 않는다.
이 특징이 소프트웨어를 기존의 산업과 구분하는 가장 큰 특징일 것이다.
프로그래밍에서 복제가 무엇인가를 살펴보자.
var a = 1;
var b = a;
b = 2;
console.log(a); // 1
=100번 영상===========================================
참조 : 참조
그런데 자연의 산물이 아니라 거대한 약속의 집합인
소프트웨어의 세계에서 당연한 것은 없다.
이것이 당연하지 않은 이유는 다음 예제를 통해서 좀 더 분명하게 드러난다.
var a = {'id':1};
var b = a;
b.id = 2;
console.log(a.id); // 2
변수 b에 담긴 객체의 id 값을 2로 변경했을 뿐인데 a.id의 값도 2가 되었다.
이것은 변수 b와 변수 a에 담긴 객체가 서로 같다는 것을 의미하다.
이것은 참조(reference)로 인한 결과이다.
비유하자면 복제는 파일을 복사하는 것이고
참조는 심볼릭 링크(symbolic link) 혹은
바로가기(윈도우)를 만드는 것과 비슷하다.
원본 파일에 대해서 심볼릭 링크를 만들면
원본이 수정되면 심볼릭 링크에도
그 내용이 실시간으로 반영되는 것과 같은 효과다.
다시 말해서 원본을 복제한 것이 아니라
원본 파일을 참조(reference)하고 있는 것이다.
덕분에 저장 장치의 용량을 절약할 수 있고,
원본 파일을 사용하고 있는 모든 복제본이 동일한 내용을 유지할 수 있게 된다.
a = 1;
a = {'id':1};
전자는 데이터형이 숫자이고 후자는 객체다.
숫자는 원시 데이터형(기본 데이터형, Primitive Data Types)이다.
자바스크립트에서는 원시 데이터형을 제외한 모든 데이터 타입은 객체이다.
객체를 다른 말로는 참조 데이터 형(참조 자료형)이라고도 부른다.
기본 데이터형은 위와 같이 복제 되지만 참조 데이터형은 참조된다.
모든 객체는 참조 데이터형이다.
=101번 영상===========================================
참조 : 함수와 참조
일종의 변수할당이라고 할 수 있는 메소드의 매개변수는
어떻게 동작하는가를 살펴보자.
다음은 원시 데이터 타입을 인자로 넘겼을 때의 동작 모습이다.
var a = 1;
function func(b){
b = 2;
}
func(a);
console.log(a); // 1
다음은 참조 데이터 타입을 인자로 넘겼을 때 동작하는 장면이다.
var a = {'id':1};
function func(b){
b = {'id':2};
}
func(a);
console.log(a.id); // 1
함수 func의 파라미터 b로 전달된 값은 객체 a이다.
(b = a) b를 새로운 객체로 대체하는 것은 (b = {‘id’:2})
b가 가르키는 객체를 변경하는 것이기 때문에 객체 a에 영향을 주지 않는다.
하지만 다음은 다르다.
var a = {'id':1};
function func(b){
b.id = 2;
}
func(a);
console.log(a.id); // 2
파라미터 b는 객체 a의 레퍼런스다.
이 값의 속성을 바꾸면 그 속성이 소속된 객체를 대상으로
수정작업을 한 것이 되기 때문에 b의 변경은 a에도 영향을 미치게 된다.
시간나면 다음 영상을 참조하라.
코드와 오픈소스 :
https://opentutorials.org/course/1189/6340
=102번 영상===========================================
수업을 마치며.
1.코드는 양면테이프와 같다.
부품과 부품을 이어붙여 편의성을 도모할 수 있다.
하지만 이제는 테이프에서 벗어나 부품 그 자체에도 주의를 기울여야 한다.
2.문법을 많이 알아둬야 한다.
다른 사람의 코드를 이해하기 쉬워지고 실력향상에 도움이 된다.
3.가장 본질적인 언어 하나를 붙잡고 결과물을 만들어라.
본질적인 언어란 단순히 절차에 따라 사건이 일어나게 하는 것이다.
끝.
R 통계분석
***해당 글은 “R을 이용한 공공데이터 분석”책의 8장을 정리한 글입니다.
[ 1. 분석 방법 ]
기술 통계
- 평균, 최솟값, 최댓값, 중앙값과 같이 데이터의 특징을 알려주는 값
- 기술통계는 Descriptive statistic
추론 통계
- 변수 간의 관계를 파악하고, 변수간의 인과관계 또는 새로운 사실을 밝혀냄
- 평균 차이 검정, 교차 분석, 상관관계분석, 회귀분석
평균차이 검정
- 집단별로 평균의 차이가 실제로 있는가 검정
- 독립표본 T검정
교차분석
- 범주형 변수로 구성된 집단들의 관련성을 검정하는 통계 분석
- 교차분석은 카이제곱(x^2)검정, 카이스퀘어검정, 독립성 검정이라고도 함
상관관계분석
- 상관관계분석은 변수 간의 상관관계(correlation)를 알아보는 것
- 변수간의 연관성
- 한 변수가 변화하면 다른 변수도 변화하는 관계
- 방향은 한 변수가 변화할 때 다른 변수가 같은 방향으로 변화하는지, 반대 방향으로 변화하는지를 의미
- 변화의 강도와 방향을 나나나는 계수가 상관계수(r)
- 상관계수는 -1~1 사이에 있으며, 수치가 클수록 영향을 주는 강도가 크다
- ‘+’는 ‘정의 관계’, ‘-‘는 ‘부의 관계’ 또는 ‘역의 관계’에 있는 것을 의미
- 상관관계 : -1 <= r <= 1
회귀분석
- 상관관계로는 변수들의 관계를 알 수 있지만, 인과관계는 알 수 없음
- 인과관계는 원인과 결과의 관계. 한 변수가 다른 변수에 영향을 주는 것
- 영향을 주는 변수는 독립변수(independent variable)이고,
영향을 받는 변수는 종속변수(dependent variable)이다 - 독립변수와 종속변수 간의 인과관계를 분석하는 통계적 방법을
회귀분석(regression analysis)이라고 한다 - “월급이 증가하면 외식횟수가 늘어날 것”이라고 가정하면, 월급은 독립변수이고 외식횟수는 종속변수이다
- 월급의 증감이 외식횟수에 미치는 영향을 확률적으로 분석하는 것이 회귀분석
- 회귀분석에서 독립변수가 1개이면 단순회귀분석, 2개 이상이면 다중회귀분석이라고 함
- 다중회귀분석은 종속 변수는 1개이며 독립변수가 복수인 경우
- 복수의 독립변수들이 종속변수에 영향을 주는 정도를 분석하는 것
[ 2. 통계 검정 ]
가설
- 가설(hypothesis)은 어떤 현상을 설명하기 위해 가정하는 명제
- 증명되지 않은 추정
- 가설에는 귀무가설과 대립가설이 있다
- 귀무가설은 설정한 가설이 맞을 확률이 극히 적어서 처음부터 기각될 것으로 예상되는 가설
- 대립가설은 귀무가설이 기각될 경우 받아들여지는 가설이며, 연구자가 검정하고자 하는 가설
- 통계 검정은 통계적인 방법을 이용해서 대립가설이 맞는가를 검정하는 것
- 두 집단의 평균 차이가 있는가를 알아보려 할 때, 귀무가설은 ‘평균 차이가 없다’이며, 대립 가설은 ‘평균 차이가 있다’이다.
유의수준
- 가설검정의 결과는 유의수준에 의하여 결정
- 유의수준(significance level)은 귀무가설이 맞는데도 대립가설을 체택할 확률
- 즉 오류를 범할 확률. 차이가 없는 데도 있다고 할 확률이다
- 통계 분석에서는 p-value(p값)f로 제시
- p값이 0.01이라면 오류를 범할 확률이 1%라는 의미
- 현실적으로 오류는 존재할 수 밖에 없기에, ‘허용할 수 있는 오류 범위’를 설정
- 유의수준 5%는 오류를 5%까지 허용하겠다는 의미
- 허용하는 유의수준의 범위와 정확성은 반대의 개념
- 유의수준의 범위가 넓으면 연구 결과를 얻기가 쉽지만 결과의 정확성이 떨어진다
- 통계분석을 하면 결과물에는 유의수준(p-value)이 적혀있다
- 통계 분석 결과를 해석할 때는 먼저 유의수준이 0.05 이내인가를 보고, 결과가 통계적으로 유의미한지를 판단해야 한다
- 유의수준이 0.05 이상인데도 결과가 유의미하다고 해석하면 매우 심각한 오류.
- 유의수준의 반대 개념은 신뢰수준(confidence level). 신뢰할 수 있는 범위를 의미.
- 유의수준 5% 이내라고 하면 신뢰수준은 95%
척도
- 척도(scale)는 측정도구이며, 수치로 표시된다
- 척도에는 명목척도, 서열척도, 등간척도, 비율척도 등 네 종류가 있다
- 명목척도 : 측정대상의 특성이나 범주를 구분하는 수치. 운동선수의 번호를 생각하면 파악하기 쉽다.
번호는 특정 선수를 의미. 성을 분류할 때 통상 남자를 1번, 여자를 2번으로 분류하는 것과 같이
결혼유무, 종교, 인종, 지역, 계절 등을 표시할 때도 이용된다. 산술연산을 할 수 없다. - 서열척도 : 계급, 사회계층, 자격등급 등과 같이 측정대상의 등급순위를 나타내는 척도. 척도 간의 거리나 간격은 나타내지 않는다. 산술연산을 할 수 없다.
- 등간척도 : 측정대상을 일정한 간격으로 구분한 척도이다. 서열뿐만 아니라 거리와 간격도 표시한다.
온도, 학력, 시험점수 등. 덧셈과 뺄셈이 가능. - 비율척도 : 측정대상을 비율로 나타낼 수 있는 척도. 연령, 무게 등. 모든 수로 측정할 수 있어
4칙 연산이 가능.
[ 3. 통계 분석 사례 ]
두 집단의 평균 차이 검정
남녀 등 두 집단의 평균 차이를 분석할 때는 독립표본 t검정을 한다
R에서는 내장된 t.test()함수로 한다
독립변수는 명목척도이며, 종속변수는 등간척도 또는 비율척도이어야 한다.
t.test()함수 사용 방식은 2가지
방법1. t.test(data=데이터세트,종속변수(비교값) ~ 독립변수(비교대상))
방법2. t.test(데이터세트$종속변수(비교값) ~ 데이터세트$독립변수(비교대상))예제파일인 mpg1.csv의 trans변수에는 기어변속방법으로 auto(자동식)와 manual(수동식)등 두 방식이 있다.
두 방식에 cty 평균에 통계적으로 유의미한 차이가 있는지 알아보자.
cty는 도시에서 1갤런당 달리는 거리.
독립변수는 trans이며, 종속변수는 cty이다.
가설은 다음과 같이 설정한다.- 귀무가설(H0) : auto와 manual의 cty평균은 차이가 없다.
- 대립가설(H1) : auto와 manual의 cty평균은 차이가 있다.
1 | mpg1 <- read.csv("mpg1.csv") |
1 | ## |
- 결과를 보면 p-value=1.263e-05 임을 알 수 있으며 이 값은 1.263/100000 < 0.05 이다.
유의수준이 0.05보다 적기 때문에 유의수준 허용조건(p<.05)을 총종한다.
결과의 ‘alternative hypothesis : true difference in means is not equal to 0’는
‘대립가설 : 평균 차이가 있다’ 라는 의미.
교차분석
교차분석은 범주형 변수들이 관계가 있다는 것을 입증하는 것
평균의 차이가 아니라, 비율에 차이가 있는지를 검정
교차분석 검정은 R의 chisq.test() 함수 사용
mpg1.csv를 mpg1로 불러온다. mpg1에 있는 trans(기어 변속방식)변수의 범주에 따라 drv(구동방식)
범주의 비율에 차이가 있는가를 알아본다. 연구가설은 다음과 같이 설정.- 귀무가설(H0) : trans에 따라 drv의 차이가 없다.
- 대립가설(H1) : trans에 따라 drv의 차이가 있다.
우선 table() 함수와 prop.table()함수로 교차분석을 해서 trans에 따른 drv의 빈도와 비율을 알아본다.
1 | mpg1 <- read.csv("mpg1.csv", stringsAsFactors = F) |
1 | ## |
1 | prop.table(table(mpg1$trans, mpg1$drv),1) # auto와 manual의 drv 비율 분석 |
1 | ## |
auto에서는 4륜구동(4)인 47.8%로 가장 많고, manual에서는 전륜구동(f)이 53.2%이 가장 많아서
trans에 따라 drv에 차이가 있는 것 같다. 이에 대해 정말 그런지, 통계적으로 분석하는 것이 교차분석이다.방법 1
1 | chisq.test(mpg1$trans, mpg1$drv) |
1 | ## |
- 방법 2
1 | chisq.test(table(mpg1$trans, mpg1$drv)) |
1 | ## |
- 방법 3
1 | summary(table(mpg1$trans, mpg1$drv)) |
1 | ## Number of cases in table: 234 |
- 방법 1의 결과를 보면 유의수준(p-value)이 0.2084 > 0.5 이다. 대립가설을 기각하지 못하므로
trans에 따라 drv에 차이가 있다고 할 수 없다. 다른 방법에서도 같은 결과.
상관관계분석
- 상관관계분석은 R에 내장되어 있는 cor.test()함수로 한다
1 | #cor.test(데이터세트$비교변수1, 데이터세트$비교변수2) |
mpgl에는 cty와 hwy가 있다
cty는 도시에서 1갤런당 달리는 거리
hwy는 고속도로에서 1갤런당 달리는 거리
cty가 길면 hwy도 길 것이라 생각할 수 있다. 이 가설을 검정해본다.
검정하려는 가설은 cty와 hwy는 서로 상관관계가 있다는 것이기 때문에 이것이 대립가설.
귀무가설은 상관관계가 없다는 것이다.- 귀무가설(H0) : cty와 hwy는 상관관계가 없다.
- 대립가설(H1) : cty와 hwy는 상관관계가 있다.
1 | mpg1 <- read.csv("mpg1.csv", stringsAsFactors = F) |
1 | ## |
결과를 보면 ‘p-value < 2.2e-15’이다. 유의수준이 2.2/10^16보다 작다.
유의수준(p<.05)안에 있다. 이 검정의 결과로 귀무가설을 기각하고 대립가설을 채택할 수 있다.
대립가설은 “상관관계는 0이 아니다(alternative hypothesis: true correlation is not equal to 0)”결과의 sample estimates: 부분을 보면 상관관계는 0.9959159. 1에 가까우므로 매우 높다.
결과는 “cty와 hwy는 유의미하게 매우 높은 상관관계(r=.96)에 있다(p>.05)”
회귀분석
단순회귀분석
- 단순회귀분석은 독립변수가 1개, 종속변수가 1개일때 한다
- 회귀분석의 변수는 독립변수와 종속변수가 모두 등간척도 또는 비율척도이어야 한다
- 회귀분석은 R의 lm() 함수로 한다
1 | #다음 3가지 중 어느 것을 써도 된다. |
R에 있는 mtcars 데이터로 분석한다. R에서 help(mtcars)를 하면 mtcars에 관한 정보를 알 수 있다.
어느 한 미국 잡지에 실렸던 데이터이며, 11개 변수에서 32개 자동차의 정보를 담고 있다.
11개의 변수 가운데 disp(배기량)가 mpg(1갤런당 주행 마일)에 미치는 여향을 분석해본다.
str(mtcars)로 mtcars에 있는 변수들을 보면, disp와 mpg는 모두 실수형(num)변수이어서 회귀분석이 가능하다.- 귀무가설(H0) : disp는 mpg에 영향을 주지 않는다.
- 귀무가설(H1) : disp는 mpg에 영향을 준다.
1 | lm(data=mtcars, mpg~disp) |
1 | ## |
1 | #lm(mpg~disp, data=mtcars), lm(mtcars$mpg~mtcars$disp)의 결과도 같다. |
- 결과의 Coefficients 부분을 보면 disp의 계수(Coefficients)는 -0.04122이며, 절편은 29.59985이다.
단순회귀분석은 1차 함수를 구하는 것과 같다.
이 회귀분석에서 구해진 식은 mpg는 0.04122씩 감소한다.
이제 유의수준을 알아봐야 한다. lm()의 결과를 summary()함수에 넣으면 상세한 결과를 확인 가능.
1 | RA <- lm(data=mtcars, mpg~disp) #회귀분석 결과를 RA에 넣기 |
1 | ## |
- 결과의 맨 밑줄을 확인하면 통계분석을 한 회귀모형이 적합한가를 순석하는 값이 있다.
- p-value가 .05보다 작으면 회귀모형이 적합하다고 해석한다.
- p-value가 .05보다 크면 회귀모형에 문자가 있는 것이므로 회귀분석 자체가 성립하지 않는다.
- 이 분석에서는 p-value가 9.38e-10이므로 회귀모형이 적합하다.
다중회귀분석
- 다중회귀분석은 종속변수에 영향을 주는 독립변수가 복수일 때 분석하는 방식이다.
- 여러 독립변수들은 서로 영향을 주면서 종속변수에 영향을 주기 때문에
한 독립변수가 종속변수에 미치는 영향력은 단순회귀분석을 했을 때와 다중회귀 분석을 했을 때에 달라진다. - 다중회귀분석에서는 단순회귀분석의 독립변수들을 ‘+’기호로 연결한다.
1 | #방법1 lm(data=데이터세트, 종속변수~독립변수1+독립변수2+...) |
- mtcars 데이터로 실습한다. mpg에는 disp(배기량)이외에도 hp(마력)와 wt(중량)가 영향을 미칠 수 있다.
세 독립변수가 mpg에 어떤 영향을 주는지 알아본다.
1 | lm(data=mtcars, mpg~disp+hp+wt) |
1 | ## |
1 | #lm(mpg~disp+hp+wt, data=mtcars), |
- 결과의 Coefficients 부분을 보면 세 독립변수의 회귀계수가 있다.
다중회귀식은 mpg = 37.105505 - 0.000937 x disp - 0.0311157 x hp - 0.3800891 x wt이다.
그러나 세 독립변수의 회귀계수에 대한 유의수준이 없어서 회귀계수가 유의미한지 알 수 없다.
summary()함수로 유의수준을 비롯한 상세 결과를 알아본다.
1 | RA <- lm(data=mtcars, mpg~disp+hp+wt) #회귀분석 결과를 RA 녛기 |
1 | ## |
결과의 맨 밑줄을 확인하면 p값은 86e-11로 유의수준 .001보다 작아 회귀모형은 적합하다
Coefficients 부분을 보면 각각의 유의수준은 disp는 (p>.05), hp는 (p<.05), wt는 (p<.01)이다
disp는 mpg에 영향을 주지 않고, hp와 wt만 영향을 준다
결과의 Adjusted R-squared 는 0.8083으로 높아서 회귀모델의 설명력이 높다
위 내용들을 토대로 다음과 같이 적는다
- “회귀모형은 유의수준 p<.001에서 적합하며, 회귀식의 수정된 결정계수(R^2)는 .81이다.
3개 독립변수가 연비에 미치는 회귀계수(베타)는 hp가 -0.03(p<.05), wt가 -3.80(p<.01), disp는 없다.
wt의 영향력이 가장 컸다.”
- “회귀모형은 유의수준 p<.001에서 적합하며, 회귀식의 수정된 결정계수(R^2)는 .81이다.
Reference : R을 이용한 공공데이터 분석
End of Document
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick Start
Create a new post
1 | $ hexo new "My New Post" |
More info: Writing
Run server
1 | $ hexo server |
More info: Server
Generate static files
1 | $ hexo generate |
More info: Generating
Deploy to remote sites
1 | $ hexo deploy |
More info: Deployment
첫 번째 글입니다.
안녕하세요.
반갑습니다.