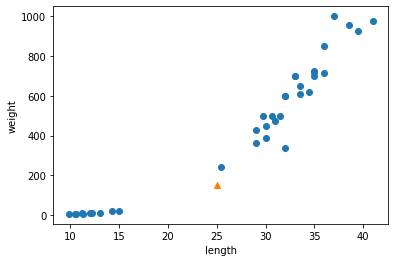
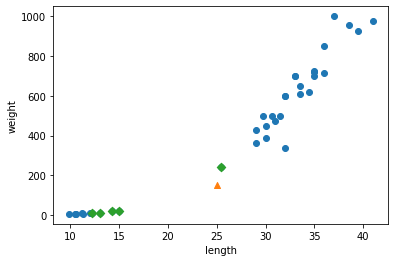
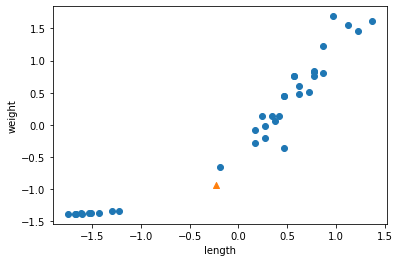
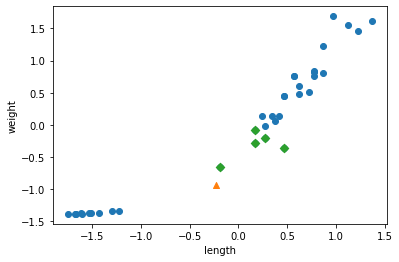
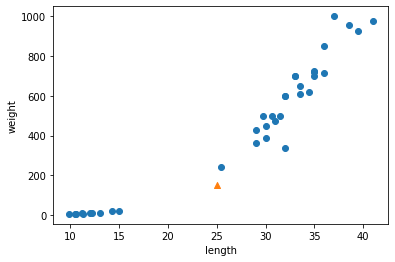
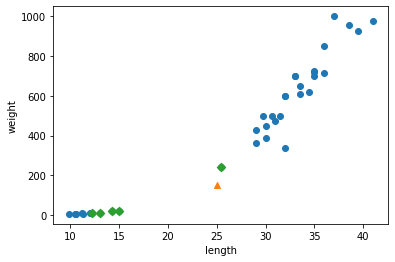
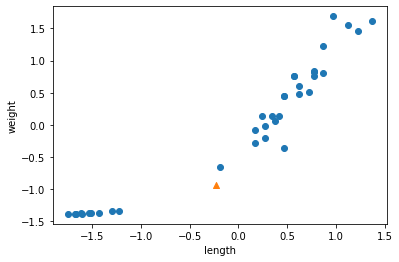
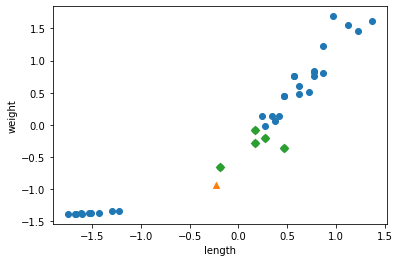
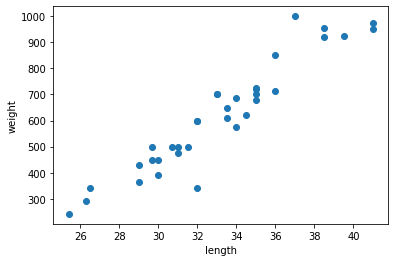
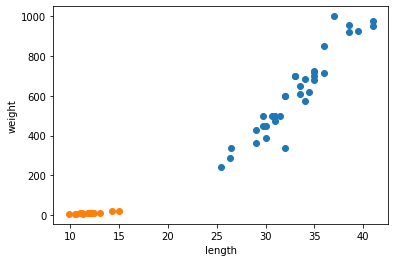
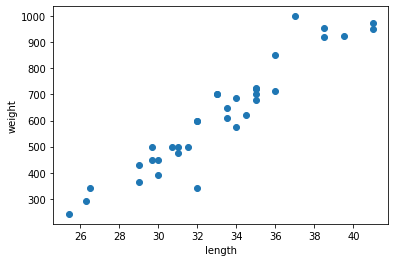
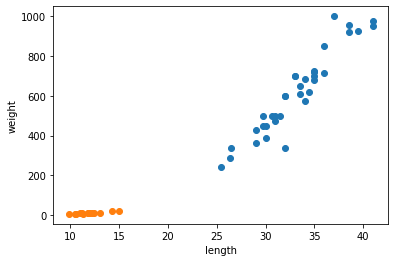
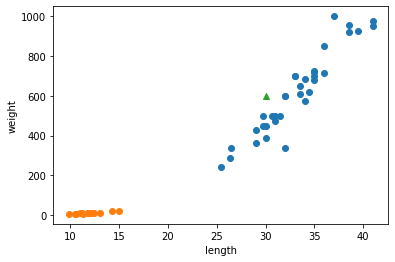
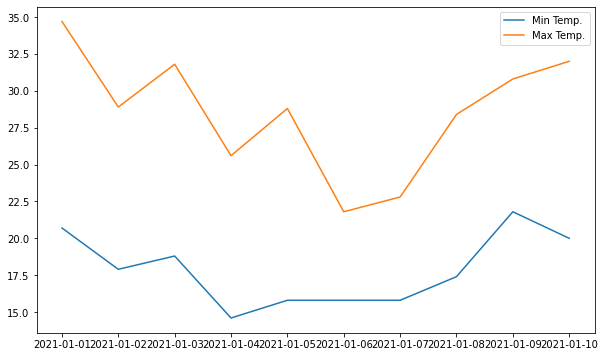
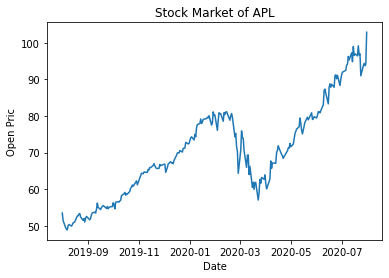
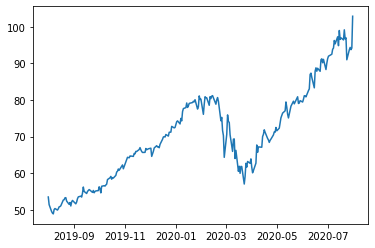
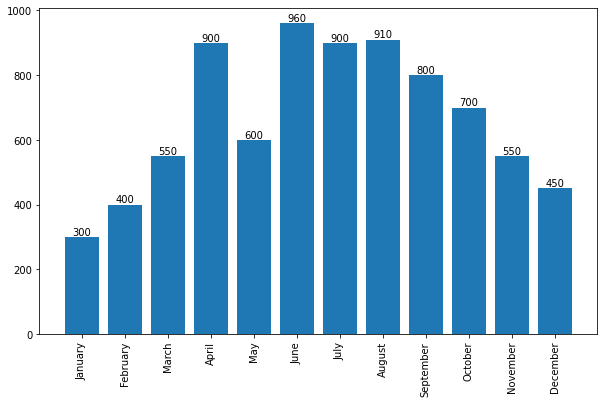
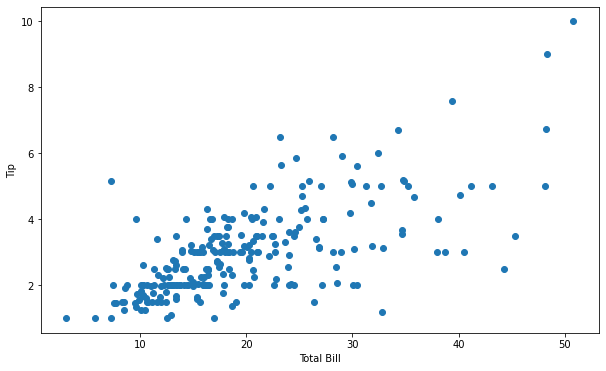
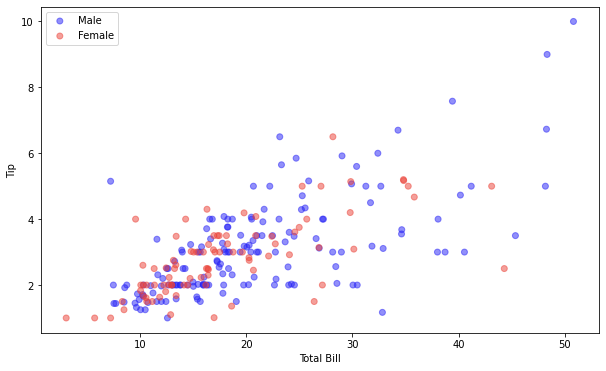
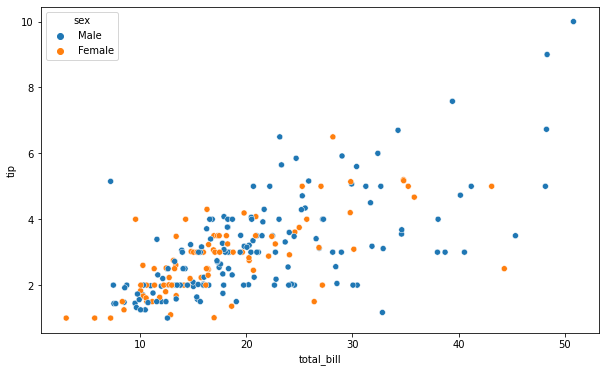
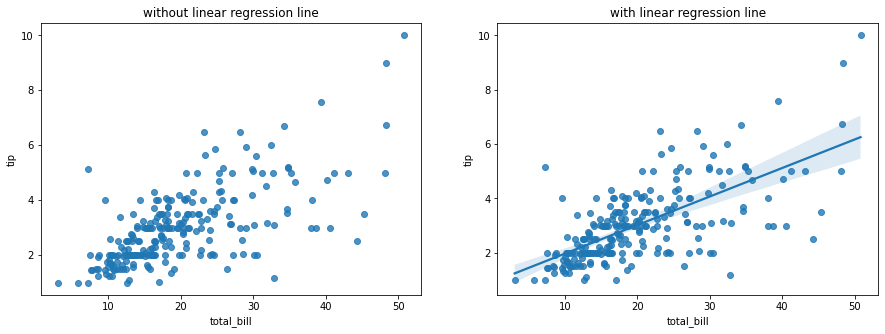
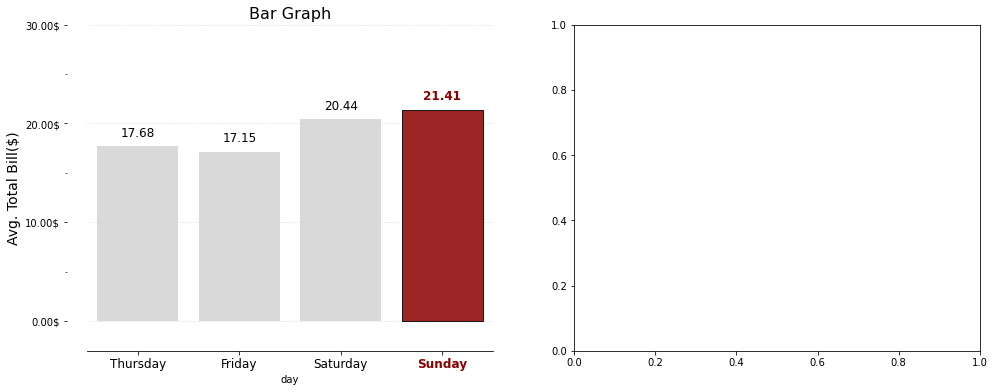
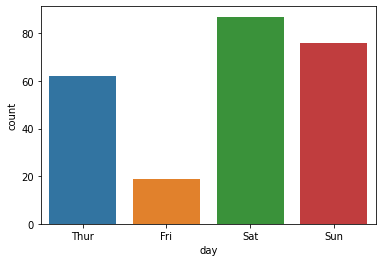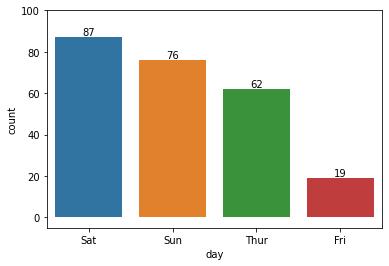for plot in ax.patches: # matplotlib 와 같은 역할을 수행한다. print(plot) height = plot.get_height() ax.text(plot.get_x() + plot.get_width()/2., height, height, ha = 'center', va = 'bottom')
import matplotlib.pyplot as plt import seaborn as sns import numpy as np from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter)
<script>
const buttonEl =
document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-0adace20-cbb2-4908-846b-7f1dd49ea7cb');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
13.Gotchas (잡았다!)
연산 수행 시 다음과 같은 예외 상황(Error)을 볼 수도 있다.
1 2
if pd.Series([False, True, False]): print("I was true")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-129-5c782b38cd2f> in <module>()
----> 1 if pd.Series([False, True, False]):
2 print("I was true")
/usr/local/lib/python3.7/dist-packages/pandas/core/generic.py in __nonzero__(self)
1536 def __nonzero__(self):
1537 raise ValueError(
-> 1538 f"The truth value of a {type(self).__name__} is ambiguous. "
1539 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1540 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
이런 경우에는 any(), all(), empty 등을 사용해서 무엇을 원하는지를 선택 (반영)해주어야 한다.
1 2
if pd.Series([False, True, False])isnotNone: print("I was not None")
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:4: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
after removing the cwd from sys.path.
Revenue
Lemon
max
min
sum
mean
max
min
sum
mean
Location
Beach
95.5
43.0
1002.8
58.988235
162
76
2020
118.823529
Park
134.5
41.0
1178.2
78.546667
176
71
1697
113.133333
<script>
const buttonEl =
document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-7a3b6989-de2d-4a76-8bd8-66538dc5863c');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
classPerson: """ 사람을 표현하는 클래스 ... Attributes ---------- name : str name of the person age : int age of the person ... ... Methods ---------- info(additional=""): prints the person's name and age """ def__init__(self, name, age): """ Constructs all the neccessary attributes for the person object Parameters ---------- name : str name of the person age : int age of the person """
self.name = name self.age = age
definfo(self, additional=None): """ 귀찮음... Parameters ---------- additional : str, optional more info to be displayed (Default is None) Returns ------- None """
print(f'My name is {self.name}. i am {self.age} years old.' + additional)
if __name__ == "__main__": person = Person("Evan", age = 20) person.info("나의 직장은 00이야") help(Person)
My name is Evan. i am 20 years old.나의 직장은 00이야
Help on class Person in module __main__:
class Person(builtins.object)
| Person(name, age)
|
| 사람을 표현하는 클래스
| ...
|
| Attributes
| ----------
| name : str
| name of the person
|
| age : int
| age of the person
| ...
| ...
|
| Methods
| ----------
|
| info(additional=""):
| prints the person's name and age
|
| Methods defined here:
|
| __init__(self, name, age)
| Constructs all the neccessary attributes for the person object
|
| Parameters
| ----------
| name : str
| name of the person
|
| age : int
| age of the person
|
| info(self, additional=None)
| 귀찮음...
|
| Parameters
| ----------
| additional : str, optional
| more info to be displayed (Default is None)
|
| Returns
| -------
| None
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| person = <__main__.Person object>
# 더하기, 빼기 기능이 있는 클래스 classCalculator: def__init__(self): self.result = 0 defadd(self,num): self.result += num return self.result defsub(self,num): self.result -= num return self.result
# 4칙연산 기능이 달린 클래스 정의 # 일단 더하기만 구현 classFourCal: defsetdata(self, first, second): self.first = first self.second = second defadd(self): result = self.first + self.second return result
# 4칙연산 기능이 달린 클래스 정의 classFourCal: defsetdata(self, first, second): self.first = first self.second = second defadd(self): result = self.first + self.second return result defmul(self): result = self.first * self.second return result defsub(self): result = self.first - self.second return result defdiv(self): result = self.first / self.second return result
# setdata를 생성자 __init__으로 변경 classFourCal: def__init__(self, first, second): self.first = first self.second = second defadd(self): result = self.first + self.second return result defmul(self): result = self.first * self.second return result defsub(self): result = self.first - self.second return result defdiv(self): result = self.first / self.second return result
a = FourCal(4, 2) # 이전과 달리 매개변수도 작성해야 작동. print(a.mul()) print(a.sub()) print(a.div())
8
2
2.0
클래스의 상속
FourCal 클래스는 만들어 놓았으므로 FourCal 클래스를 상속하는 MoreFourCal 클래스는 다음과 같이 간단하게 만들 수 있다.
# np.arange(5) -> 0 부터 시작하는 5개의 배열 생성 temp_arr = np.arange(5) temp_arr
array([0, 1, 2, 3, 4])
1 2 3
# np.arange(1, 11, 3) -> 1 부터 11까지 3만큼 차이나게 배열 생성 temp_arr = np.arange(1, 11, 3) temp_arr
array([ 1, 4, 7, 10])
1 2 3 4 5 6 7
# np.zeros -> 0으로 채운 배열 만들기 zero_arr = np.zeros((2,3)) print(zero_arr) print(type(zero_arr)) print(zero_arr.shape) print(zero_arr.ndim) print(zero_arr.dtype) # dype = data type
# 5보다 큰 값은 곱하기 2, 2보다 작은 값은 더하기 100 condlist = [temp_arr > 5, temp_arr <2] # 조건식 choielist = [temp_arr *2, temp_arr + 100] # 같은 위치의 조건 만족 시, 설정한 대로 변환 np.select(condlist, choielist, default = temp_arr)
deftemp(content, letter): """content 안에 있는 문자를 세는 함수입니다. Args: content(str) : 탐색 문자열 letter(str) : 찾을 문자열 Returns: int """ print("함수 테스트")
cnt = len([char for char in content if char == letter]) return cnt
if __name__ == "__main__": help(temp) docstring = temp.__doc__ print(docstring)
Help on function temp in module __main__:
temp(content, letter)
content 안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
content 안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
help()
위 코드에서 help()는 본인이 작성한 주석을 바탕으로 문서화한다.
리스트 컴프리헨션
for-loop 반복문을 한 줄로 처리
리스트 안에 반복문을 작성할 수 있다
1 2 3 4 5 6 7 8 9 10 11 12 13
my_list = [[10], [20,30]] print(my_list)
flattened_list = [] for value_list in my_list: print(value_list) for value in value_list: print(value) flattened_list.append(value)
# 사용자 정의함수의 문서화 defmean_and_median(value_list): """ 숫자 리스트의 요소들의 평균과 중간값을 구하는 코드를 작성해라 Args: value_list (iterable of int / float) : A list of int numbers Returns: tuple(float, float) """ #평균 mean = sum(value_list) / len(value_list)
#중간값 midpoint = int(len(value_list) / 2) iflen(value_list) % 2 == 0: median = (value_list[midpoint - 1] + value_list[midpoint]) / 2 else: median = value_list[midpoint] return mean, median
데코레이터, 변수명 immutable or mutable, context manager는 jump to python 페이지에 없기에 따로 찾아 공부해야 한다.
함수 실습
여러 개의 입력값을 받는 함수
1 2 3 4 5 6 7
# 여러 개의 입력값을 받는 함수 만들기 defadd_many(*args): result = 0 for i in args: result = result + i return result
1 2 3 4 5 6 7
# 위 함수를 이용해보자 result = add_many(1,2,3) print(result)
#위 함수는 매개변수가 몇 개든 작동한다. result = add_many(1,2,3,4,5,6,7,8,9,10) print(result)
6
55
1 2 3 4 5 6 7 8 9 10 11
# 여러 개의 입력값을 받는 함수 만들기2 defadd_mul(choice, *args): if choice == "add": result=0 for i in args: result = result + i elif choice == "mul": result = 1 for i in args: result = result * i return result
1 2 3 4 5 6
# 위 함수를 이용해보자 result = add_mul('add', 1, 2, 3, 4, 5) print(result)
result = add_mul('mul', 1, 2, 3, 4, 5) print(result)
defsay_myself(name, old, man=True): # boolean 값을 이용하여 설정 print("나의 이름은 %s 입니다." % name) print("나이는 %d살입니다." % old) if man : print("남자입니다.") # True else : print("여자입니다.") # False
# Q6 사용자의 입력을 파일(test.txt)에 저장하는 프로그램을 작성해 보자. #(단 프로그램을 다시 실행하더라도 기존에 작성한 내용을 유지하고 새로 입력한 내용을 추가해야 한다.) # 다시 풀어보자
user_input = input("저장할 내용을 입력하세요:") f = open('test.txt', 'a') # 내용을 추가하기 위해서 'a'를 사용 f.write(user_input) f.write("\n") # 입력된 내용을 줄 단위로 구분하기 위한 개행 문자 사용 f.close()
저장할 내용을 입력하세요:hihi
1 2 3 4 5 6 7 8 9 10 11
# Q7 다음과 같은 내용을 지닌 파일 test.txt가 있다. 이 파일의 내용 중 "java"라는 문자열을 "python"으로 바꾸어서 저장해 보자. # 다시 풀어보자 f = open('test.txt', 'r') body = f.read() f.close()
print(greeting[:]) print(greeting[6:]) print(greeting[:6]) # 시작 인덱스 ~ 끝 인덱스-1 만큼 출력하므로 Hello print(greeting[3:9]) print(greeting[0:9:2]) # 3번째 index는 몇번 건너띄는 것인지 표시
Hello kaggle!
kaggle!
Hello
lo kag
Hlokg
리스트
시퀀스 데이터 타입
데이터에 순서가 존재하냐! 슬라이실이 가능해야 함.
대관호 ([‘값1’, ‘값2’, ‘값3’])
1 2 3 4 5 6 7 8 9 10 11
a = [] # 빈 리스트 a_func = list() # 빈 리스트 생성 b = [1] # 숫자가 요소가 될 수 있다. c = ['apple'] # 문자열도 요소가 될 수 있다. d = [1, 2, ['apple']] # 리스트 안에 또 다른 리스트 요소를 넣을 수 있다.
#Q10 딕셔너리 a에서 'B'에 해당되는 값을 추출해 보자. dict_00 = {'A':90, 'B':80, 'C':70} d = dict_00.pop('B') print(dict_00) print(d)
{'A': 90, 'C': 70}
80
1 2 3 4 5 6
#Q11 a 리스트에서 중복 숫자를 제거해 보자. # 다시 풀어보자 a = [1, 1, 1, 2, 2, 3, 3, 3, 4, 4, 5] aset = set(a) b = list(aset) print(b)
[1, 2, 3, 4, 5]
Q12 파이썬은 다음처럼 동일한 값에 여러 개의 변수를 선언할 수 있다. 다음과 같이 a, b 변수를 선언한 후 a의 두 번째 요솟값을 변경하면 b 값은 어떻게 될까? 그리고 이런 결과가 오는 이유에 대해 설명해 보자. a = b = [1, 2, 3] a[1] = 4 print(b)
1 2 3 4 5
#Q12 a = b = [1,2,3] a[1] = 4 print(b) # a=b 라고 설정했기 때문에 다음 결과가 나옵니다.
[1, 4, 3]
3장 연습문제
1 2 3 4 5 6 7 8
#Q1 다음 코드의 결괏값은? a = "Life is too short, you need python"
if"wife"in a : print("wife") elif"python"in a and"you"notin a : print("python") elif"shirt"notin a : print("shirt") elif"need"in a : print("need") else: print("none")
shirt
1 2 3 4 5 6 7 8 9
#Q2 while문을 사용해 1부터 1000까지의 자연수 중 3의 배수의 합을 구해 보자. count = 1 sum = 0 while count < 1000 : count = count + 1 if count % 3 == 0 : sum = sum + count
print(sum)
166833
1 2 3 4 5
#Q3 while문을 사용하여 다음과 같이 별(*)을 표시하는 프로그램을 작성해 보자. count = 0 while count < 5: count = count + 1 print("*" * count)
*
**
***
****
*****
1 2 3
#Q4 for문을 사용해 1부터 100까지의 숫자를 출력해 보자. for num inrange(100): print(num+1)
1 2 3 4 5 6 7 8 9 10
#Q5 A 학급에 총 10명의 학생이 있다. 이 학생들의 중간고사 점수는 다음과 같다. #[70, 60, 55, 75, 95, 90, 80, 80, 85, 100] #for문을 사용하여 A 학급의 평균 점수를 구해 보자. sum = 0 a_class = [70, 60, 55, 75, 95, 90, 80, 80, 85, 100] for num in a_class : sum = sum + num
mean = sum / len(a_class) print(mean)
79.0
1 2 3 4 5 6 7 8 9 10 11 12 13
#Q6 리스트 중에서 홀수에만 2를 곱하여 저장하는 다음 코드가 있다.
numbers = [1, 2, 3, 4, 5] result = [] for n in numbers: if n % 2 == 1: result.append(n*2) # 위 코드를 리스트 내포(list comprehension)를 사용하여 표현해 보자. # 다시 풀어보자 numbers = [1, 2, 3, 4, 5] result = [n*2for n in numbers if n%2==1] print(result)