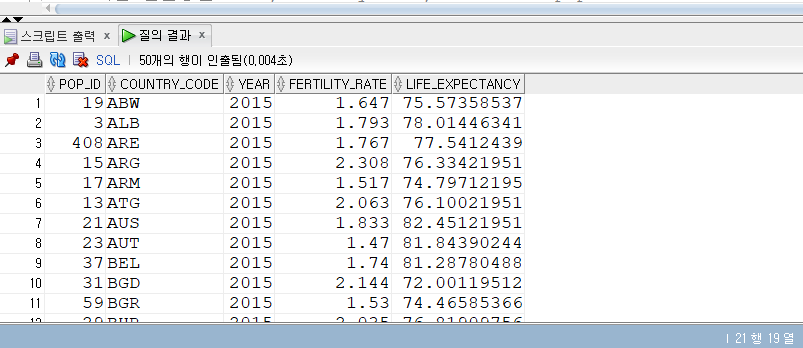
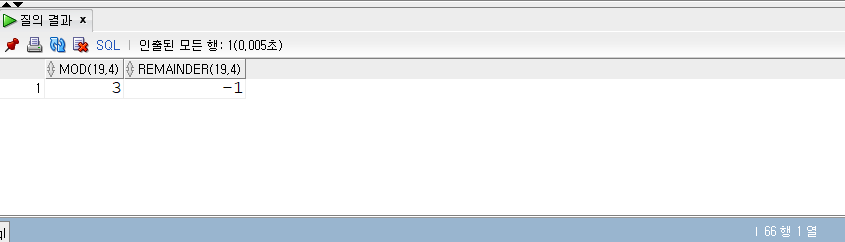
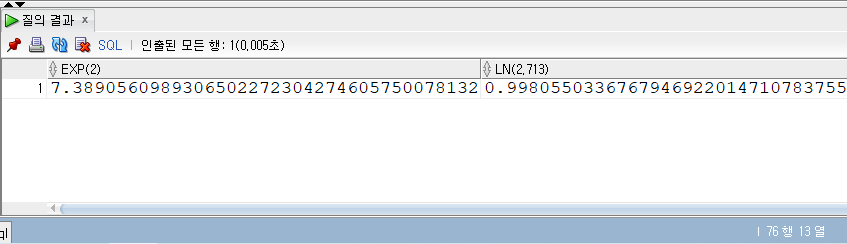
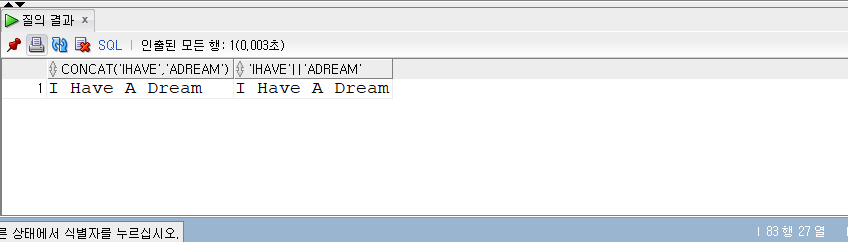
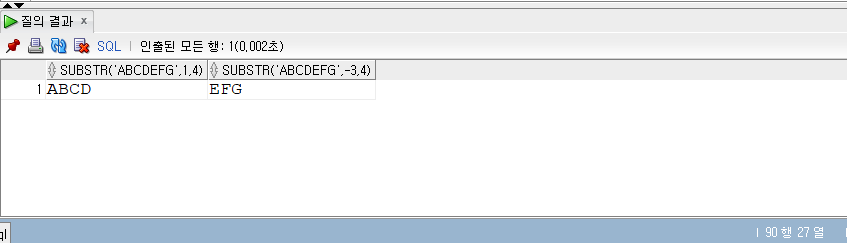
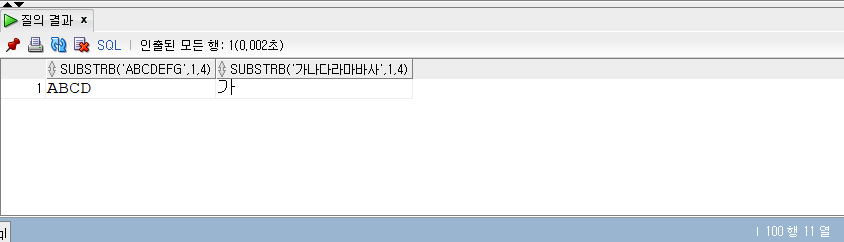
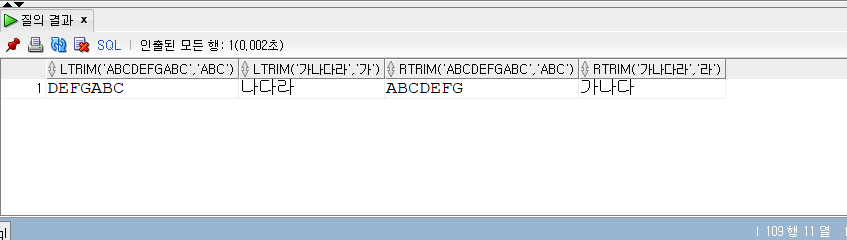
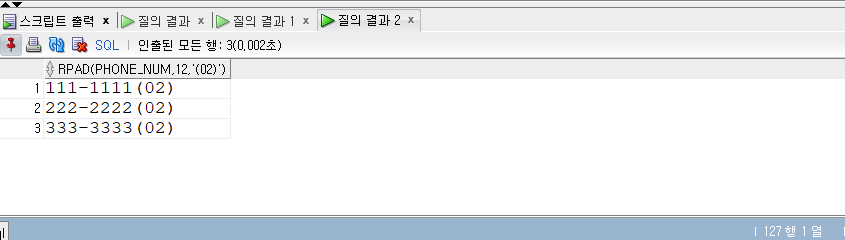
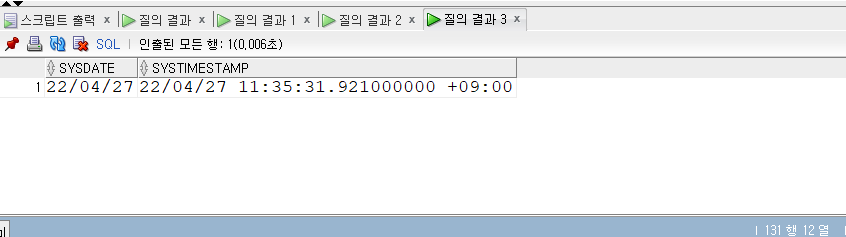
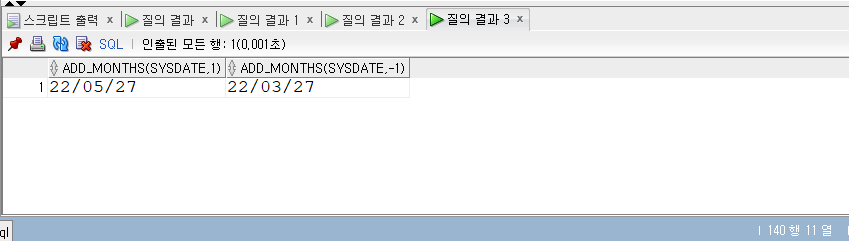
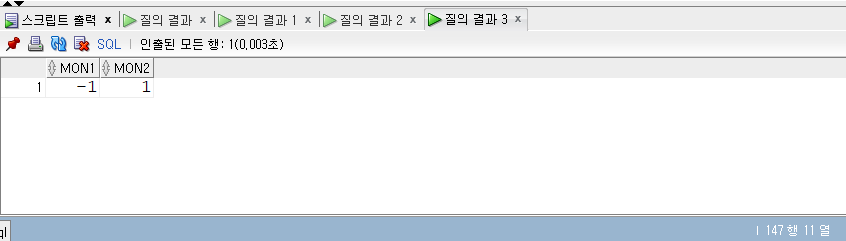
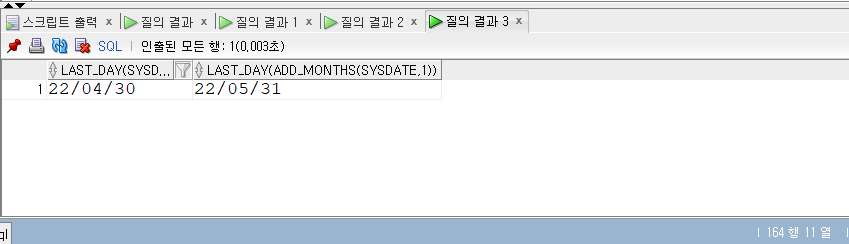
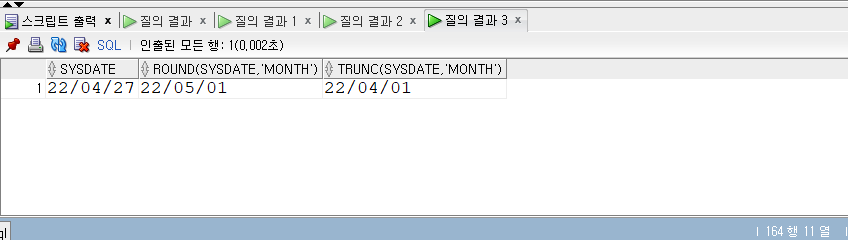
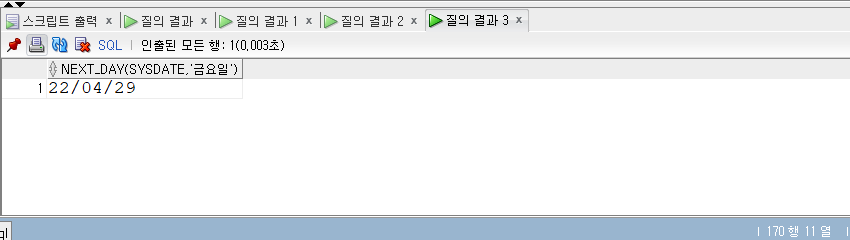
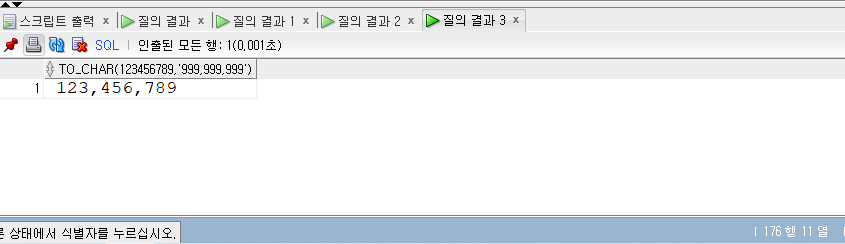
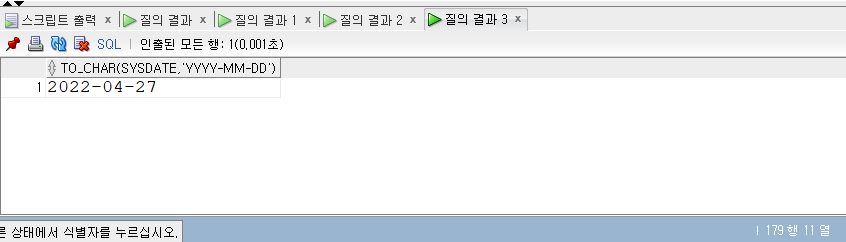
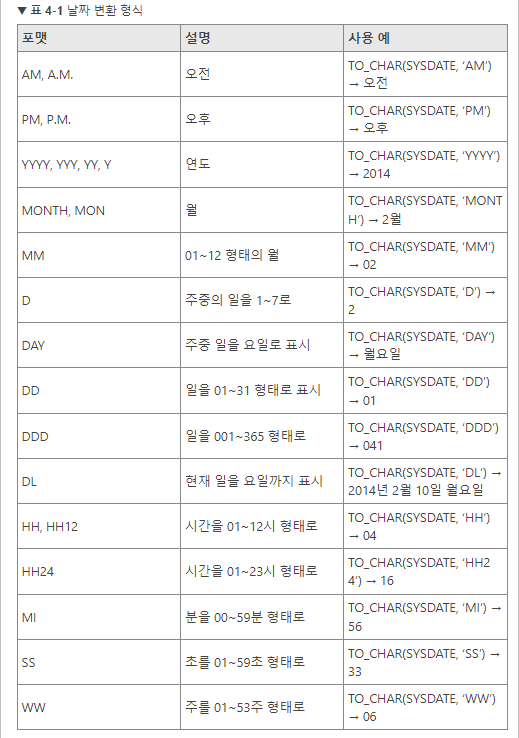
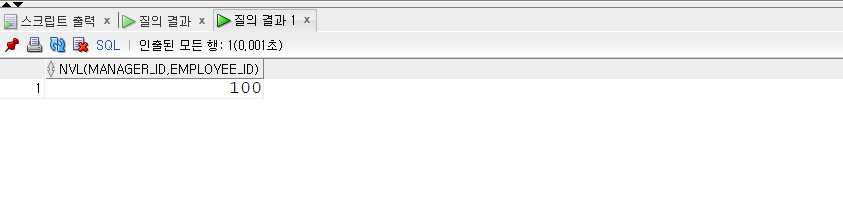
SELECT* FROM populations WHERE life_expectancy > (SELECTAVG(life_expectancy) FROM populations WHEREyear=2015 ) ANDyear=2015;
실행)
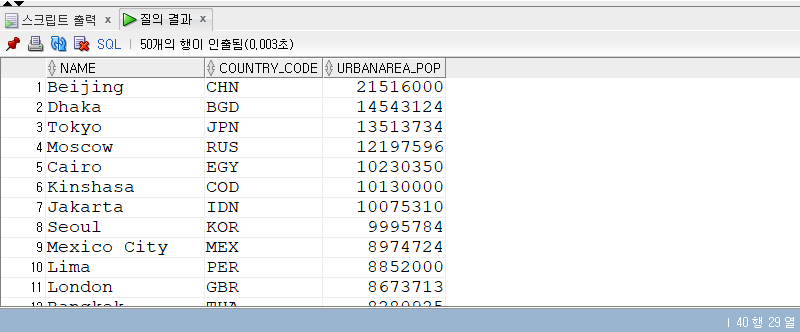
문제 2. subquery_countries 테이블에 있는 capital과 매칭되는 cities 테이블의 정보를 조회하라
조회할 컬럼명은 name, country_code, urbanarea_pop
답)
1 2 3 4 5 6 7 8 9 10
SELECT name , country_code , urbanarea_pop FROM cities WHERE name IN (SELECT capital FROM sub_countries) ORDERBY urbanarea_pop DESC;
실행)
문제 3.
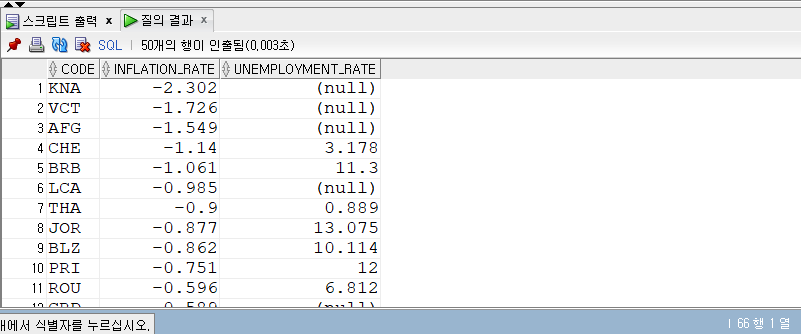
조건 1. economies 테이블에서 country code, inflation rate, unemployment rate를 조회한다.
조건 2. inflation rate 오름차순으로 정렬한다.
조건 3. subquery_countries 테이블내 gov_form 컬럼에서
Constitutional Monarchy 또는 Republic이 들어간 국가는 제외한다.
Select fields
데이터셋
답)
1 2 3 4 5 6 7 8 9 10 11 12
SELECT code , inflation_rate , unemployment_rate FROM economics WHEREyear=2015 AND code NOTIN (SELECT code FROM sub_countries WHERE (gov_form='Republic'OR gov_form LIKE'%Republic%') ) ORDERBY inflation_rate;
실행)
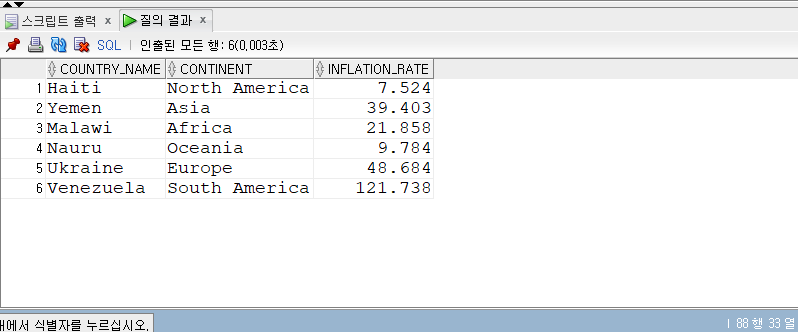
문제 4. 2010년 각 대륙별 inflation_rate가 가장 심한 국가와 inflation_rate를 구하세요.
힌트 1. 아래 쿼리 실행 SELECT country_name, continent, inflation_rate FROM sub_countries INNER JOIN economics USING (code) WHERE year = 2015;
2015년 기준으로, 각 대륙별 inflation_rate가 가장 높은 나라를 추출하는 코드를 작성한다.
inflation_rate가 높은 순
답)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
SELECT sc.country_name, sc.continent, ec.inflation_rate FROM sub_countries sc INNERJOIN economics ec ON sc.code = ec.code WHEREyear=2015 AND inflation_rate IN( SELECTMAX(inflation_rate) AS max_inf FROM( SELECT sc.country_name, sc.continent, ec.inflation_rate FROM sub_countries sc INNERJOIN economics ec -- USING(code) 대신 ON 쿼리를 작성 ON sc.code = ec.code WHEREyear=2015) GROUPBY continent );
실행)
SQL 윈도우 함수 연습문제
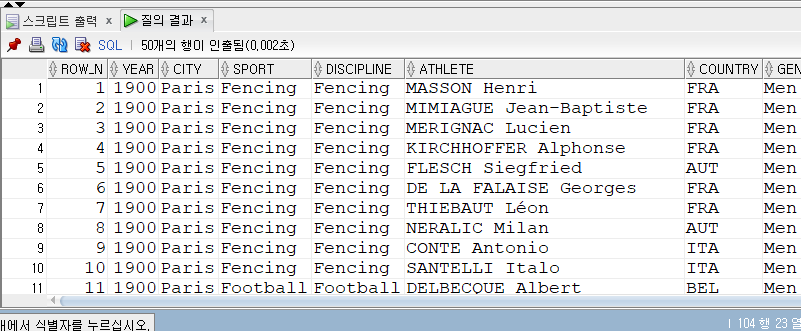
문제 1. 각 행에 숫자를 1, 2, 3, …, 형태로 추가한다. (row_n 으로 표시)
row_n 기준으로 오름차순으로 출력
테이블명에 alias를 적용한다.
실행)
1 2 3 4
SELECT ROWNUM as row_n , sm.* FROM summer_medals sm;
실행)
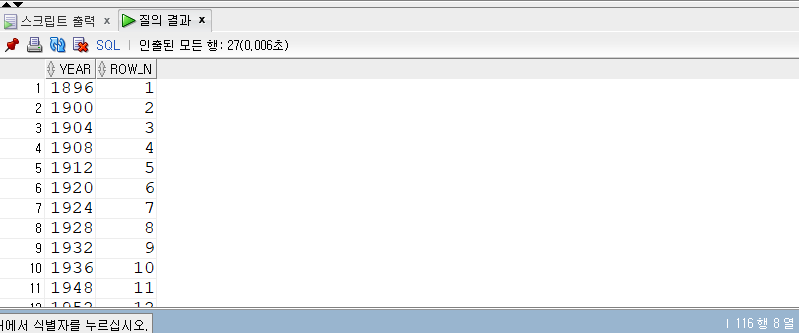
문제 2. 올림픽 년도를 오름차순 순번대로 작성을 한다.
힌트 : 서브쿼리와 윈도우 함수를 이용한다.
답)
1 2 3 4 5 6 7
SELECT year, ROW_NUMBER() OVER(ORDERBYYEAR) AS Row_N FROM( SELECTDISTINCTYear FROM summer_medals )Years;
실행)
문제 3.
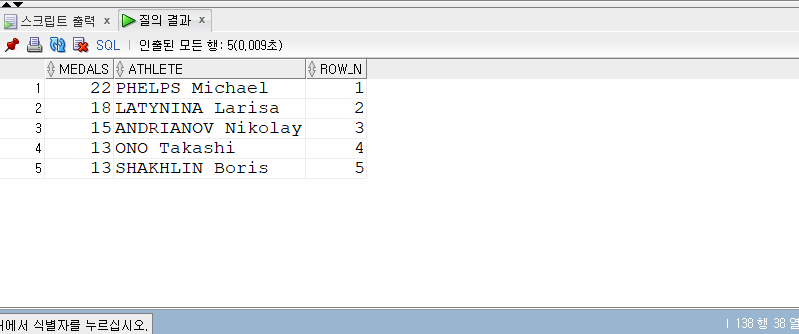
(1) WITH 절 사용하여 각 운동선수들이 획득한 메달 갯수를 내림차순으로 정렬하도록 합니다.
(2) (1) 쿼리를 활용하여 그리고 선수들의 랭킹을 추가한다.
상위 5개만 추출 : OFFSET 0 ROWS FETCH NEXT 5 ROWS ONLY
WITH AS (1번 쿼리)
2번 쿼리
답)
1 2 3 4 5 6 7 8 9 10 11 12 13
WITH medals AS( SELECT Athlete , COUNT(*) AS Medals FROM summer_medals GROUPBY Athlete) SELECT medals , Athlete , ROW_NUMBER() OVER (ORDERBY Medals DESC) AS ROW_N FROM medals ORDERBY Medals DESC OFFSET0ROWSFETCH NEXT 5ROWSONLY;
실행)
문제 4
다음쿼리를 실행한다.
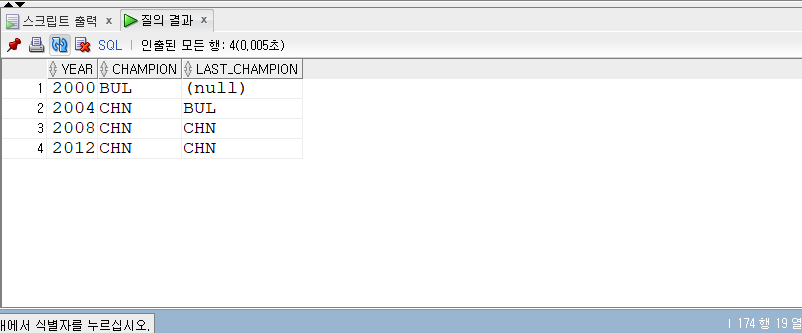
남자 69KG 역도 경기에서 매년 금메달리스트 조회하도록 합니다. SELECT Year, Country AS champion FROM summer_medals WHERE Discipline = 'Weightlifting' AND Event = '69KG' AND Gender = 'Men' AND Medal = 'Gold';
기존 쿼리에서 매년 전년도 챔피언도 같이 조회하도록 합니다.
LAG & WITH 절 사용
답)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
WITH Weightlifting_Gold AS ( SELECT -- Return each year's champions' countries Year , Country AS champion FROM summer_medals WHERE Discipline ='Weightlifting'AND Event ='69KG'AND GENDER ='Men'AND Medal ='Gold') SELECT Year , Champion , LAG(Champion) OVER (ORDERBYYearASC) AS Last_Champion FROM Weightlifting_Gold ORDERBYYearASC;
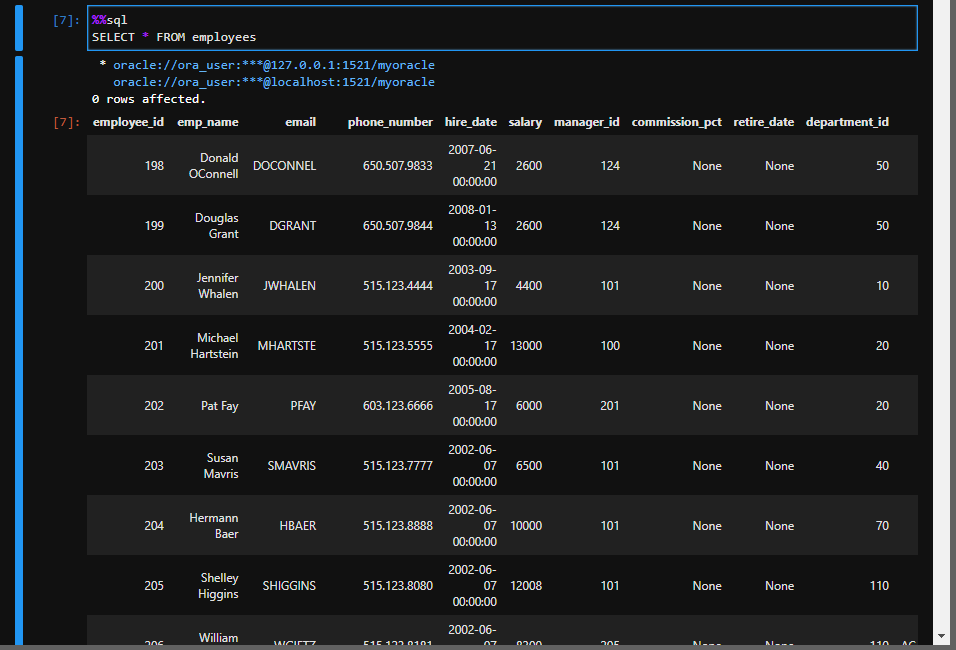
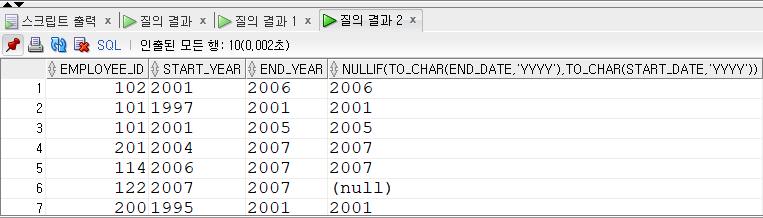
SELECT a.employee_id , a.emp_name , d.job_title , b.start_date , b.end_date , c.department_name FROM employees a , job_history b , departments c , jobs d WHERE a.employee_id = b.employee_id AND b.department_id = c.department_id AND b.job_id = d.job_id AND a.employee_id =101
select a.employee_id, a.emp_name, b.job_id, b.department_id
from employees a,
job_history b
where a.employee_id = b.employee_id(+)
and a.department_id(+) = b.department_id;답 : 외부 조인의 경우, 조인조건에서 데이터가 없는 테이블의 컬럼에만 (+)를 붙여야 한다.
따라서 위 쿼리의 경우, and a.department_id(+) 가 아닌 a.department_id = b.department_id(+)로 고쳐야 한다.3. 외부 조인을 할 때 (+)연산자를 같이 사용할 수 없는데, IN 절에 사용하는 값이 한 개이면 사용할 수 있다.
그 이유는 무엇인지 설명해 보자.답 : 오라클은 IN 절에 포함된 값을 기준으로 OR로 변환한다. 예를 들어, department_id IN (10,20,30)은 department_id = 10 OR department_id = 20 OR department_id = 30 으로 바꿔 쓸 수 있다.
그런데 IN절에 값이 1개인 경우, 즉 department_id IN (10)일 경우 department_id=10으로 변환할 수 있으며, 외부조인을 하더라도 값이 1개인 경우는 사용할 수 있다.4. 다음의 쿼리를 ANSI 문법으로 변경해 보자.
입력
SELECT a.department_id, a.department_name
FROM departments a, employees b
WHERE a.department_id = b.department_id
AND b.salary > 3000
ORDER BY a.department_name;
1 2 3 4 5 6 7 8 9 10
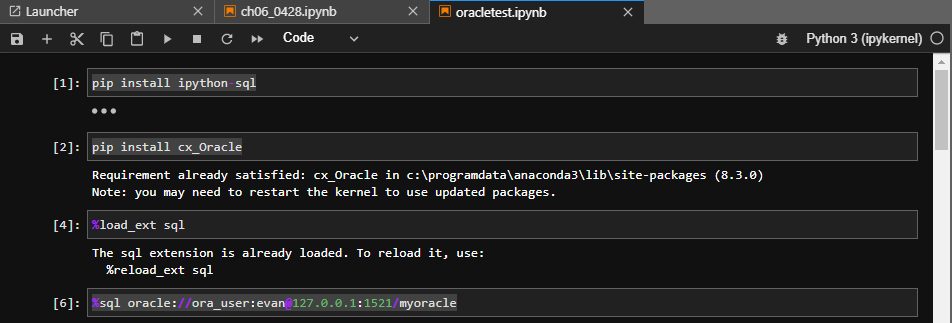
%%sql
SELECT a.department_id , a.department_name FROM departments a INNERJOIN employees b ON (a.department_id = b.department_id) WHERE b.salary >3000 ORDERBY a.department_name
SELECT emp.years , emp.employee_id , emp2.emp_name , emp.amount_sold FROM ( SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.CUST_ID AND b.country_id = c.COUNTRY_ID AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id ) emp, ( SELECT years , MAX(amount_sold) AS max_sold , MIN(amount_sold) AS min_sold FROM ( SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.CUST_ID AND b.country_id = c.COUNTRY_ID AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id ) K GROUPBY years ) sale, employees emp2 WHERE emp.years = sale.years AND (emp.amount_sold = sale.max_sold OR emp.amount_sold = sale.min_sold) AND emp.employee_id = emp2.employee_id ORDERBY years
7장1. 계층형 쿼리 응용편에서 LISTAGG 함수를 사용해 다음과 같이 로우를 컬럼으로 분리했다.
입력
SELECT department_id, LISTAGG(emp_name, ',') WITHIN GROUP (ORDER BY emp_name) as empnames
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id;
LISTAGG 함수 대신 계층형 쿼리, 분석 함수를 사용해서 위 쿼리와 동일한 결과를 산출하는 쿼리를 작성해 보자.2. 다음 쿼리는 사원 테이블에서 JOB_ID가 ‘SH_CLERK’인 사원을 조회하는 쿼리다.
입력
SELECT employee_id, emp_name, hire_date
FROM employees
WHERE job_id = 'SH_CLERK'
ORDER By hire_date;
결과
EMPLOYEE_ID EMP_NAME HIRE_DATE
----------- -------------------- -------------------
184 Nandita Sarchand 2004/01/27 00:00:00
192 Sarah Bell 2004/02/04 00:00:00
185 Alexis Bull 2005/02/20 00:00:00
193 Britney Everett 2005/03/03 00:00:00
188 Kelly Chung 2005/06/14 00:00:00
....
....
199 Douglas Grant 2008/01/13 00:00:00
183 Girard Geoni 2008/02/03 00:00:00
사원 테이블에서 퇴사일자(retire_date)는 모두 비어 있는데, 위 결과에서 사원번호가 184번인 사원의 퇴사일자는 다음으로 입사일자가 빠른 192번 사원의 입사일자라고 가정해서 다음과 같은 형태로 결과를 추출하도록 쿼리를 작성해 보자(입사일자가 가장 최근인 183번 사원의 퇴사일자는 NULL이다).
결과
EMPLOYEE_ID EMP_NAME HIRE_DATE RETIRE_DATE
----------- -------------------- ------------------- ---------------------------
184 Nandita Sarchand 2004/01/27 00:00:00 2004/02/04 00:00:00
192 Sarah Bell 2004/02/04 00:00:00 2005/02/20 00:00:00
185 Alexis Bull 2005/02/20 00:00:00 2005/03/03 00:00:00
193 Britney Everett 2005/03/03 00:00:00 2005/06/14 00:00:00
188 Kelly Chung 2005/06/14 00:00:00 2005/08/13 00:00:00
....
....
199 Douglas Grant 2008/01/13 00:00:00 2008/02/03 00:00:00
183 Girard Geoni 2008/02/03 00:00:003. sales 테이블에는 판매 데이터, customers 테이블에는 고객정보가 있다. 2001년 12월(SALES_MONTH = ‘200112’) 판매 데이터 중 현재일자를 기준으로 고객의 나이(customers.cust_year_of_birth)를 계산해서 다음과 같이 연령대별 매출금액을 보여주는 쿼리를 작성해 보자.
결과
-------------------------
연령대 매출금액
-------------------------
10대 xxxxxx
20대 ....
30대 ....
40대 ....
-------------------------4. 3번 문제를 이용해 월별로 판매금액이 가장 하위에 속하는 대륙 목록을 뽑아보자.
(대륙 목록은 countries 테이블의 country_region에 있으며, country_id 컬럼으로 customers 테이블과 조인을 해서 구한다).
결과
---------------------------------
매출월 지역(대륙) 매출금액
---------------------------------
199801 Oceania xxxxxx
199803 Oceania xxxxxx
...
---------------------------------5. 5장 연습문제 5번의 정답 결과를 이용해 다음과 같이 지역별, 대출종류별, 월별 대출잔액과 지역별 파티션을 만들어 대출 종류별 대출잔액의 퍼센트(%)를 구하는 쿼리를 작성해보자.
결과
------------------------------------------------------------------------------------------------
지역 대출종류 201111 201112 201210 201211 201212 203110 201311
------------------------------------------------------------------------------------------------
서울 기타대출 73996.9( 36% )
서울 주택담보대출 130105.9( 64% )
부산
...
...
--------------------------------------------------------------------------------------
SELECT b2.* FROM ( SELECTperiod, region, sum(loan_jan_amt) jan_amt FROM kor_loan_status GROUPBYperiod, region ) b2, ( SELECT b.period, MAX(b.jan_amt) max_jan_amt FROM ( SELECTperiod, region, sum(loan_jan_amt) jan_amt FROM kor_loan_status GROUPBYperiod, region ) b, ( SELECTMAX(PERIOD) max_month FROM kor_loan_status GROUPBY SUBSTR(PERIOD, 1, 4) ) a WHERE b.period = a.max_month GROUPBY b.period ) c WHERE b2.period = c.period AND b2.jan_amt = c.max_jan_amt ORDERBY1
WITH b2 AS (SELECTperiod, region, sum(loan_jan_amt) jan_amt FROM kor_loan_status GROUPBYperiod, region) , c AS (SELECT b.period, MAX(b.jan_amt) max_jan_amt FROM (SELECTperiod, region, sum(loan_jan_amt) jan_amt FROM kor_loan_status GROUPBYperiod, region) b , (SELECTMAX(PERIOD) max_month FROM kor_loan_status GROUPBY SUBSTR(PERIOD, 1, 4) ) a WHERE b.period = a.max_month GROUPBY b.period ) -- AS SELECT SELECT b2.* FROM b2, c WHERE b2.period = c.period AND b2.jan_amt = c.max_jan_amt ORDERBY1
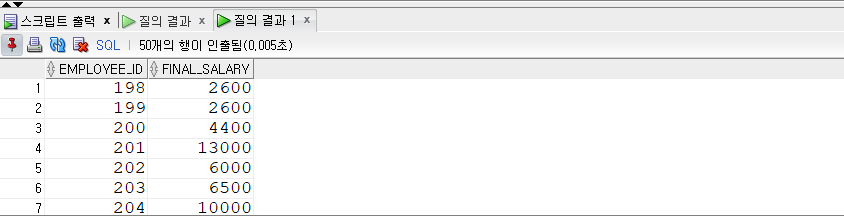
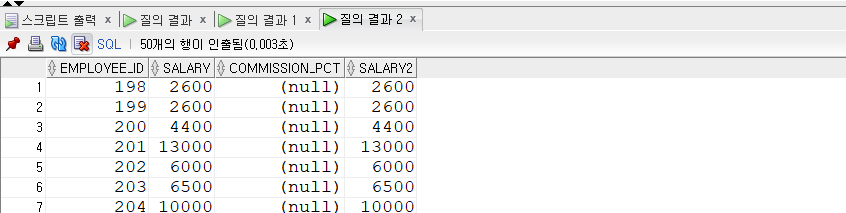
SELECT emp_name , hire_date , salary , LAG(salary, 1, 0) OVER (ORDERBY hire_date) AS prev_sal , LEAD(salary, 1, 0) OVER (ORDERBY hire_date) AS next_sal FROM employees WHERE department_id =30
SELECT a.employee_id , a.emp_name , b.department_id , b.department_name FROM employees a , departments b (서브쿼리) d – 기획부 평균급여 WHERE a.deartment_id = b.department_id AND a.salary > d.avg_salary
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
%%sql
SELECT a.employee_id , a.emp_name , b.department_id , b.department_name FROM employees a , departments b , (SELECTAVG(c.salary) AS avg_salary FROM departments b , employees c WHERE b.parent_id =90 AND b.department_id = c.department_id) d WHERE a.department_id = b.department_id AND a.salary > d.avg_salary
SELECT a.* FROM (SELECT a.sales_month, ROUND(AVG(a.amount_sold)) month_avg FROM sales a , customers b , countries c WHERE a.sales_month BETWEEN'200001'AND'200012' AND a.cust_id = b.CUST_ID AND b.COUNTRY_ID = c.COUNTRY_ID AND c.COUNTRY_NAME ='Italy' GROUPBY a.sales_month ) a , (SELECT ROUND(AVG(a.amount_sold)) AS year_avg FROM sales a , customers b , countries c WHERE a.sales_month BETWEEN'200001'AND'200012' AND a.cust_id = b.CUST_ID AND b.COUNTRY_ID = c.COUNTRY_ID AND c.COUNTRY_NAME ='Italy') b WHERE a.month_avg>b.year_avg
SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.cust_id AND b.country_id = c.country_id AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id
SELECT years , MAX(amount_sold) AS max_sold , MIN(amount_sold) AS min_sold FROM (SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.cust_id AND b.country_id = c.country_id AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id) K GROUPBY years ORDERBY years
최대매출, 최소매출액을 일으킨 사원을 찾는다.SELECT emp.years , emp.employee_id , emp.amount_sold FROM () emp – (1) 결과를 대입 , () sale – (2) 결과를 대입 WHERE emp.years = sales.years AND emp.amount_sold = sale.max_sold ORDER BY years;
SELECT emp.years , emp.employee_id , emp2.emp_name , emp.amount_sold FROM (SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.cust_id AND b.country_id = c.country_id AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id) emp , (SELECT years , MAX(amount_sold) AS max_sold , MIN(amount_sold) AS min_sold FROM (SELECT SUBSTR(a.sales_month, 1, 4) as years , a.employee_id , SUM(a.amount_sold) AS amount_sold FROM sales a , customers b , countries c WHERE a.cust_id = b.cust_id AND b.country_id = c.country_id AND c.country_name ='Italy' GROUPBY SUBSTR(a.sales_month, 1, 4), a.employee_id) K GROUPBY years) sale , employees emp2 WHERE emp.years = sale.years AND emp.amount_sold = sale.max_sold AND emp.employee_id = emp2.employee_id ORDERBY years
SELECT period , region , SUM(loan_jan_amt) totl_tan FROM kor_loan_status WHEREperiod='201311' GROUPBYperiod, region HAVINGSUM(loan_jan_amt) >100000 ORDERBY region
SELECT department_id , department_name FROM departments a WHEREEXISTS (SELECT* FROM employees b WHERE a.department_id = b.department_id AND b.salary >3000 ) -- EXISTS ORDERBY a.department_name
SELECT department_id , department_name FROM departments a WHERE a.department_id IN (SELECT b.department_id FROM employees b WHERE b.salary >3000 ) -- IN ORDERBY a.department_name
서브 쿼리의 B 테이블에는 없는 메인 쿼리의 A 테이블의 데이터만 추출하는 조인 방법이다.
NOT IN이나 NOT EXISTS 연산자를 사용
1 2 3 4 5 6 7 8 9 10 11 12 13 14
%%sql
SELECT a.employee_id , a.emp_name , a.department_id , b.department_name FROM employees a , departments b WHERE a.department_id = b.department_id AND a.department_id NOTIN (SELECT department_id FROM departments WHERE manager_id ISNULL)
SELECT a.employee_id , a.emp_name , b.employee_id , b.emp_name , a.department_id FROM employees a , employees b WHERE a.employee_id < b.employee_id AND a.department_id = b.department_id AND a.department_id =20
SELECT a.employee_id , a.emp_name , b.job_id , b.department_id FROM employees a , job_history b WHERE a.employee_id = b.employee_id(+) AND a.department_id = b.department_id(+)
쿼리 비교 : 2013년 1월 1일 이후에 입사한 사원번호, 사원명 부서번호, 부서명을 조회
기존 쿼리
1 2 3 4 5 6 7 8 9 10 11 12 13
%%sql
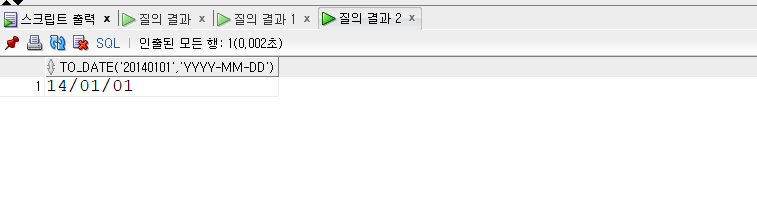
SELECT a.employee_id , a.emp_name , a.hire_date , b.department_id , b.department_name FROM employees a , departments b WHERE a.department_id = b.department_id AND a.hire_date >= TO_DATE('2003-01-01', 'YYYY-MM-DD')
쿼리 비교 : 2013년 1월 1일 이후에 입사한 사원번호, 사원명 부서번호, 부서명을 조회
ANSI 쿼리
1 2 3 4 5 6 7 8 9 10 11 12 13
%%sql
SELECT a.employee_id , a.emp_name , a.hire_date , b.department_id , b.department_name FROM employees a INNERJOIN departments b ON (a.department_id = b.department_id) WHERE a.hire_date >= TO_DATE('2003-01-01', 'YYYY-MM-DD')
기존 문법에서는 기준 테이블과 대상 테이블(데이터가 없는 테이블)에서 대상 테이블쪽 조인 조건에 (+)를 붙였지만, ANSI 외부 조인은 FROM 절에 명시된 테이블 순서에 입각해 먼저 명시된 테이블 기준으로 LEFT 혹은 RIGHT를 붙이는 점이 다르다.- 쿼리 비교 : ANSI 외부 조인
기본 쿼리
1 2 3 4 5 6 7 8 9 10 11
%%sql
SELECT a.employee_id , a.emp_name , b.job_id , b.department_id FROM employees a , job_history b WHERE a.employee_id = b.employee_id(+) AND a.department_id = b.department_id(+)
SELECT a.employee_id , a.emp_name , b.job_id , b.department_id FROM employees a LEFTOUTERJOIN job_history b ON (a.employee_id = b.employee_id and a.department_id = b.department_id)
SELECT (SELECT (서브쿼리) FROM WHERE GROUP BY HAVING ORDER BY ) FROM (SELECT FROM WHERE GROUP BY HAVIGN ORDER BY)) WHERE (SELECT FROM WHERE GROUP BY HAVING ORDER BY)) GROUP BY HAVING- 연관성 없는 서브 쿼리- 메인쿼리 : 모든 사원 테이블을 조회
서브쿼리 : 조건 - 사원테이블의 평균 급여보다 많은 사원
결괏값은 51개
1 2 3 4 5
%%sql
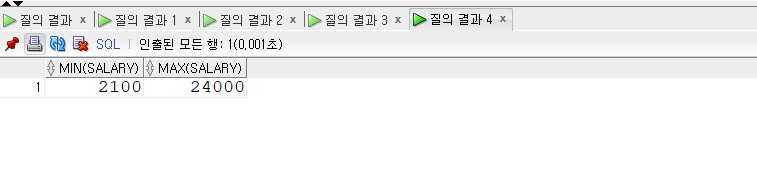
SELECT* FROM employees WHERE salary >= (SELECTAVG(salary) FROM employees)
SELECT a.employee_id , (SELECT b.emp_name FROM employees b WHERE a.employee_id = b.employee_id) AS emp_name , department_id , (SELECT b.department_name FROM departments b WHERE a.department_id = b.department_id) AS dep_name , (SELECT c.job_title FROM jobs c WHERE a.job_id = c.job_id) AS title_name FROM job_history a
SELECT a.department_id , a.department_name FROM departments a WHEREEXISTS( SELECT1 FROM employees b WHERE a.department_id = b.department_id AND b.salary > (SELECTAVG(salary) FROM employees) )
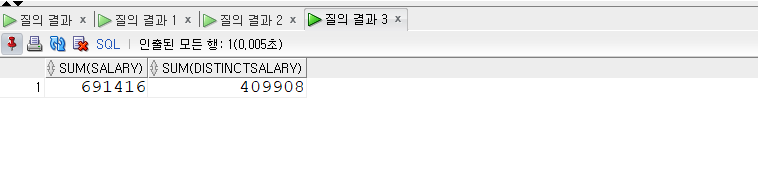
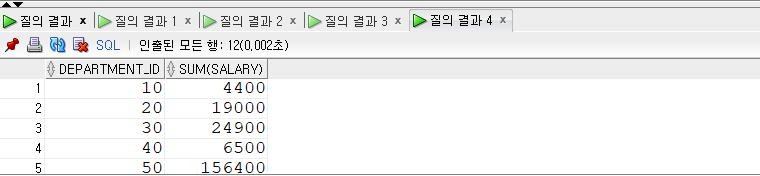
SELECT department_id , SUM(salary) FROM employees GROUPBY department_id ORDERBY department_id;
HAVING
GROUP BY절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할을 수행.
HAVING 필터 조건 형태로 사용한다.
1 2 3 4 5 6 7 8 9
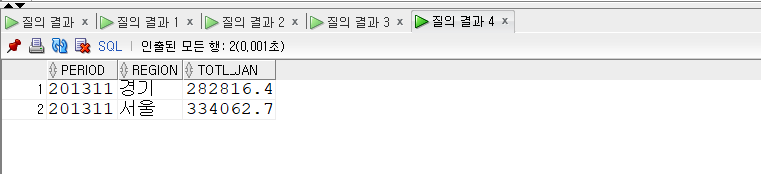
SELECT period , region , SUM(loan_jan_amt) totl_jan FROM kor_loan_status WHEREperiod='201311' GROUPBYperiod, region HAVINGSUM(loan_jan_amt) >100000 ORDERBY region;
ROLLUP
ROLLUP(expr1, expr2, …)
ROLLUP은 expr로 명시한 표현식을 기준으로 집계한 결과, 즉 추가적인 집계 정보를 보여 준다.
ROLLUP 절에 명시할 수 있는 표현식에는 그룹핑 대상, 즉 SELECT 리스트에서 집계 함수를 제외한 컬럼 등의 표현식이 올 수 있다.
명시한 표현식 수와 순서(오른쪽에서 왼쪽 순으로)에 따라 레벨 별로 집계한 결과가 반환된다.
표현식 개수가 n개이면 n+1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계된다.
1 2 3 4 5 6 7 8 9
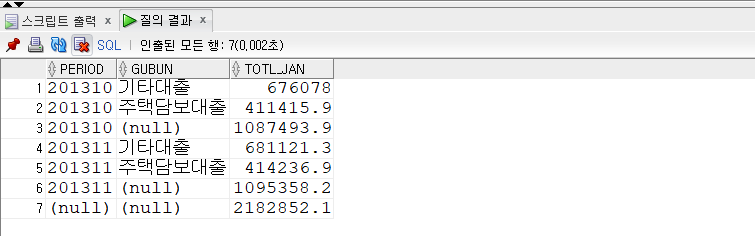
-- 2013년 1개월 총 잔액만 구한다. -- ROLLUP : 소그룹간의 합계를 계산함 SELECT period , gubun , SUM(loan_jan_amt) totl_jan FROM kor_loan_status WHEREperiodLIKE'2013%' GROUPBYROLLUP(period, gubun);
CUBE
CUBE(expr1, expr2, …)
ROLLUP과 CUBE는 GROUP BY절에서 사용되어 그룹별 소계를 추가로 보여 주는 역할을 한다.
ROLLUP이 레벨별로 순차적 집계를 했다면, CUBE는 명시한 표현식 개수에 따라 가능한 모든 조합별로 집계한 결과를 반환한다.
CUBE는 2의(expr 수)제곱 만큼 종류별로 집계 된다.
예를 들어, expr 수가 3이면, 집계 결과의 유형은 총 2^3 = 8개가 된다.
1 2 3 4 5 6 7 8
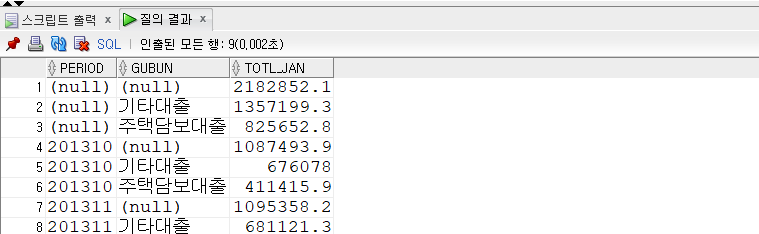
-- CUBE SELECT period , gubun , SUM(loan_jan_amt) totl_jan FROM kor_loan_status WHEREperiodLIKE'2013%' GROUPBYCUBE(period, gubun);
GROUPING SETS
GROUPING SETS (expr1, expr2, expr3)
ROLLUP이나 CUBE처럼 GROUP BY 절에 명시해서 그룹 쿼리에 사용되는 절이다.
GROUP BY 절에 명시했을 때, 괄호 안에 있는 세 표현식별로 각각 집계가 이루어진다.
그러므로 쿼리 형태는 다음과 같다.
((GROUP BY expr1) UNION ALL (GROUP BY expr2) UNION ALL (GROUP BY expr3))
1 2 3 4 5 6 7 8 9
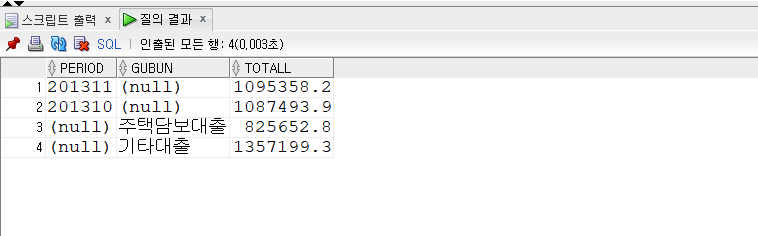
-- GROUPing SETS -- 특정항목에 대한 소계를 계산하는 함수 SELECT period , gubun , SUM(loan_jan_amt) totall FROM kor_loan_status WHEREperiodLIKE'2013%' GROUPBYGROUPING SETS(period, gubun);
-- UNION -- 합집합을 의미한다. -- 두 개의 데이터 집합에서 출발 SELECT goods FROM exp_goods_asia WHERE country ='한국' ORDERBY seq;
SELECT goods FROM exp_goods_asia WHERE country ='일본' ORDERBY seq;
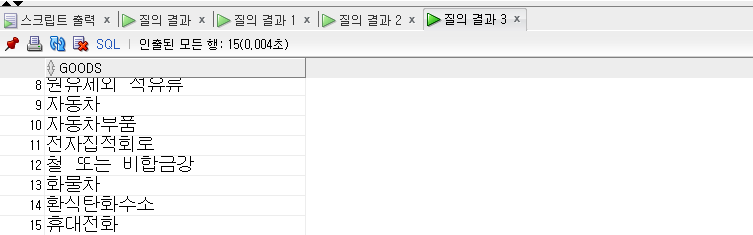
SELECT goods FROM exp_goods_asia WHERE country ='한국' UNION-- 합집합 개념 적용 SELECT goods FROM exp_goods_asia WHERE country ='일본';
중복된 항목 5개를 제외한 15개가 출력되었다.
UNION ALL
UNION ALL은 UNION과 비슷한데 한 가지 다른 것은 중복된 항목도 모두 조회된다는 점이다.
1 2 3 4 5 6 7 8 9
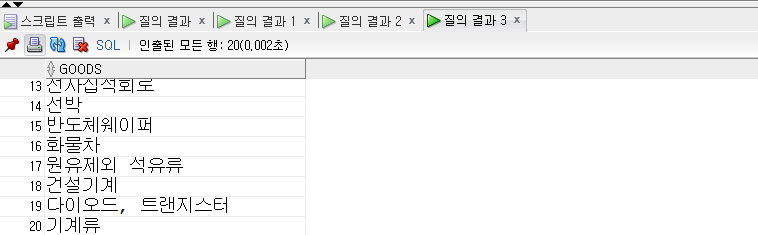
-- UNION ALL
SELECT goods FROM exp_goods_asia WHERE country ='한국' UNIONALL-- 합집합 개념 적용 SELECT goods FROM exp_goods_asia WHERE country ='일본';
중복까지 포함하여 20개의 행의 출력되었다.
INTERSECT
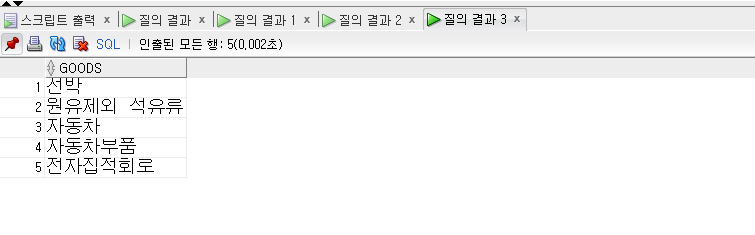
INTERSECT는 합집합이 아닌 교집합을 의미한다.
즉 데이터 집합에서 공통된 항목만 추출해 낸다.
1 2 3 4 5 6 7 8 9
-- INTERSECT -- 합집합이 아니라 교집합을 의미한다. SELECT goods FROM exp_goods_asia WHERE country ='한국' INTERSECT-- 교집합 개념 적용 SELECT goods FROM exp_goods_asia WHERE country ='일본';
MINUS
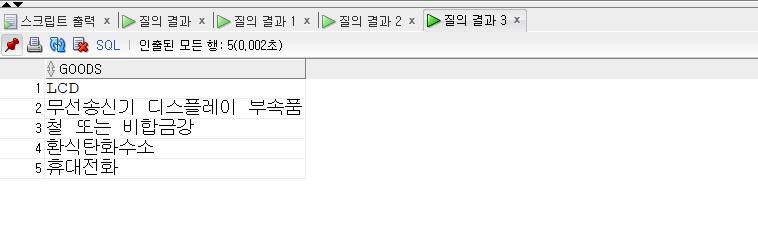
MINUS는 차집합을 의미한다.
즉 한 데이터 집합을 기준으로 다른 데이터 집합과 공통된 항목을 제외한 결과만 추출해 낸다.
1 2 3 4 5 6 7 8 9
-- MINUS -- 차집합을 의미한다. SELECT goods FROM exp_goods_asia WHERE country ='한국' MINUS -- 차집합 개념 적용 SELECT goods FROM exp_goods_asia WHERE country ='일본';