Oracle_practice4
조건식
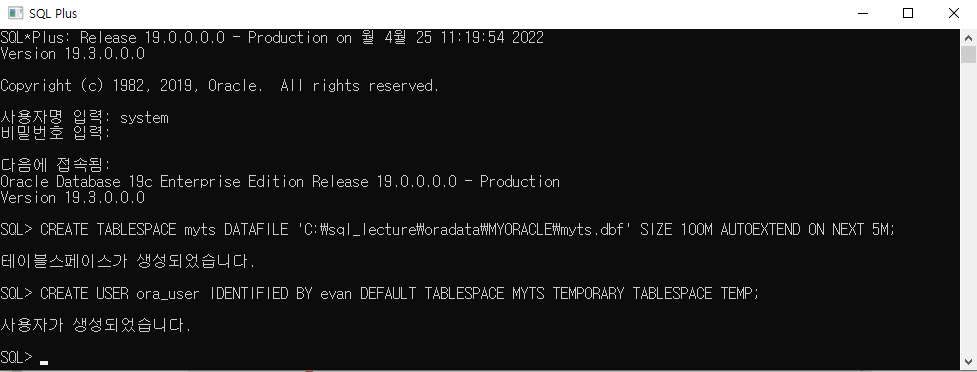
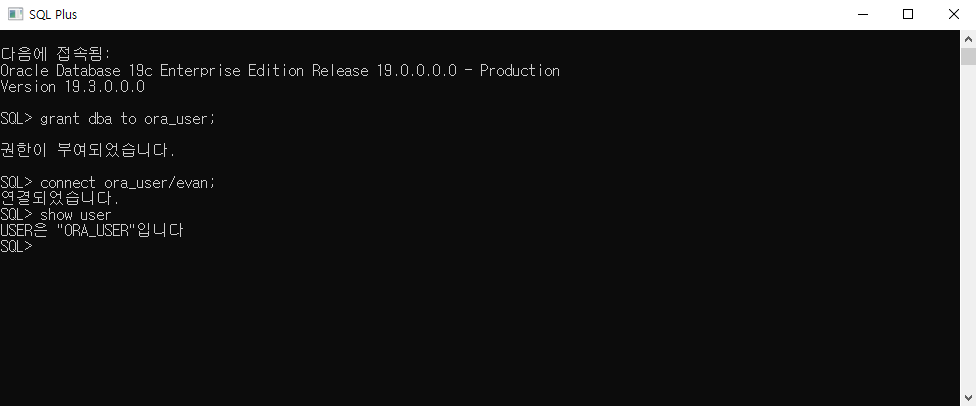
sql developer
sql developer에서 새로운 sql 워크시트를 생성한다.
도구 → sql워크시트 :
오라클 SQL과 PL/SQL을 다루는 기술 92p
연산자
- 교재를 참고하여 코드를 익혀보자
- 연산자는 다음과 같이 사용한다.
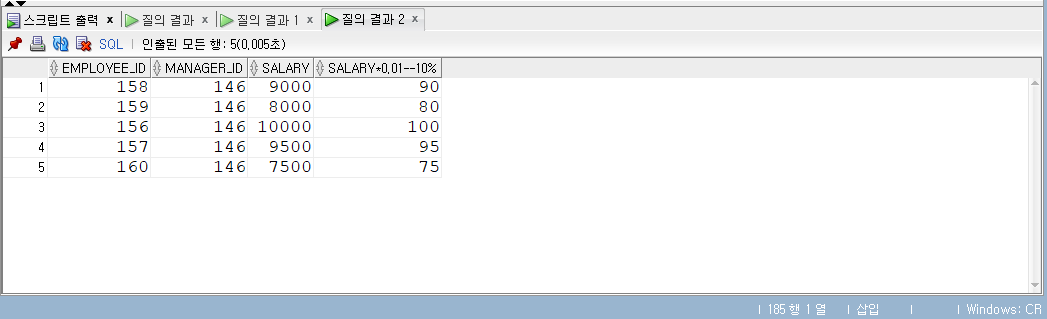
1 | -- 정리 |
표현식
- 표현식이란 한 개 이상의 값과 연산자, SQL 함수 등이 결합된 식이다.
- 조건문은 다음과 같이 사용한다.
- CASE WHEN 조건 THEN ELSE END
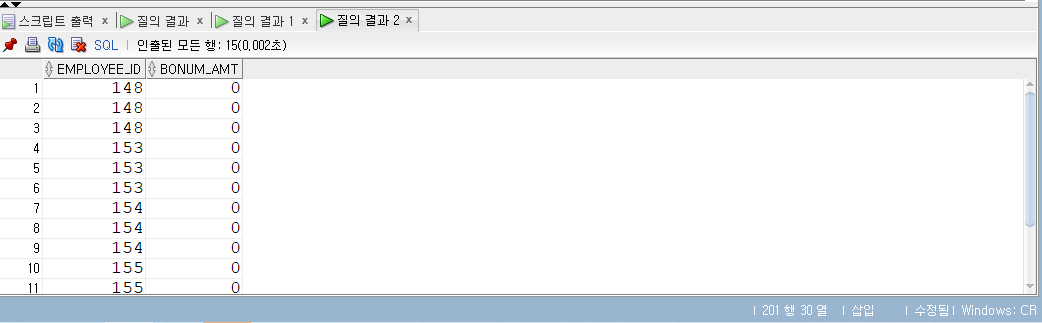
1 | -- 표현식 (조건문) |
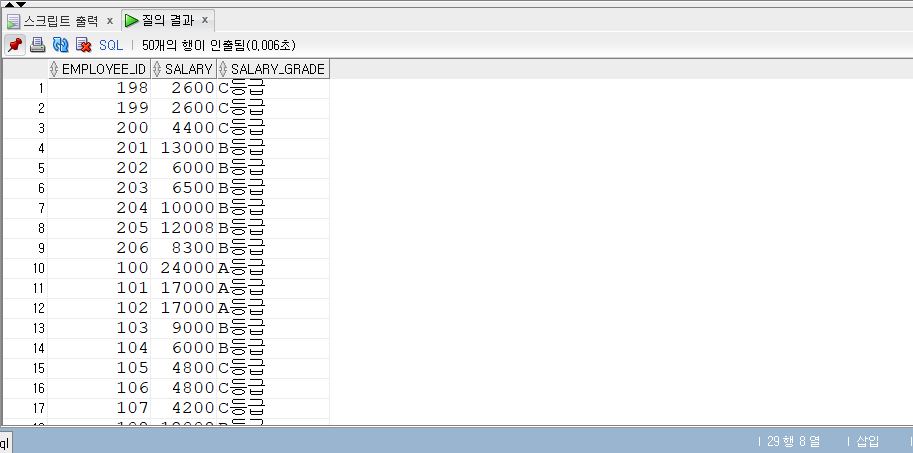
조건식
- 조간 혹은 조건식은 한 개 이상의 표현식과 논리 연산자가 결합된 식으로 TRUE, FALSE, UNKNOWN 세 가지 타입을 반환한다.
- 지금까지 SQL문을 학습하면서 WHERE절에서 사용했던 모든 조건이 바로 조건식에 포함된다.
비교 조건식
- 비교 조건식 : ANY, SOME, ALL 키워드로 비교하는 조건식
ANY
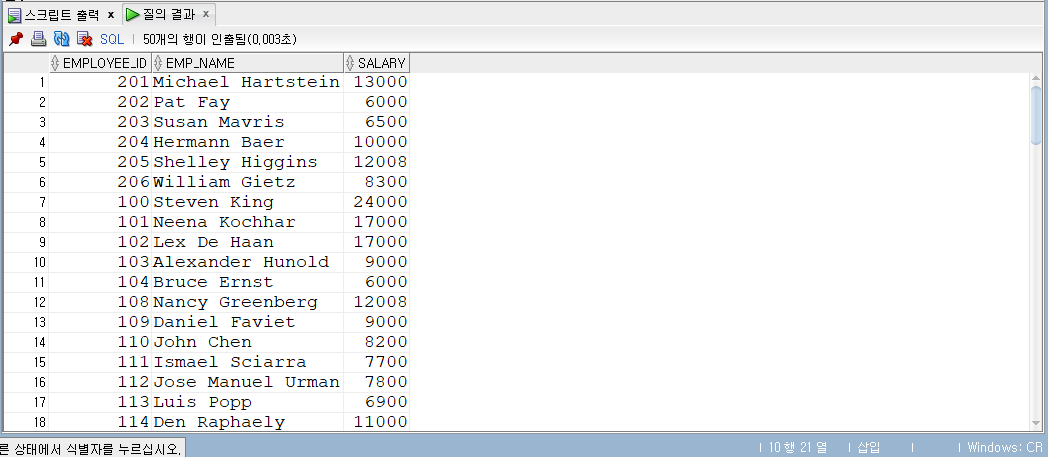
- ANY - OR 조건식을 사용해본다.
1 | -- p.114 |
- ANY가 ‘아무것’이나 ‘하나’라는 뜻이 있으므로 위 코드는 salary(급여)가 2000이나 3000이나 4000 중 하나라도 일치하는 모든 사원을 추출한 것이다.
- 하나라도 일치하면 추출하는 것이므로 ANY는 OR로 표현이 가능하다.
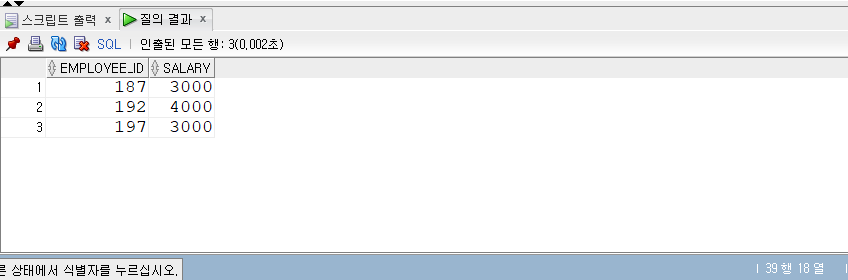
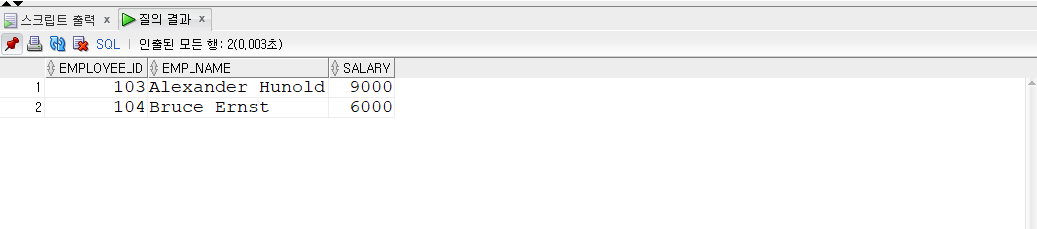
ALL
- ALL 조건문을 사용해본다.
- ALL이므로 모든 조건을 만족하는 것만 추출한다.
- ALL 조건식은 AND 조건으로 변환할 수 있다.
1 | -- ALL |
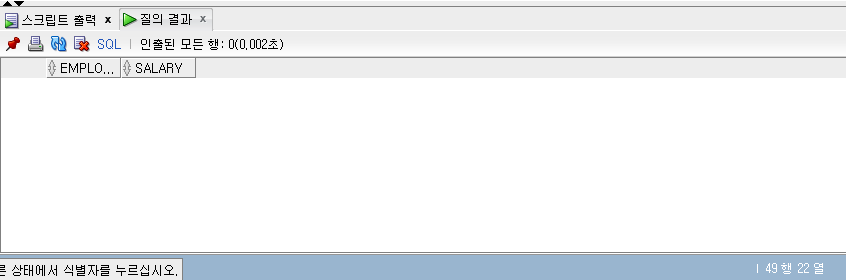
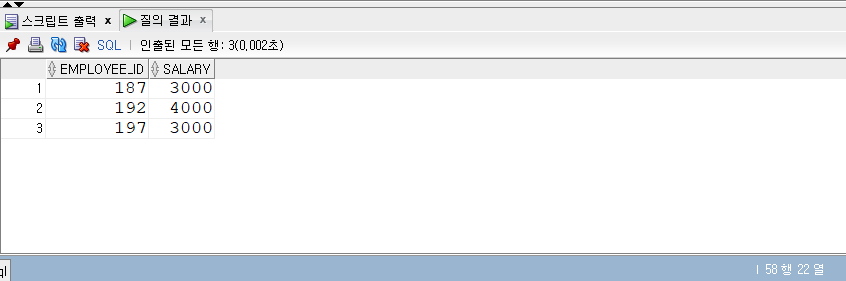
SOME
- SOME 조건문을 사용한다.
- SOME은 ANY와 동일하게 사용되며 동작한다.
1 | -- SOME |
논리 조건식
논리 조건식 = 조건절에서 AND, OR, NOT을 사용하는 조건식
AND는 모든 조건을 만족해야 하고 OR는 여러 조건 중 하나만 만족해도 TRUE를 반환된다.
NOT은 조건식 평가 결과가 **거짓(FALSE)**일 때 원하는 결과, 즉 TRUE를 반환한다.
NOT을 사용해본다.
1 | -- 논리 조건식 |
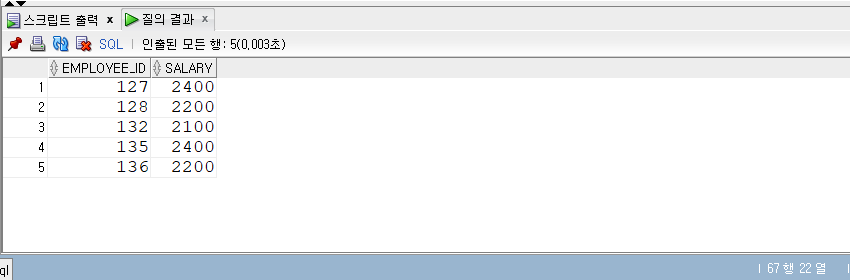
BETWEEN AND 조건식
- BETWEEN은 범위에 해당되는 값을 찾을 때 사용하는데 크거나 같고 작거나 같은 값을 찾는다.
- 따라서 ‘>=’와 ‘<=’ 논리 연산자로 변환이 가능하다.
1 | -- BETWEEN AND 조건식 |
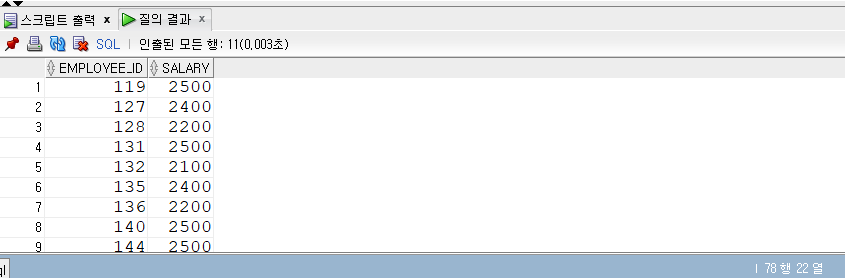
IN 조건식
- OR, ANY와 같은 기능을 수행 가능하다.
- IN 조건식은 조건절에 명시한 값이 포함된 건을 반환하는데 앞에서 배웠던 ANY와 비슷하다.
1 | -- IN 조건식 |
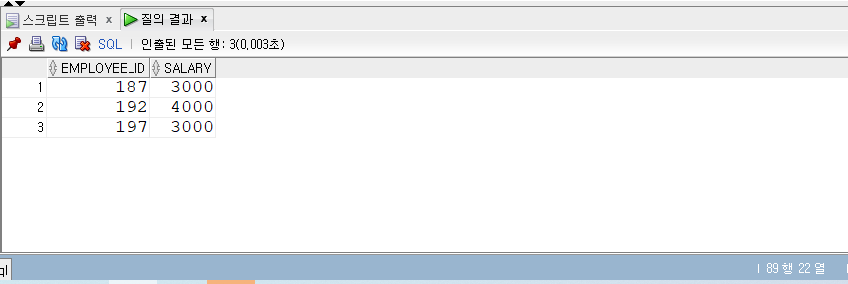
NOT IN 조건식
- IN 조건식과 반대의 결과를 출력한다.
1 | -- NOT IN |
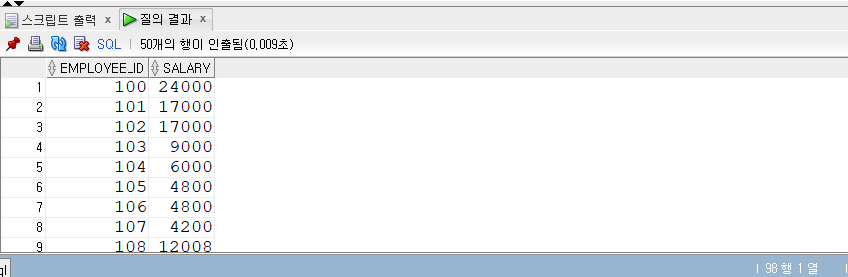
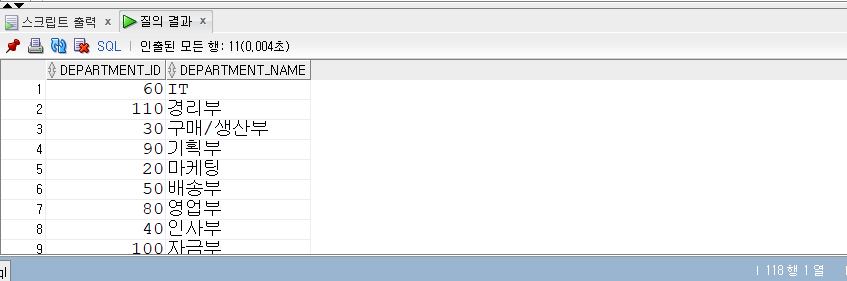
EXISTS 조건식
- XISTS 조건식 역시 IN과 비슷하지만 후행 조건절로 값의 리스트가 아닌 서브 쿼리만 올 수 있다.
- 또한 서브 쿼리 내에서 조인 조건(a.department_id = b.department_id)이 있어야 한다.
1 | -- EXISTS 조건식 |
- 서브쿼리 부분이 메인이다.
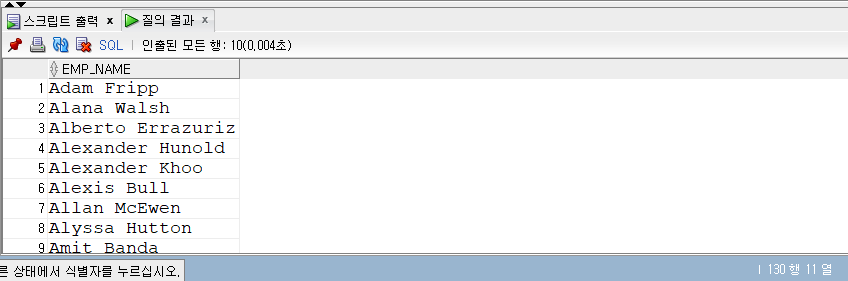
LIKE 조건식
- LIKE 조건식은 문자열의 패턴을 검색할 때 사용하는 조건식이다.
- 예를 들어, 사원 테이블에서 사원이름이 ‘A’로 시작되는 사원을 조회하는 쿼리를 작성한다면 다음과 같이 LIKE 조건식을 사용.
1 | -- LIKE 조건식 |
- Reference : 오라클 SQL과 PL/SQL을 다루는 기술