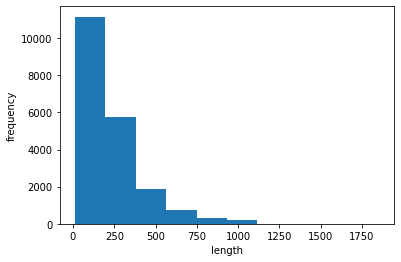
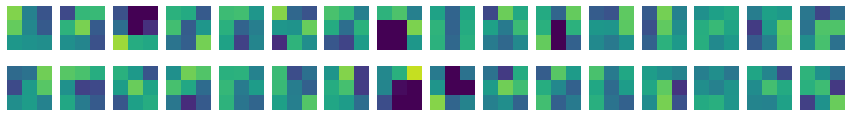import numpy as np #temp_list = [len(x) for x in train_input] # print(temp_list) lengths = np.array([len(x) for x in train_input]) print(np.mean(lengths), np.median(lengths))
239.00925 178.0
1 2 3 4 5
import matplotlib.pyplot as plt plt.hist(lengths) plt.xlabel('length') plt.ylabel('frequency') plt.show()
짧은 단어 100개만 사용
모든 길이를 100에 맞춘다.
“패딩”
데이터의 갯수는 20000, 전체 길이는 100으로 맞춤
1 2 3 4
from tensorflow.keras.preprocessing.sequence import pad_sequences train_seq = pad_sequences(train_input, maxlen = 100)
from tensorflow import keras model = keras.Sequential() model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500))) model.add(keras.layers.Dense(1, activation='sigmoid'))
머신러닝 엔지니어 : MLOps (선행되어야 하는 코드 조건, Pipeline 형태로 구축)
머신러닝 코드 자동화 가능! 운영 가능!
개발업계의 최상위 연봉자!
데이터 불러오기
1 2 3 4
import pandas as pd import numpy as np data = pd.read_csv('https://raw.githubusercontent.com/MicrosoftDocs/ml-basics/master/data/daily-bike-share.csv') data.info()
from sklearn.preprocessing import StandardScaler, OrdinalEncoder, OneHotEncoder from sklearn.impute import SimpleImputer from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline
# 데이터 타입 3가지 # 수치형 데이터, 문자열 데이터 # 문자열 데이터 : 범주형(명목형, 서열형 데이터로 구분됨) numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='mean')) ,('scaler', StandardScaler()) ])
from tensorflow import keras keras.layers.Conv2D(10, # 필터(즉, 도장)의 개수 kernel_size=(3,3), # 필터에 사용할 커널의 크기 activation = 'relu') # 활성화 함수 지정
<keras.layers.convolutional.Conv2D at 0x7f6c99df5c90>
패딩 (padding)
입력 배열의 주위를 가상의 원소로 채우는 것.
실제 입력값이 아니기 때문에 패딩은 0으로 채운다.
실제 값은 0으로 채워져 있기에 계산에 영향을 미치지 않는다.
세임 패딩 (same padding) : 입력 주위에 0으로 패딩 하는 것
밸리드 패딩 (valid padding) : 패딩 없이 순수한 입력 배열에서만 합성곱하여 특성 맵을 마드는 것
패딩의 목적
배열의 크기를 조정하더라도 이미지 원 특성이 손실되는 것을 방지하는 것
스트라이드 (stride)
기존에 합성곱 연산은 좌우, 위아래로 한 칸씩 이동했다.
두 칸씩 건너뛸 수도 있다.
이런 이동의 크기를 ‘스트라이드’라고 한다.
두 칸씩 이동하면 특성 맵의 크기가 더 작아진다.
커널 도장을 찍는 횟수가 줄어들기 때문.
디폴트는 1칸 이동이다.
1 2 3 4 5
keras.layers.Conv2D(10, # 필터(즉, 도장)의 개수 kernel_size=(3,3), # 필터에 사용할 커널의 크기 activation='relu', # 활성화 함수 지정 padding = 'same', # 세임 패딩 strides = 1) # 1칸씩 이동
<keras.layers.convolutional.Conv2D at 0x7f6c992ba8d0>
풀링 (pooling)
값을 추출
100 x 100 이미지 –> (수치로) 주요 이미지의 특성만 뽑은 후, 원 이미지와 같게 만듬 (50 x 50)
합성곱 층에서 만든 특성 맵의 가로세로 크기를 줄이는 역할을 수행한다.
특성맵의 크기를 줄이지는 않는다.
합성곱처럼 입력 위를 지나가면서 도장을 찍는다.
하지만, 풀링에는 가중치가 없다.
최대 풀링 (max pooling)
도장을 찍은 영역에서 가장 큰 값을 고른다.
평균 풀링 (average pooling)
도장을 찍은 영역에서 평균값을 계산한다.
특성 맵이 여러 개라면 동일한 작업을 반복한다.
즉, 10개의 특성 맵이 있다면 풀링을 거친 특성맵도 10개가 된다.
풀링 영역은 풀링의 크기만큼 이동한다.
즉, 겹치지 않고 이동한다.
풀링의 크기가 (2,2)이면 가로세로 두 칸씩 이동한다.
풀링은 가중치가 없고 풀링 크기와 스트라이드가 같다.
1 2 3
keras.layers.MaxPooling2D(2, # 풀링의 크기. 대부분은 2로 둔다. strides=2, # 2칸씩 이동. 풀링의 크기와 같게 설정된다. padding='valid') # 풀링은 패딩을 하지 않으므로 'valid'로 지정.
<keras.layers.pooling.MaxPooling2D at 0x7f6c99253e90>
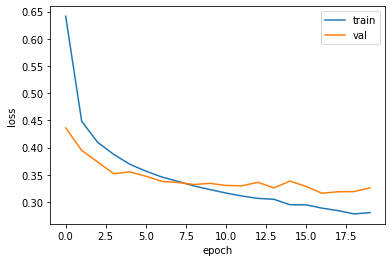
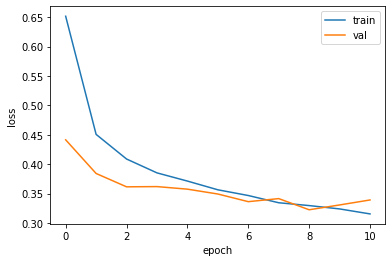
with tf.device('/device:GPU:0'): # GPU 잡는 법 history = model.fit(train_scaled, train_target, epochs=10, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
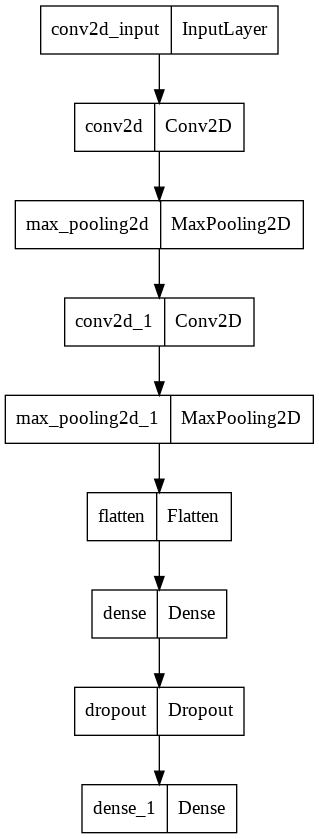
[<keras.layers.convolutional.Conv2D at 0x7fe1487e19d0>,
<keras.layers.pooling.MaxPooling2D at 0x7fe1d0495b50>,
<keras.layers.convolutional.Conv2D at 0x7fe148c92590>,
<keras.layers.pooling.MaxPooling2D at 0x7fe1487fa9d0>,
<keras.layers.core.flatten.Flatten at 0x7fe1446bad10>,
<keras.layers.core.dense.Dense at 0x7fe1446ba210>,
<keras.layers.core.dropout.Dropout at 0x7fe14465cf50>,
<keras.layers.core.dense.Dense at 0x7fe14465dcd0>]
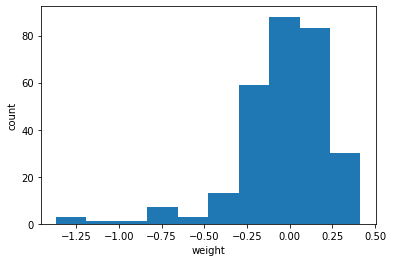
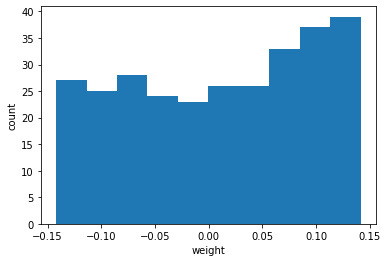
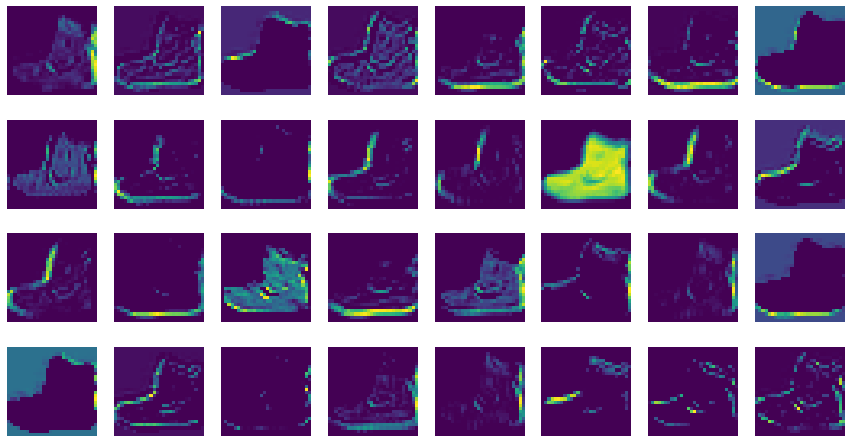
for i inrange(2): for j inrange(16): axs[i, j].imshow(conv_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5) # vmin, vmax는 맷플롯립의 컬러맵으로 표현할 범위를 지정 axs[i, j].axis('off')
for i inrange(2): for j inrange(16): axs[i, j].imshow(no_training_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5) # vmin, vmax는 맷플롯립의 컬러맵으로 표현할 범위를 지정 axs[i, j].axis('off')
plt.show()
전체적으로 가중치가 밋밋하게 초기화되었다.
이 그림을 훈련이 끝난 이전 가중치와 비교해보자.
합성곱 신경망이 패현MNIST 데이터셋의 부류 정확도를 높이기 위해 유용한 패턴을 학습했다는 사실을 눈치챌 수 있다.
from tensorflow import keras (train_input, train_target), (test_input, test_target)= keras.datasets.fashion_mnist.load_data() # load.data()함수는 훈련 데이터와 테스트 데이터를 나누어 반환한다.
데이터 확인
훈련 데이터
60,000개 이미지, 이미지 크기는 28x28
타깃은 60,000개 원소가 있는 1차원 배열
1
print(train_input.shape, train_target.shape)
(60000, 28, 28) (60000,)
테스트 세트
10,000개의 이미지로 이루어짐
1
print(test_input.shape, test_target.shape)
(10000, 28, 28) (10000,)
이미지 시각화
1 2 3 4 5 6
import matplotlib.pyplot as plt fig, axs = plt.subplots(1, 10, figsize=(10,10)) for i inrange(10): axs[i].imshow(train_input[i], cmap='gray_r') axs[i].axis('off') plt.show()
타겟 값 리스트
패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성된다.
같은 숫자가 나온다면 타깃이 같은 두 샘플은 같은 종류의 옷이다.
1
print([train_target[i] for i inrange(10)])
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
실제 타겟값의 값을 확인
각 라벨당 6000개의 이미지 존재 60,000개
즉, 각 의류마다 6,000개의 샘플이 들어있다.
1 2
import numpy as np print(np.unique(train_target, return_counts = True))
Flatten 클래스를 층처럼 입렬층과 은닉층 사잉에 추가하기 때문에 이를 층이라 부른다.
다음 코드처럼 입력층 바로 뒤에 추가한다.
1 2 3 4 5 6
model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) # 기존 코드 비교 model.add(keras.layers.Dense(100, activation='relu')) # relu 로 변경 model.add(keras.layers.Dense(10, activation='softmax'))
적응적 학습률을 사용하는 이 3개의 클래스는 learning_rate 매개변수의 기본값을 0.001로 두고 사용한다.
Adam 클래스의 매개변수 기본값을 사용해 패션 MNIST 모델을 훈련해본다.
일단 모델을 다시 생성한다.
1 2 3 4
model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) # 기존 코드 비교 model.add(keras.layers.Dense(100, activation='relu')) # relu 로 변경 model.add(keras.layers.Dense(10, activation='softmax'))
compile() 메서드의 optimizer를 ‘adam’으로 설정하고 5번의 에포크 동안 훈련한다.
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 1s 0us/step
26435584/26421880 [==============================] - 1s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
모델을 만든다.
사용자 정의함수를 작성함
if 구문을 제외하면 7-2의 코드와 동일하다.
if 구문의 역할은 model_fn() 함수에 케라스 층을 추가하면 은닉층 뒤어 또 하나의 층을 추가하는 것이다.
모델 구조를 출력해본다.
1 2 3 4 5 6 7 8 9 10
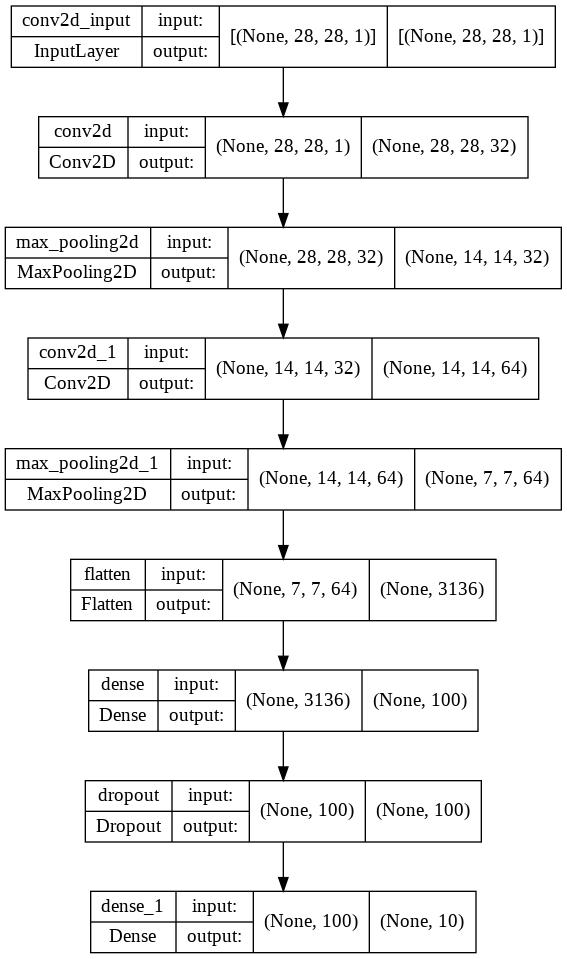
defmodel_fn(a_layer=None): model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28,28))) model.add(keras.layers.Dense(100, activation='relu')) if a_layer: model.add(a_layer) model.add(keras.layers.Dense(100, activation='softmax')) return model model = model_fn() model.summary()
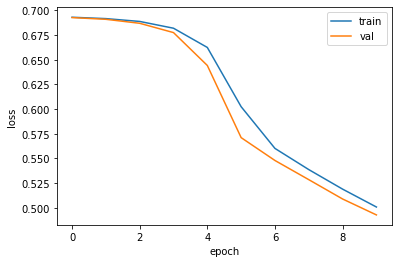
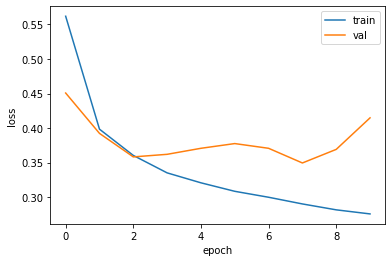
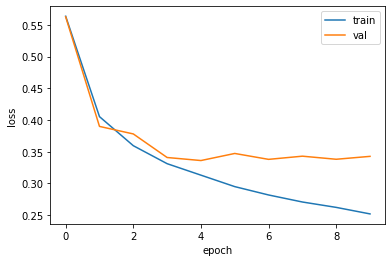
model = model_fn(keras.layers.Dropout(0.3)) # 30% 드롭아웃 model.compile(optimizer = 'adam', loss='sparse_categorical_crossentropy', metrics='accuracy') # adam 추가
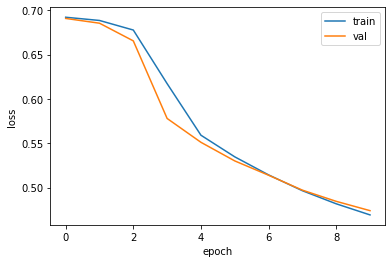
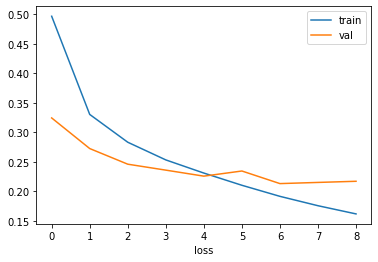
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, # 수치 조정 validation_data=(val_scaled, val_target))
defdraw_fruits(arr, ratio=1): n = len(arr) # n은 샘플 개수입니다 # 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다. rows = int(np.ceil(n/10)) # 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다. cols = n if rows < 2else10 fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False) for i inrange(rows): for j inrange(cols): if i*10 + j < n: # n 개까지만 그립니다. axs[i, j].imshow(arr[i*10 + j], cmap='gray_r') axs[i, j].axis('off') plt.show()