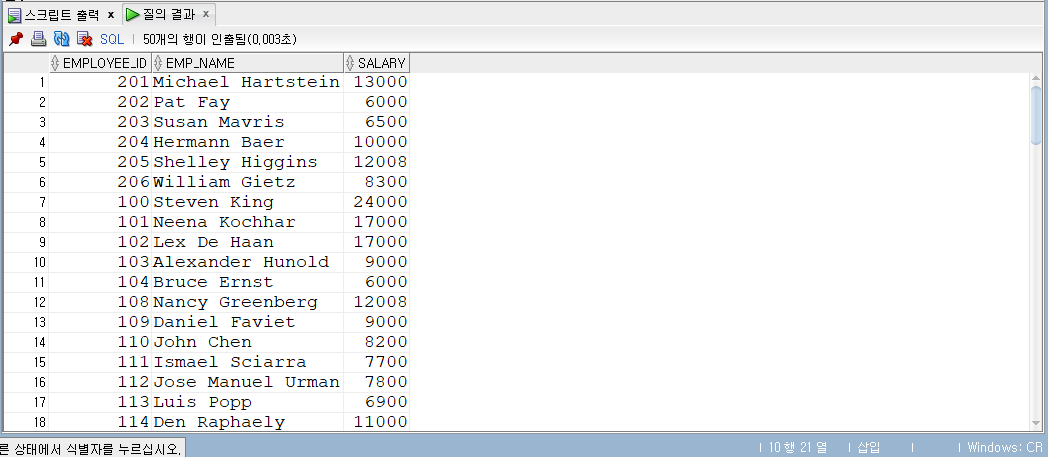
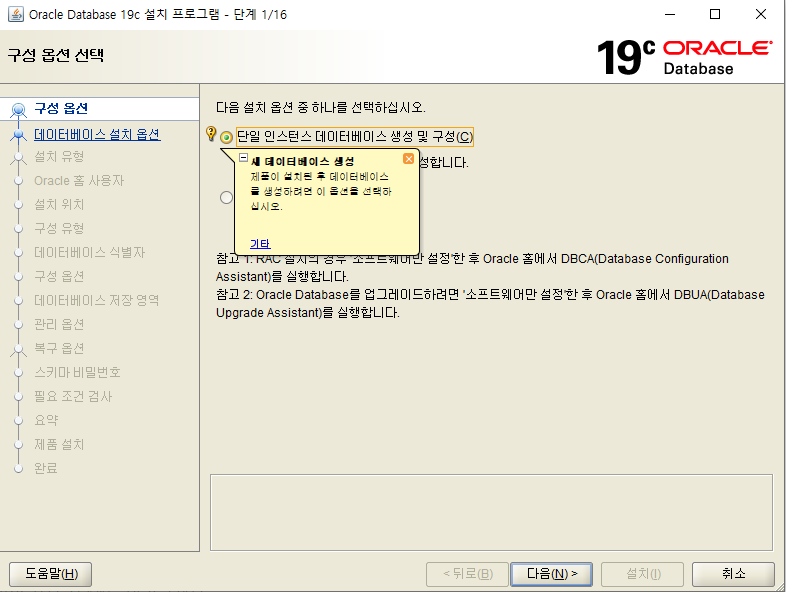
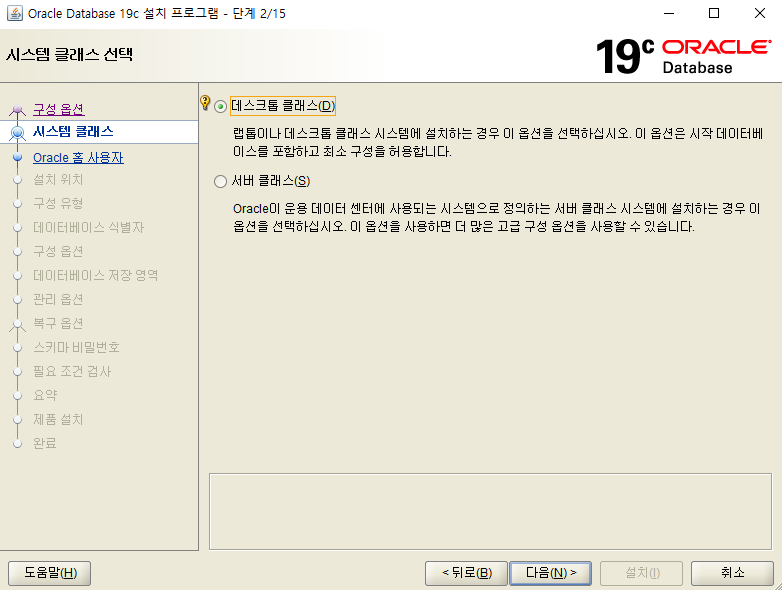
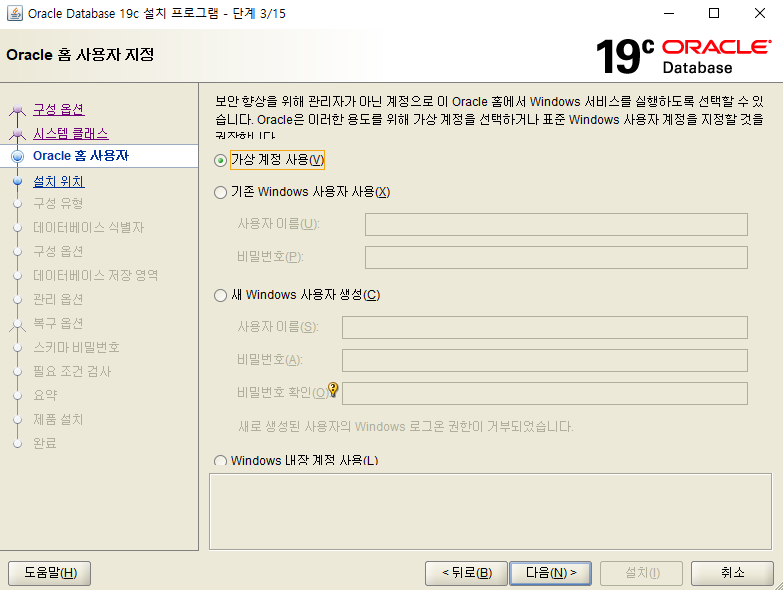
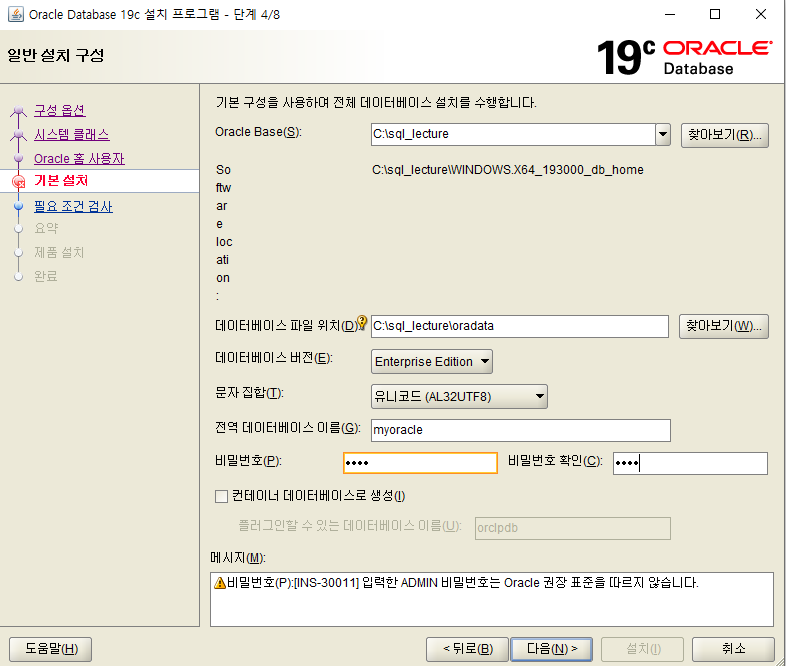
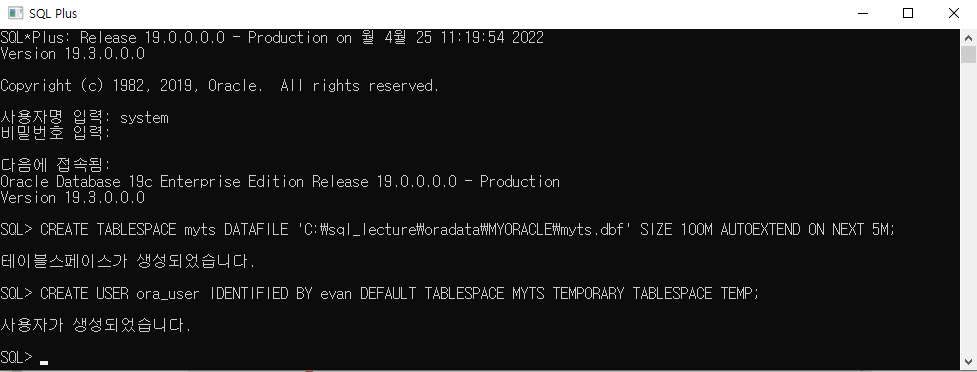
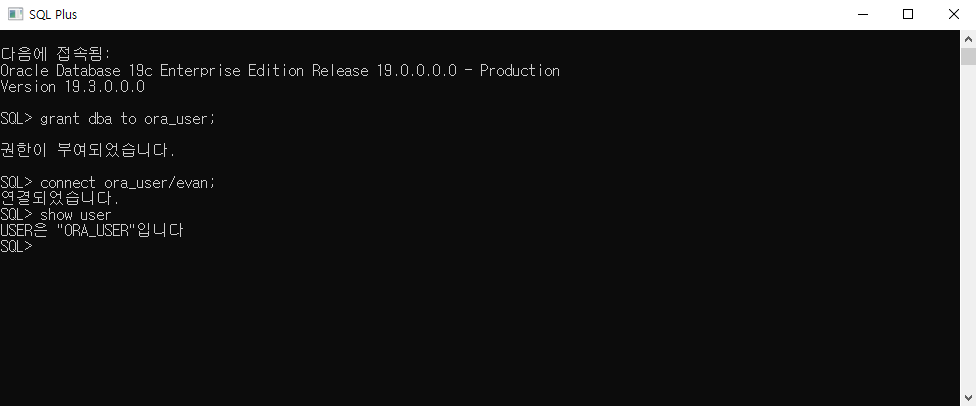
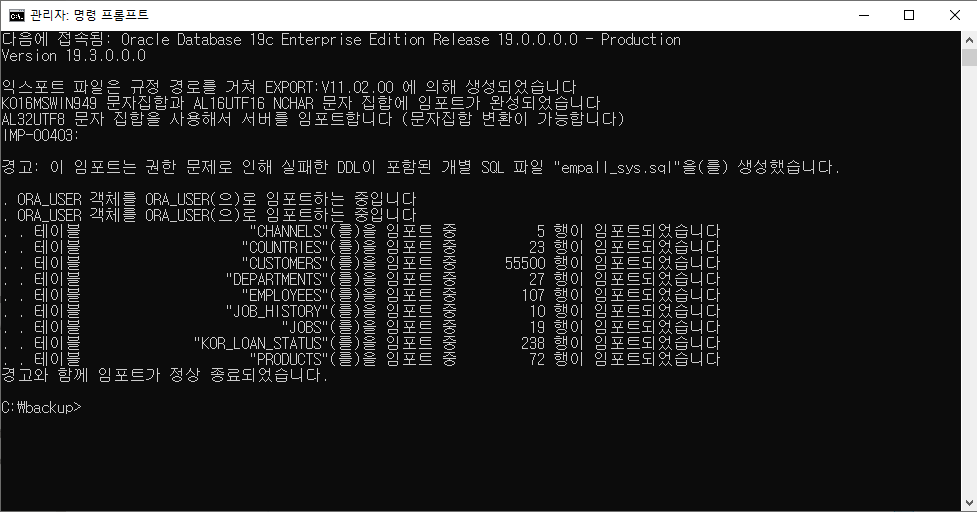
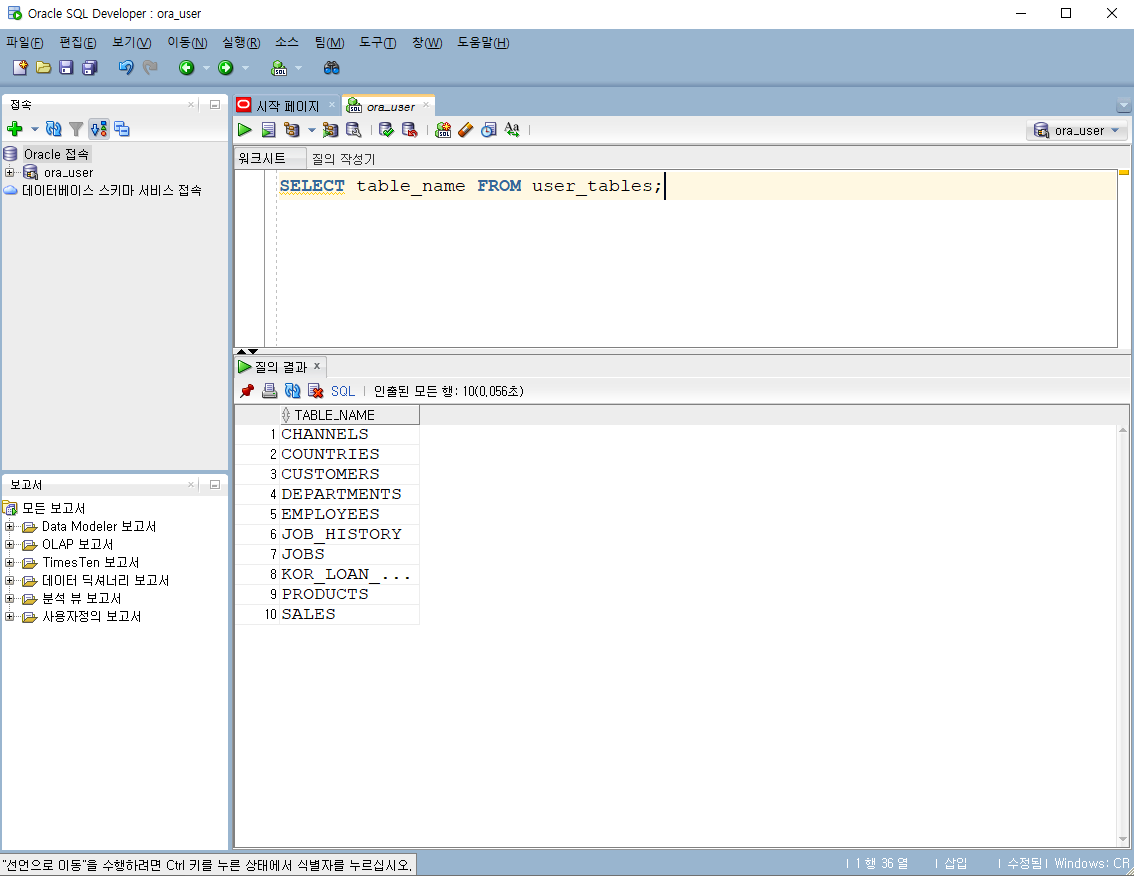
-- p.98 CREATETABLE ex3_2( emp_id NUMBER , emp_name VARCHAR2(100) );
-- 실무에서 많이 쓰임 INSERTINTO ex3_2(emp_id, emp_name) SELECT employee_id , emp_name FROM employees WHERE salary >5000;
SELECT*FROM ex3_2;
UPDATE 문 사용법
UPDATE : 기존 데이터를 수정
ARTER : 기존 테이블의 컬럼명 수정, 제약조건
1 2 3
UPDATE 테이블명 SET 컬럼1= 변경값1, 컬럼2= 변경값2 WHERE 조건;
UPDATE 문
UPDATE 문을 실제로 사용해보자.
1 2 3 4 5 6 7
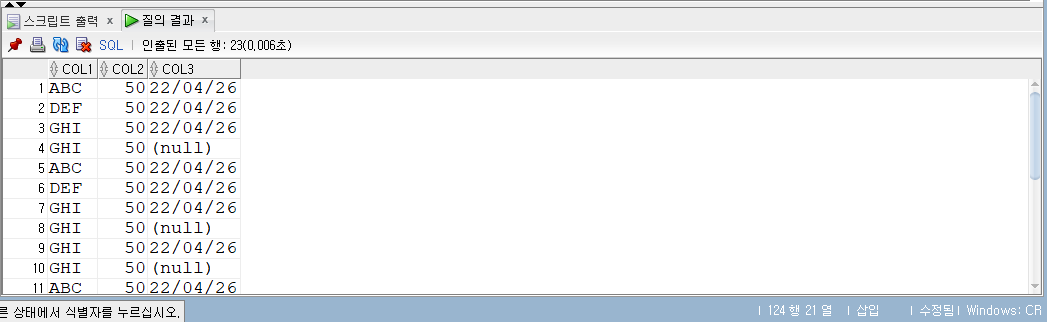
SELECT*FROM ex3_1;
-- col2 모두 50으로 변경한다. UPDATE ex3_1 SET col2 =50;
SELECT*FROM ex3_1;
col2 값이 모두 50으로 수정되었다.
SELECT문으로 사람 이름을 수정해보자.
1 2 3 4 5
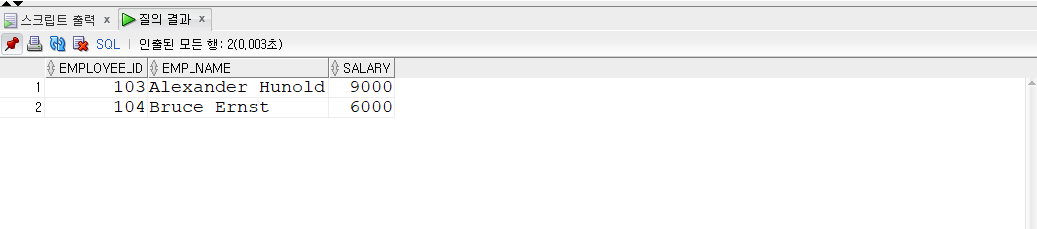
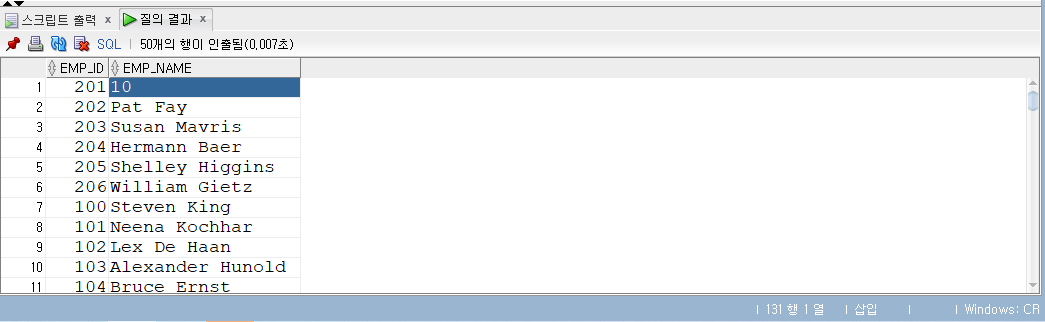
UPDATE ex3_2 SET EMP_NAME =10-- Michael Hartstein WHERE EMP_ID =201;
SELECT*FROM ex3_2;
Michael이란 이름이 10으로 변경되었다.
MERGE
조건 비교해서 테이블에 해당 조건에 맞는 데이터가 없으면 INSERT 있으면 UPDATE하는 방식이다.
1 2 3 4 5 6 7 8 9 10
MERGE INTO [스키마.]테이블명 USING (update나 insert될 데이터 원천) ON (update될 조건) WHEN MATCHED THEN SET 컬럼1 = 값1, 컬럼2 = 값2, ... WHERE update 조건 DELETE WHERE update_delete 조건 WHEN NOT MATCHED THEN INSERT (컬럼1, 컬럼2, ...) VALUES (값1, 값2,...) WHERE insert 조건;
-- MERGE -- 조건 비교해서 테이블에 해당 조건에 맞는 데이터가 없으면 INSERT -- 있으면 UPDATE
CREATETABLE ex3_3( employee_id NUMBER , bonum_amt NUMBER DEFAULT0 );
SELECT*FROM SALES; DESC SALES;
-- ex3_3 신규테이블 생성 INSERTINTO ex3_3(employee_id) SELECT e.employee_id FROM employees e, sales s WHERE e.employee_id = s.employee_id AND s.SALES_MONTH BETWEEN'200010'AND'200012' GROUPBY e.employee_id; -- group by를 통해 중복 제거
SELECT*FROM ex3_3 ORDERBY employee_id;
서브쿼리
쿼리 안에 또 다른 쿼리가 있는 형태이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- (1) 관리자 사번(manager_id)이 146번인 사원을 찾는다. -- (2) ex3_3 테이블에 있는 사원의 사번과 일치하면 -- 보너스 금액에 자신의 급여의 1%를 보너스로 갱신 -- (3) ex3_3 테이블에 있는 사원의 사번과 일치하지 않으면 -- (1)의 결과의 사원을 신규로 입력 (이 때 보너스 금액은 급여의 0.1% -- (4) 이 때 급여가 8000미만인 사원만 처리해보자.
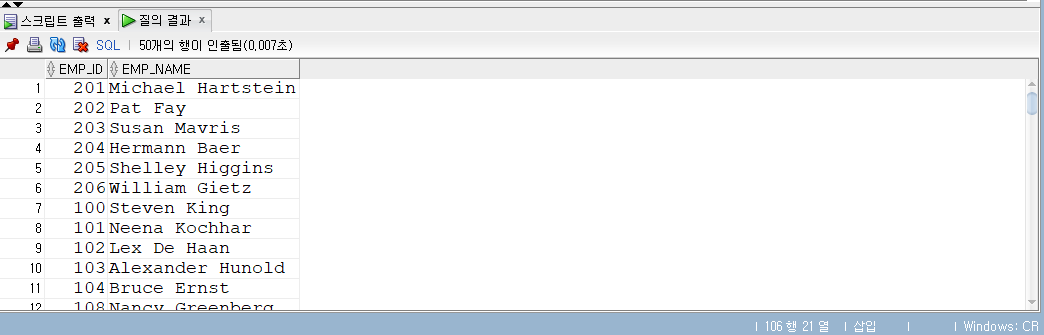
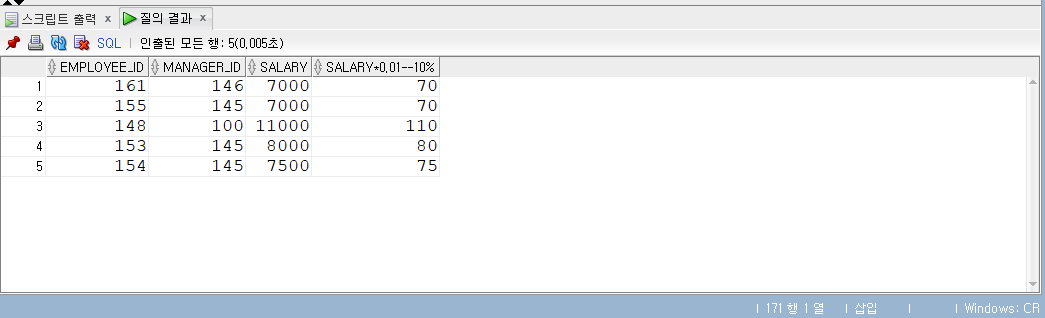
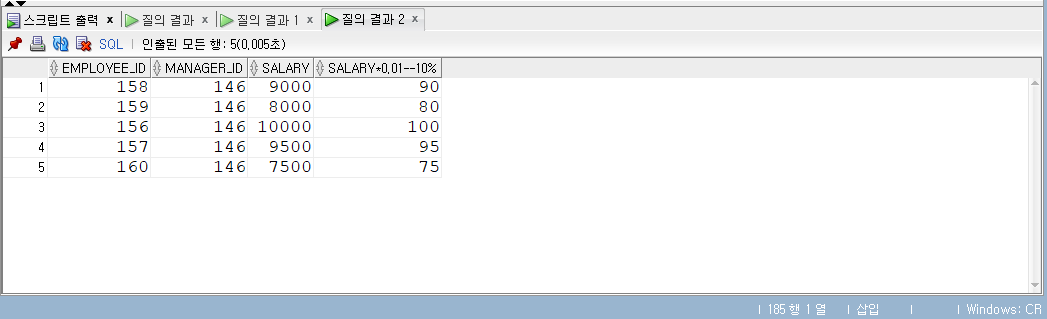
-- 서브쿼리 SELECT employee_id , manager_id , salary , salary *0.01-- 10% FROM employees WHERE employee_id IN (SELECT employee_id FROM ex3_3);
서브쿼리의 또 다른 예시이다.
1 2 3 4 5 6 7 8 9 10 11
-- 관리자 사번이 146번인 사원은 161번 사원 한 명이므로 -- ex3_3 테이블에서 161인 건의 보너스 금액은 7,000 * 0.01, 즉 70으로 갱신
SELECT employee_id , manager_id , salary , salary *0.01-- 10% FROM employees WHERE employee_id NOTIN (SELECT employee_id FROM ex3_3) AND manager_id =146;
MERGE 문
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
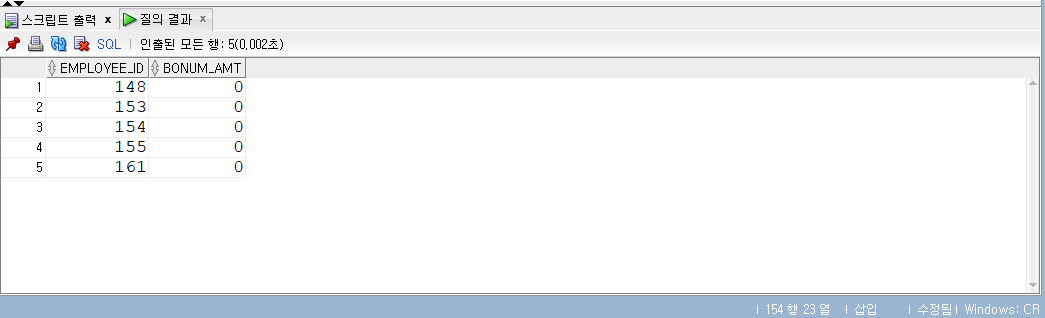
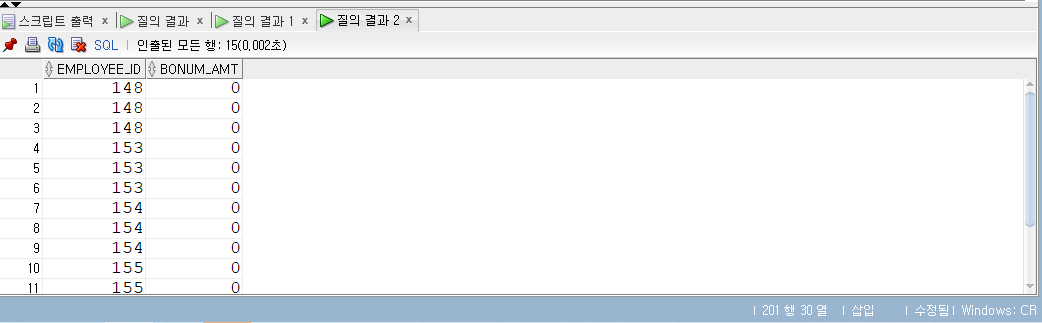
MERGEINTO ex3_3 d USING (SELECT employee_id , salary , manager_id FROM employees WHERE manager_id =146) b ON (d.employee_id = b.employee_id) WHEN MATCHED THEN UPDATESET d.bonus_amt = d.bonus_amt + b.salary *0.01 WHENNOT MATCHED THEN INSERT (d.employee_id, d.bonus_amt) VALUES (b.employee_id, b.salary *0.001) WHERE (b.salary <8000); SELECT*FROM ex3_3 ORDERBY employee_id;
오타 처리하다 3번 실행한 결과이다.
DELETE 문
UPDATE에 비해 간단하다.
삭제하기만 하면 되기 때문.
1 2 3 4
-- DELETE 문 -- 106p DELETE ex3_3; SELECT*FROM ex3_3;
COMMIT, ROLLBACK
commit과 rollback을 사용해보자.
1 2 3 4 5 6 7 8 9 10 11 12 13
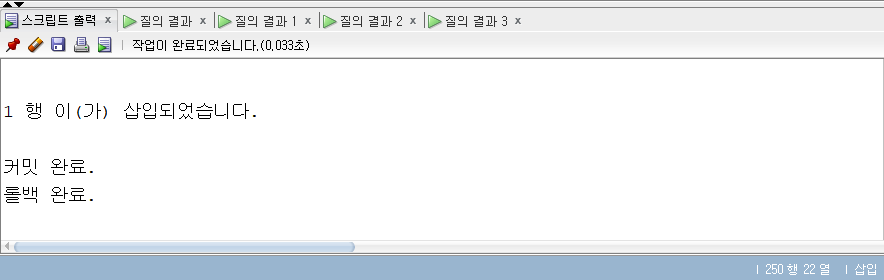
-- Commit Rollback Truncate -- Commit : 변경한 데이터를 DB에 마지막으로 반영 -- ROLLBACK : 반대로 변경한 데이터를 변경하기 이전 상태로 되돌림 CREATETABLE ex3_4 ( employee_id NUMBER ); INSERTINTO ex3_4 VALUES (100);
SELECT*FROM ex3_4;
commit; rollback;
commit 후에는, sqlplus에서도 테이블을 출력 할 수 있게 된다.
TRUNCATE문
한번 실행 시, 데이터 바로 삭제한다.
ROLLBACK 적용 안됨
1 2 3 4 5 6
-- TRUNCATE 문 -- 한번 실행시, 데이터 바로 삭제, ROLLBACK 적용 안됨 -- DELETE문은 데이터 삭제 후, COMMIT 필요 / ROLLBACK 데이터가 삭제되기 전의 복구 불가
SELECT constraint_name, constraint_type, table_name, search_condition FROM user_constraints WHERE table_name ='EX2_8'; INSERTINTO ex2_8 VALUES('','AA'); -- 오류 보고 ORA-01400: NULL을 ("ORA_USER"."EX2_8"."COL") 안에 삽입할 수 없습니다 -- NULL 값을 삽입하여 생기는 오류이다. NULL값 대신 다른 값을 입력하자.
여기까지 입력하고 실행하면 오류가 발생한다.
— 오류 보고 ORA-01400: NULL을 (“ORA_USER”.”EX2_8”.”COL”) 안에 삽입할 수 없습니다
NULL 값을 삽입하여 생기는 오류이다. NULL값 대신 다른 값을 입력하자.
1 2 3 4
-- 오류 보고 ORA-01400: NULL을 ("ORA_USER"."EX2_8"."COL") 안에 삽입할 수 없습니다 -- NULL 값을 삽입하여 생기는 오류이다. NULL값 대신 다른 값을 입력하자. INSERTINTO ex2_8 VALUES('AA','AA'); SELECT*FROM ex2_8;
이번에는 오류가 출력되지 않았다.
같은 값을 다시 입력해보자.
1 2 3 4
INSERTINTO ex2_8 VALUES('AA','AA'); -- ORA-00001: 무결성 제약 조건(ORA_USER.SYS_C007484)에 위배됩니다 -- 값이 같은 데이터를 입력하여 생기는 오류이다. 다른 데이터를 입력해야 한다.
-- 제약조건 추가 ALTERTABLE ex2_10 ADDCONSTRAINTS pk_ex2_10 PRIMARY KEY (col11);
-- USER CONSTRAINTS 제약 조건 확인 SELECT constraint_name, constraint_type, table_name, search_condition FROM user_constraints WHERE table_name ='EX2_10';
제약조건이 추가되었다.
제약조건을 삭제해보자.
1 2 3 4 5 6 7
-- 제약조건 삭제 ALTERTABLE ex2_10 DROP CONSTRAINTS pk_ex2_10; -- USER CONSTRAINTS 제약 조건 확인 SELECT constraint_name, constraint_type, table_name, search_condition FROM user_constraints WHERE table_name ='EX2_10';
SELECT a.employee_id , a.emp_name , a.department_id -- 부서명 컬럼 , b.department_name FROM employees a , departments b WHERE a.department_id = b.department_id;
CREATEOR REPLACE VIEW emp_dept_v1 AS SELECT a.employee_id , a.emp_name , a.department_id , b.department_name FROM employees a , departments b WHERE a.department_id = b.department_id;
새로운 view가 생성된다.
인덱스(index)
인덱스를 생성한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- 인덱스 생성 -- 75p -- 추후 공부해야 할 내용 : 인텍스 내부 구조에 따른 분류 ---- (초중급 레벨) B-Tree 인덱스, 비트맵 인덱스, 함수 기반 인덱스 ---- DB 성능 -- 인덱스 생성 -- col11 값에 중복 값을 허용하지 않는다. -- 인덱스 생성 시, user_indexes 시스템 뷰에서 내역 확인 CREATEUNIQUE INDEX ex2_10_ix011 ON ex2_10(col11);
SELECT index_name, index_type, table_name, uniqueness FROM user_indexes WHERE table_name ='EX2_10';
from tokenize import Token from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer
# 가상의 데이터 만들기 training = spark.createDataFrame([ (0, "a b c d e spark", 1.0), (1, "b d", 0.0), (2, "spark f g h", 1.0), (3, "hadoop mapreduce", 0.0) ], ["id", "text", "label"])
# Feature Engineering # 요리 작업
# 요리준비 1단계 : 텍스트를 단어로 분리 tokenizer = Tokenizer(inputCol='text', outputCol='words')
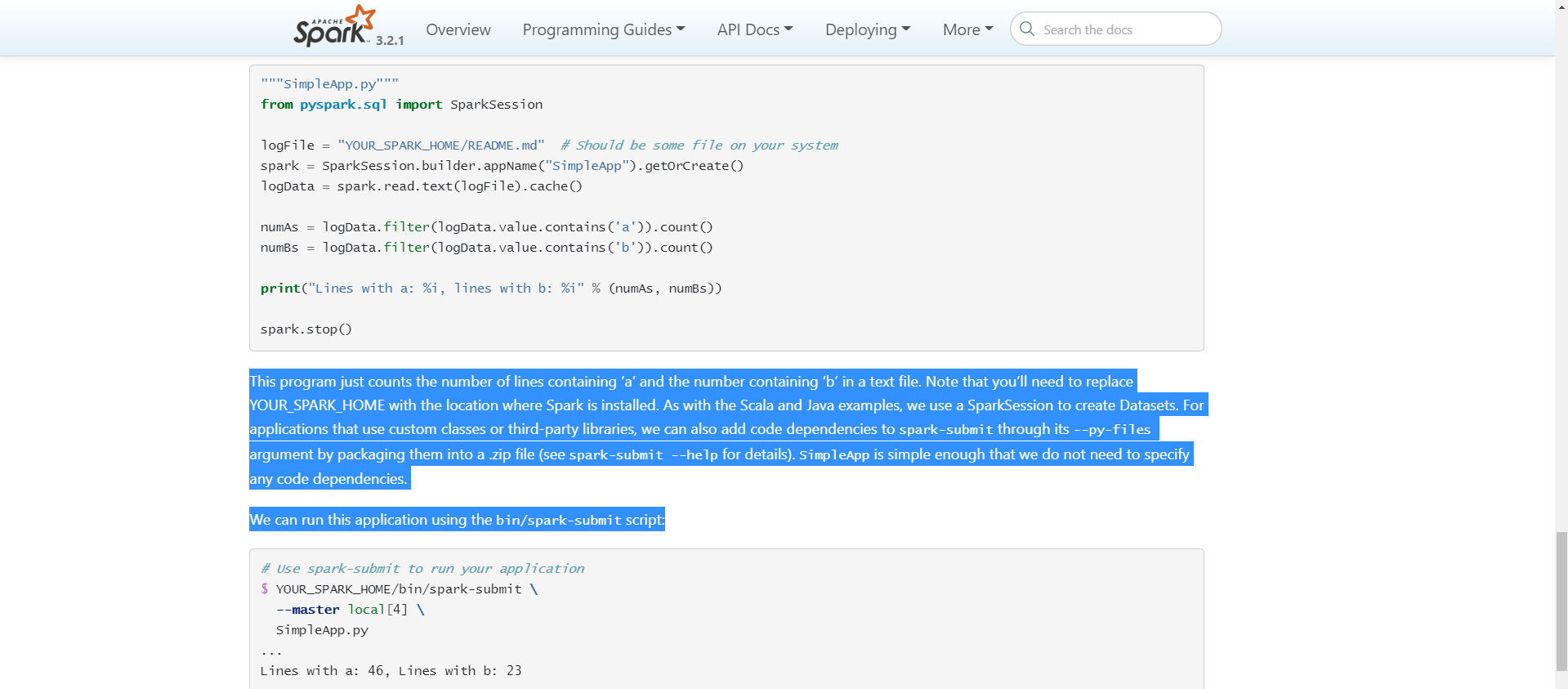
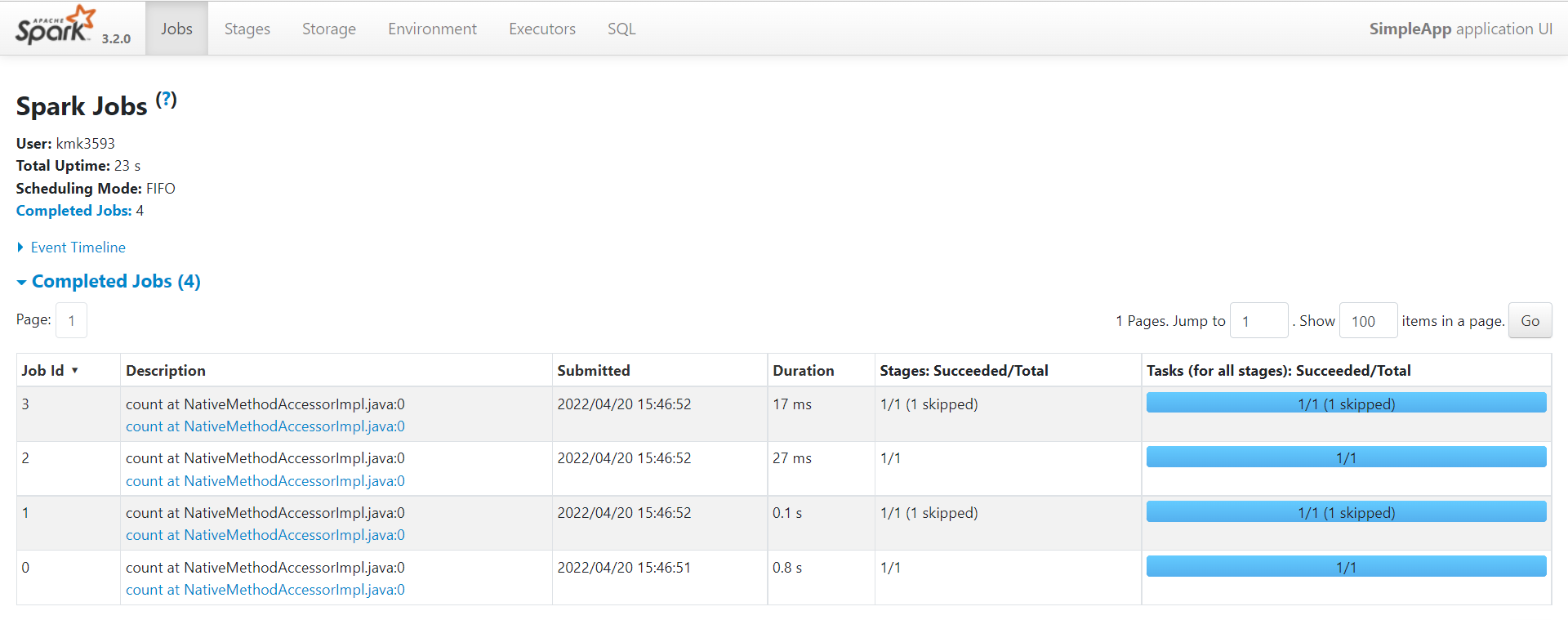
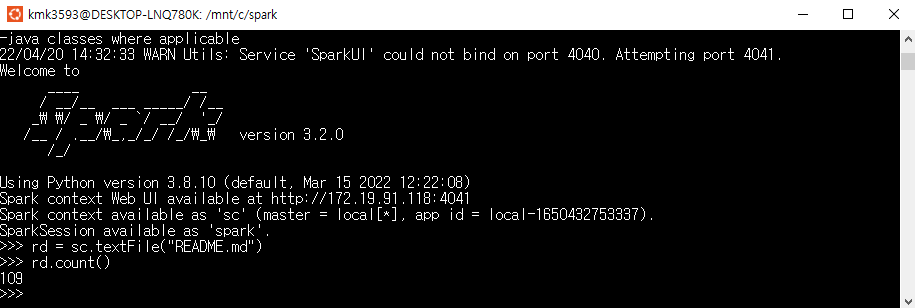
This program just counts the number of lines containing 'a' and the number containing 'b' in a text file. Note that you'll need to replace YOUR_SPARK_HOME with the location where Spark is installed. As with the Scala and Java examples, we use a SparkSession to create Datasets. For applications that use custom classes or third-party libraries, we can also add code dependencies to spark-submit through its --py-files argument by packaging them into a .zip file (see spark-submit --help for details). SimpleApp is simple enough that we do not need to specify any code dependencies.
We can run this application using the bin/spark-submit script:
→mkdir data
→cd data
→ls
→vi README.md
→ 위에서 복사한 내용을 붙여넣는다.
→ :wq
→ 내용 확인cat README.md
→ cd ..
→ vi SimpleApp.py
→ 코드 작성
1 2 3 4 5 6 7 8 9 10 11 12 13 14
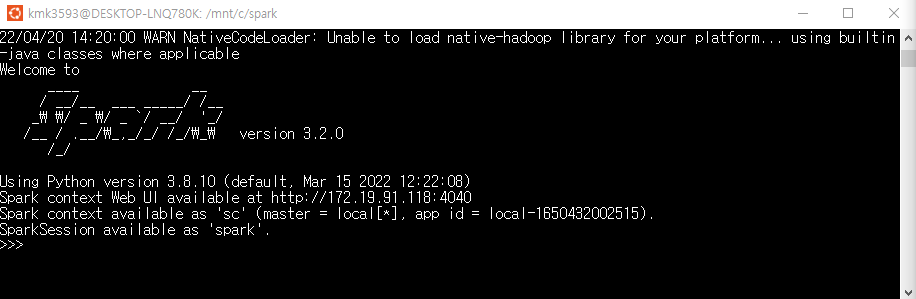
from pyspark.sql import SparkSession
logFile = "data/README.md" # Should be some file on your system spark = SparkSession.builder.appName("SimpleApp").getOrCreate() logData = spark.read.text(logFile).cache()