- 웹 크롤링을 시도해본다.
- 우선 Pycharm 환경에서 가상환경을 생성해야 한다.
바탕화면에 crawling 폴더 생성
→ 우클릭하여 pycharm으로 열기
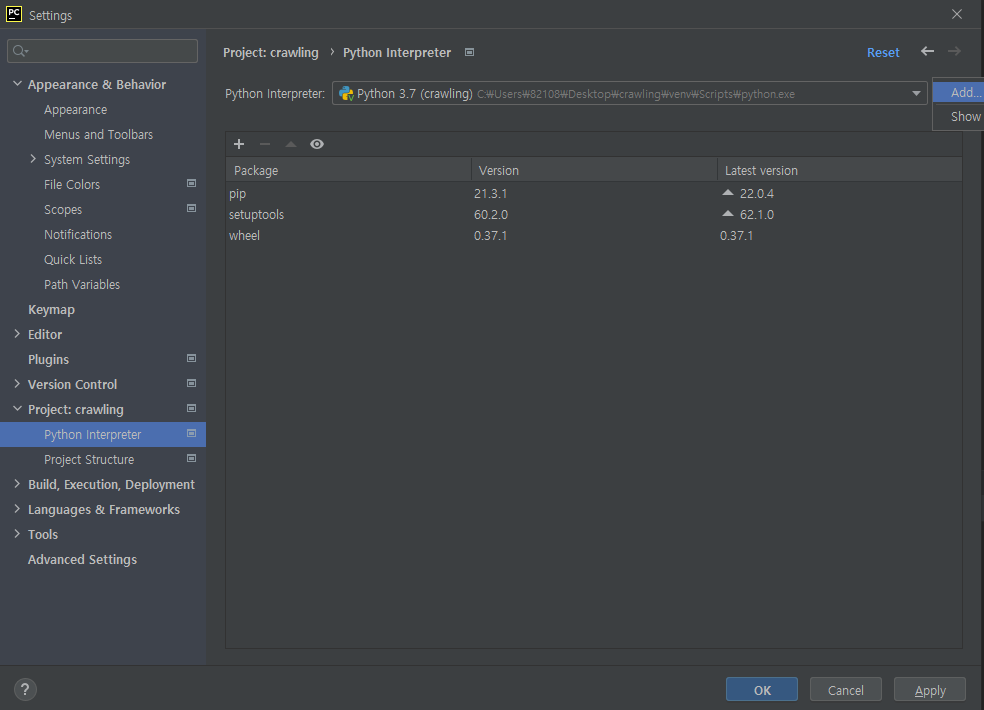
→ File → Settings
→ Project : crawling → python interpreter
→ 톱니모양 → add
→ git bash 터미널
→pip install beautifulsoup4
→pip install numpy pandas matplotlib seaborn
→pip install requests
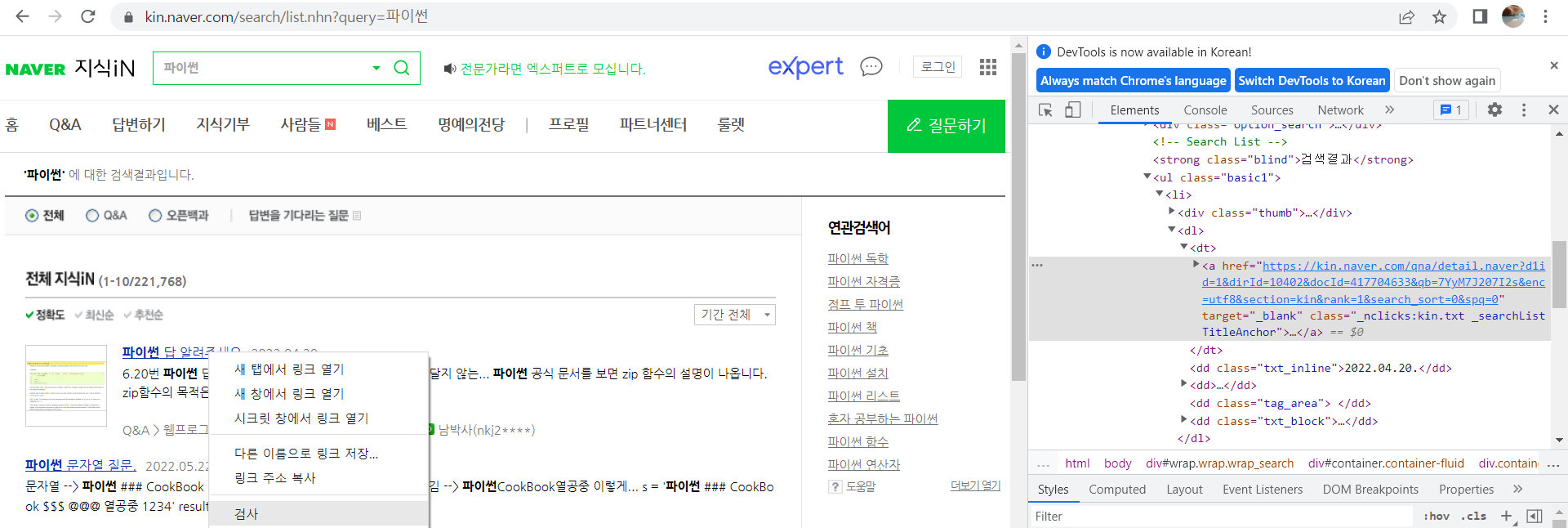
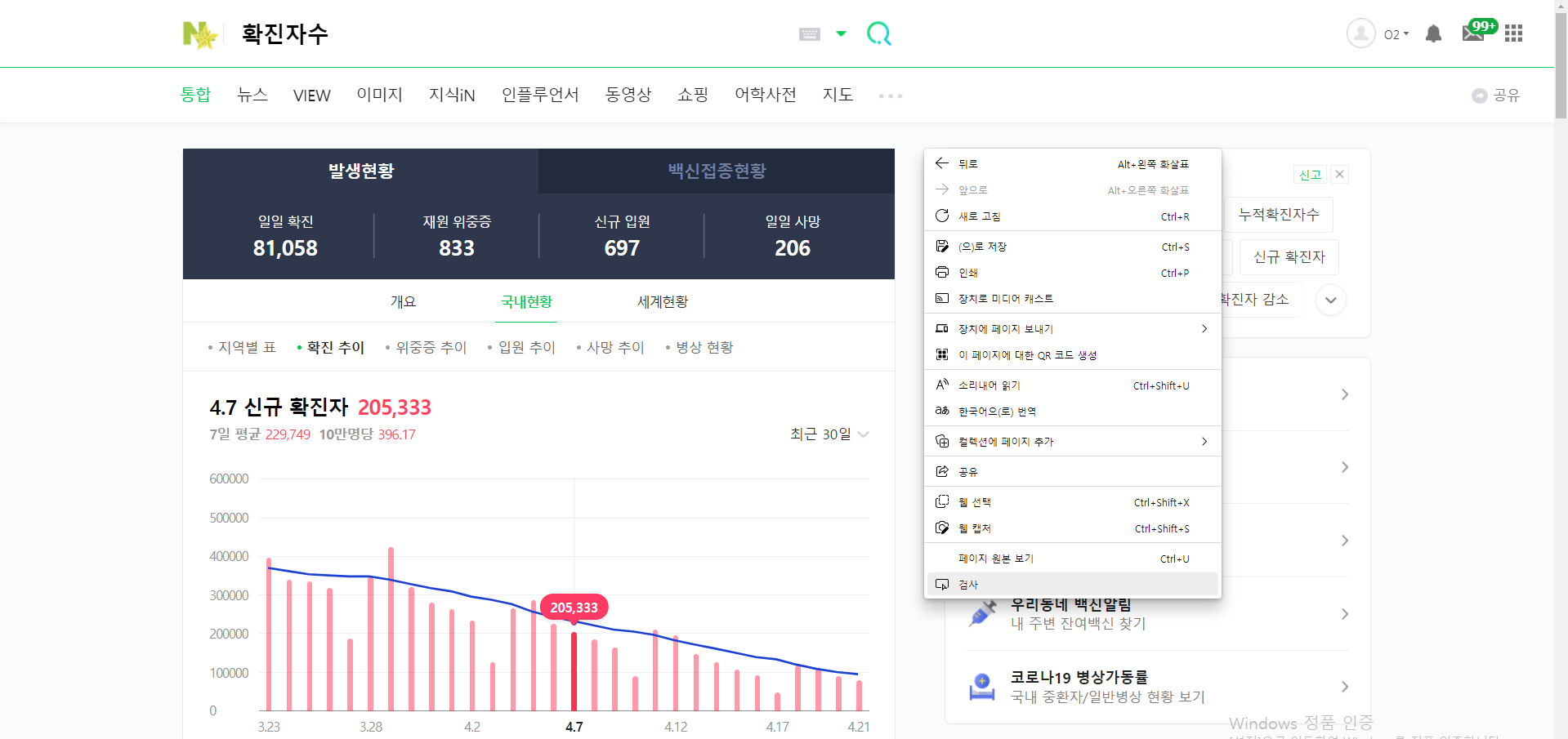
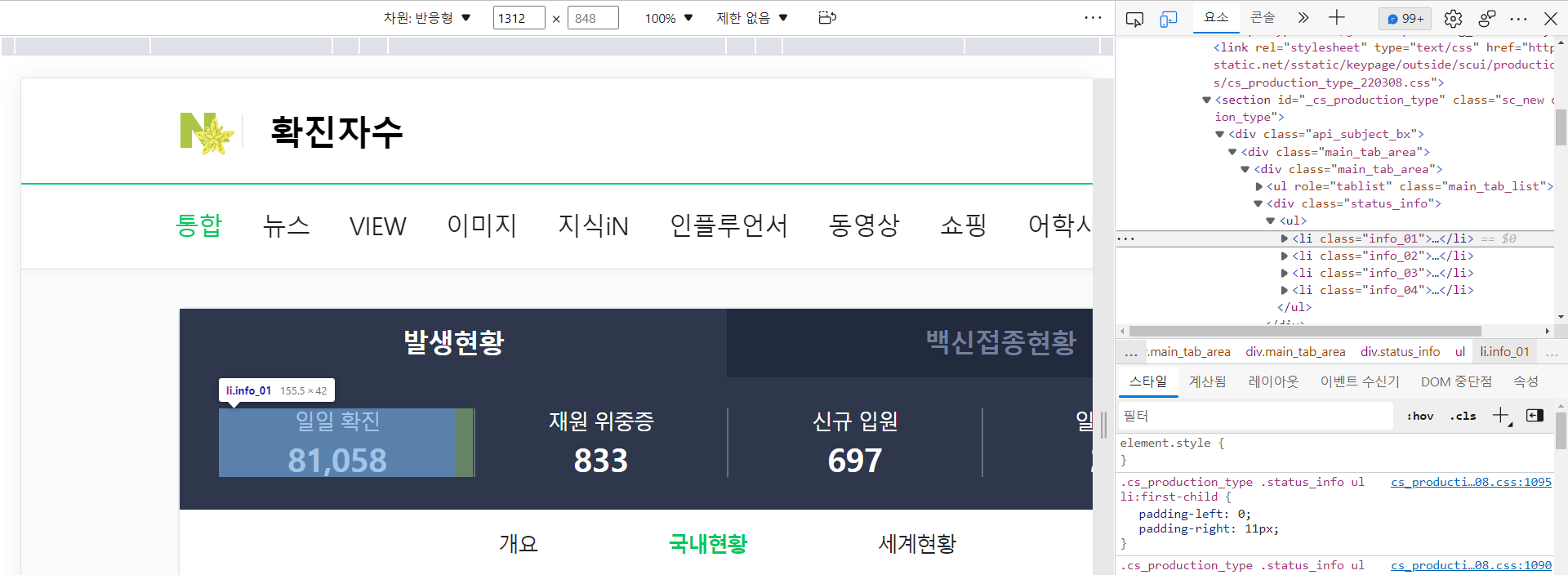
→ 검색 : 확진자수
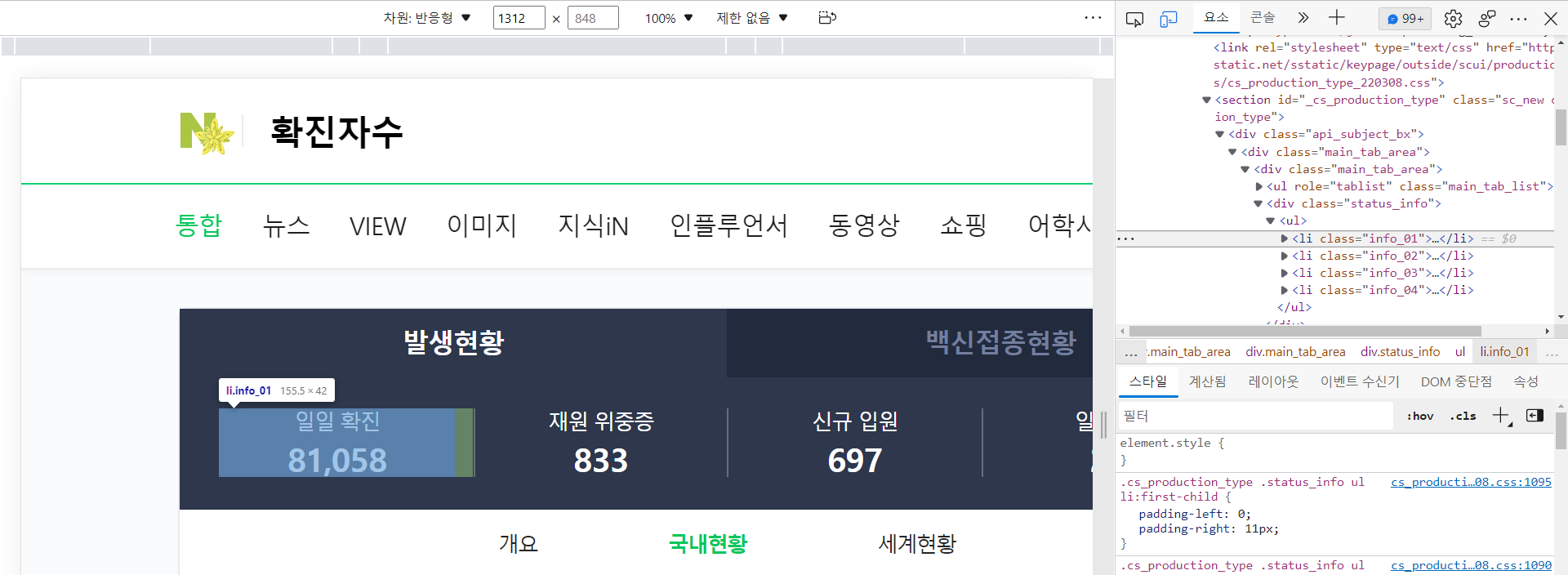
→ 우클릭 → 검사
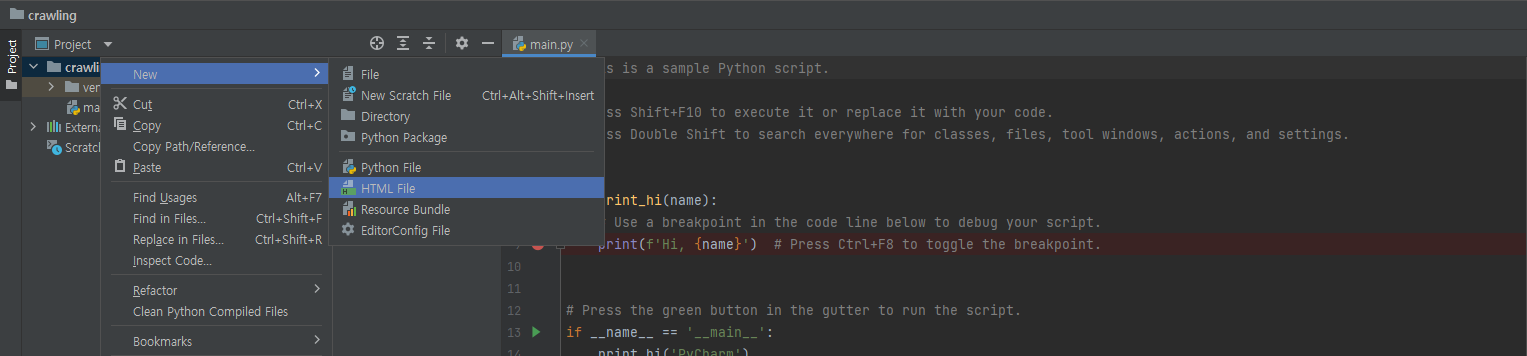
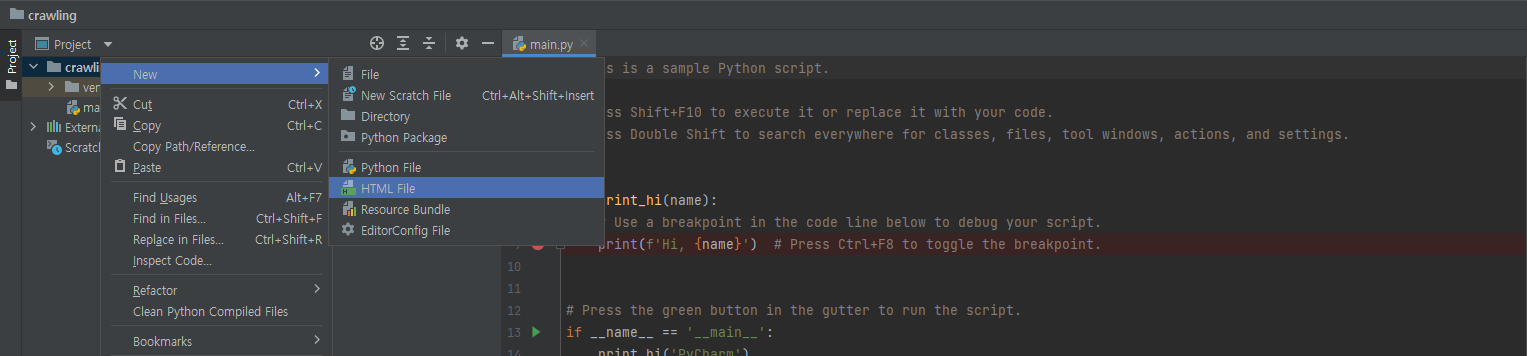
crawling 폴더 우클릭 → New → HTML.file
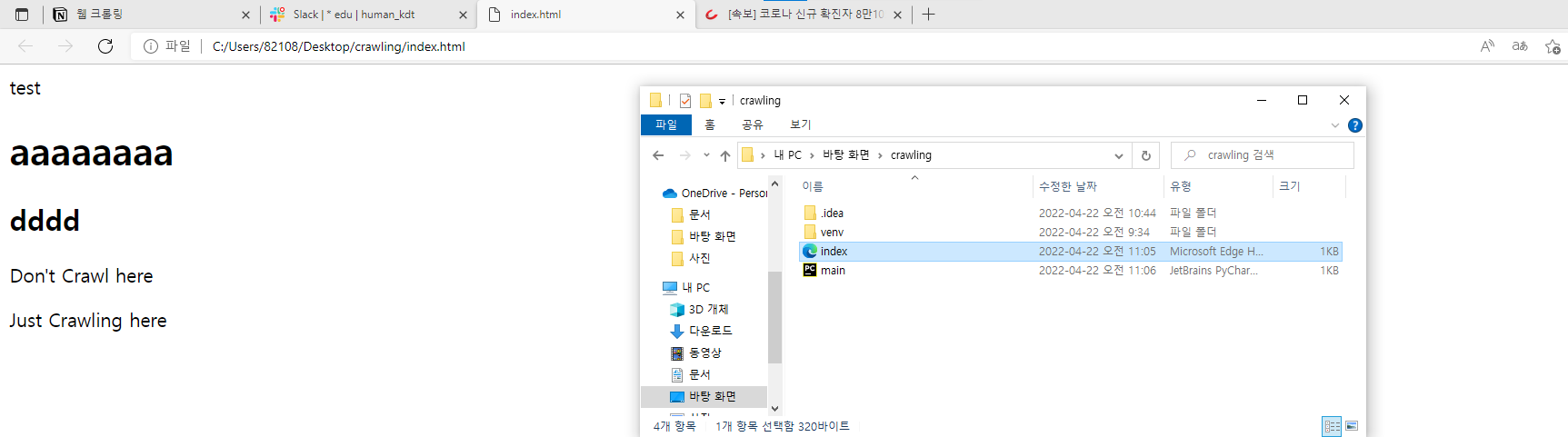
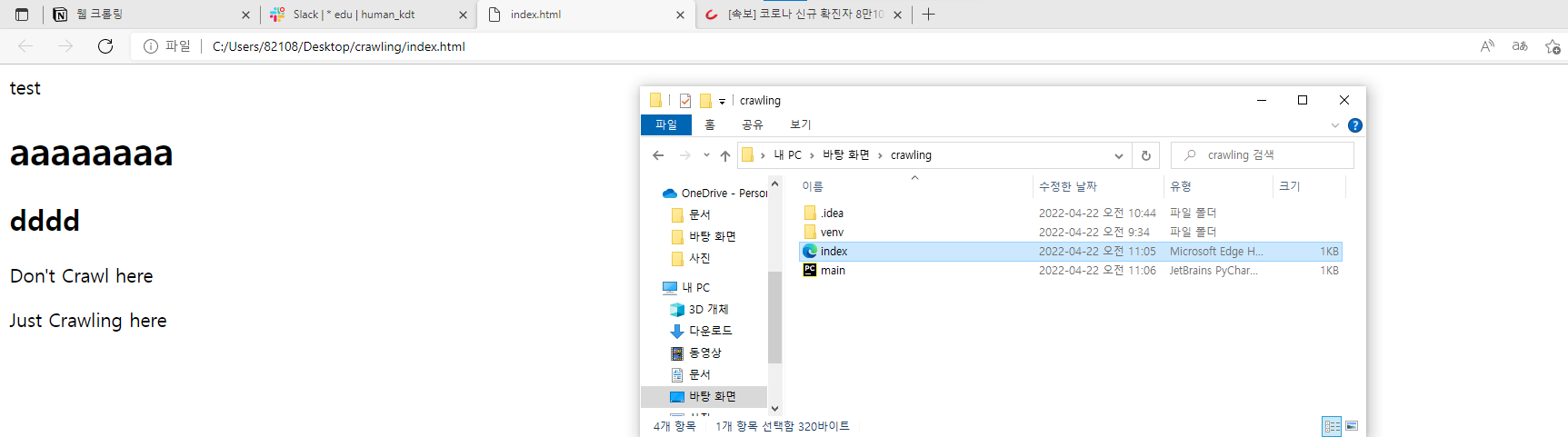
- 다음과 같이 입력하고 index 파일을 열어본다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<titl>test</titl>
</head>
<body>
<h1>aaaaaaaa</h1>
<h2>dddd</h2>
<div class="chapter01">
<p>Don't Crawl here </p>
</div>
<div class="chapter02">
<p>Just Crawling here</p>
</div>
</body>
</html>
|
- index 파일을 열면 index.html에 작성한 대로 출력된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
| from bs4 import BeautifulSoup
# 첫 번째 작업 index.html 파일을 BeautifulSoup 객체로 변환
## 클래스 변환 --> 클래스 내부의 메서드 사용
# html 파일을 변환
soup = BeautifulSoup(open("index.html", encoding='UTF-8'), "html.parser")
# print(type(soup))
# print(soup.find("div", class_="chapter02"))
# print(soup.find("p"))
results = soup.find_all("p")
print(results[1])
|
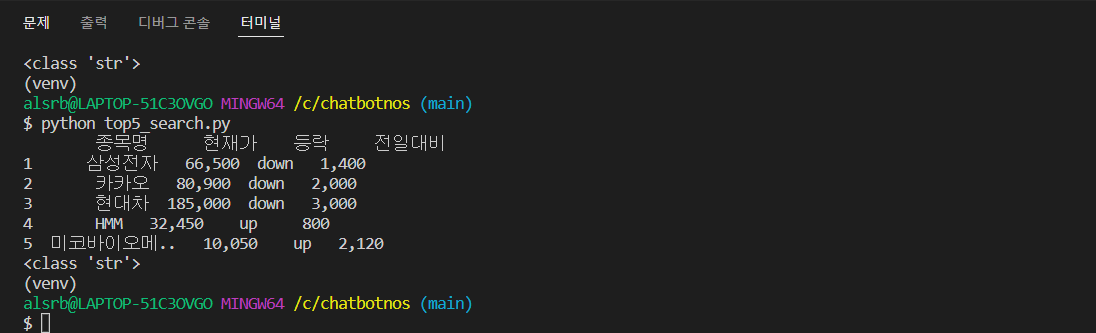
- Index.html에서 크롤링하여 다음과 같이 출력된다.
→ python main.py

팁
Python
웹상에 있는 데이터를 숩집하는 도구
- BeautifulSoup 가장 일반적인 수집 도구 (CSS 통해서 수집)
- Scrapy (CSS, XAPTH 통해서 데이터 수집 + JavaScript)
- Selenium (CSS, XPATH 통해서 데이터 수집 + JAVAScript)
—> 자바 필요 + 여러가지 설치 도구 필요
웹 사이트 만드는 3대 조건 + 1
- HTML, CSS, JavaScript, Ajax (비동기처리)
웹 사이트 구동 방식
Crawling 실습