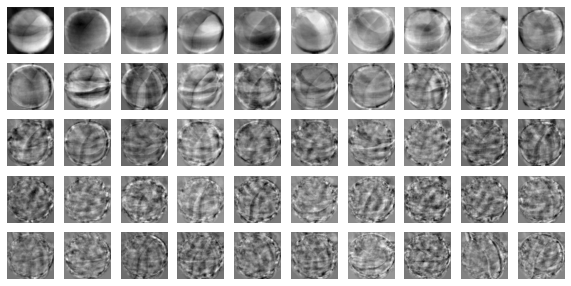
chapter_7_1
딥러닝
인공신경망 1943년 즈음 등장
1차 융성기 ~ 1960 후반
로봇이 인간들과 함께 살 것이다 예언
XOR 문제 해결 못함
AI 연구 겨울 찾아옴
대안 : 최근접이웃, 결정트리, 서포트벡터머신 등
토론토 대학 AI 연구소 (역전파 알고리즘 개발)
CNN 알고리즘 (1980년대 후반)
-2차 융성시기 ~ 1990년대 후반
CNN, RNN 알고리즘 등장
연산 속도 문제/정확도 문제
산업계 즉시 활용 어려움
-3차 융성시기 2012 ~ 현재까지
GPU 세팅 (그래픽카드)
연산속도문제가 해결
세돌 vs 알파고 바둑 대회(2017년)
정부에서도 본격적으로 투자
교육쪽으로 먼저 투자 시작
대학교육 + 국비교육
데이터과학
2012년
CNN 알고리즘 논문 다수 출현
이미지 기본데이터셋
- 기존대비 성능이 좋아야 함
- 개존대비 연산속도가 좋아야 함
→ 각자 딥러닝 관심 생김
→ 공부하는 패턴 : 최운선순위는 가장 최근 나온 알고리즘
분야가 정말 많음
지도학습 : 분류/수치 예측(회귀)/비지도학습
엑셀데이터(정형데이터)
기초 통계가 중요(리포트 형태가 더 중요)
개발의 상대적 중요성 떨어짐(성과 측면)
딥러닝:비정형데이터
텍스트,음성,이미지,영상
주로 쓰이는 알고리즘 탐색 (최신 알고리즘)
계속 업그레이드 되고 있음
이세돌 vs 알파고 바둑 대회 (2017년)
데이터과학
지도 학습 vs 딥러닝
→ 개발자라면 딥러닝 알고리즘을 가져다가 빠르게 개발하는 기술을 습득.
딥러닝 라이브러리
- 텐서플로 : https://www.tensorflow.org/
- 2016년 텐서플로 1 버전 vs 텐서플로 2 버전
- 문법적으로 매우 다름
- 산업용
- 파이토치 : https://pytorch.org/
- 연구용
1 | import tensorflow |
2.8.0
데이터 불러오기
패션 MNIST
- 10종류의 패션 아이템으로 구성된 데이터셋
- 텐서프로를 사용해 이 데이터를 불러온다.
1 | from tensorflow import keras |
데이터 확인
훈련 데이터
- 60,000개 이미지, 이미지 크기는 28x28
- 타깃은 60,000개 원소가 있는 1차원 배열
1 | print(train_input.shape, train_target.shape) |
(60000, 28, 28) (60000,)
- 테스트 세트
- 10,000개의 이미지로 이루어짐
1 | print(test_input.shape, test_target.shape) |
(10000, 28, 28) (10000,)
- 이미지 시각화
1 | import matplotlib.pyplot as plt |

- 타겟 값 리스트
- 패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성된다.
- 같은 숫자가 나온다면 타깃이 같은 두 샘플은 같은 종류의 옷이다.
1 | print([train_target[i] for i in range(10)]) |
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
- 실제 타겟값의 값을 확인
- 각 라벨당 6000개의 이미지 존재 60,000개
- 즉, 각 의류마다 6,000개의 샘플이 들어있다.
1 | import numpy as np |
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
로지스틱 회귀로 패션 아이템 분류하기
- 경사하강법 (기울기)
- 샘플이 60,000개나 되기에 샘플을 하나씩 꺼내서 모델을 훈련하는 게 더 효율적
- 해당 상황에 맞는 것이 강사하강법이다.
- 전제 조건 : 각 컬럼의 데이터셋 동일 (표준화)
- why 255? 각 픽셀의 값 0~255 사이의 정수값을 가진다.
- 255로 나누어 0~1 사이의 값으로 정규화 시킴
- 표준화는 아니지만 양수 값으로 이루어진 이미지를 전처리할 때 사용하는 방벙
1 | train_scaled = train_input / 255.0 |
(60000, 784)
모델 만들기
비정형데이터에 선형모델 또는 비선형모델을 적용시키는 것이 합리적인가?
- 결론은 아니다!
- 다른 대안이 있는냐? 인공신경망!
정형데이터에 인공신경망 및 딥러닝 모델을 적용시키는 것이 합리적인가?
- 결론은 아니다!
SGDClassifier 클래스와 cross_validate 함수로 이 데이터에서 교차 검증으로 성능을 확인한다.
1 | from sklearn.model_selection import cross_validate |
0.8195666666666668
- 로지스틱 회귀 공식을 그림으로 나타내면 인공신경망의 그림과 같다.
- 인동신경망을 만들어 패션 아이템 분류 문제의 성능을 높일 수 있는지 지켜보자.
참고
- 355~356p
- 인공신경망 : http://alexlenail.me/NN-SVG/index.html
- 입력층, 출력층, 뉴런(유닛)에 대해 숙지하자.
인공신경망 모델 적용
- 이미지 분류에는 인공 신경망이 적합하다.
1 | import tensorflow as tf |
- 텐서플로 = 케라스
- 케라스 API를 사용해 패션 아이템을 분류하는 가장 간단한 인공 신경망을 만들어 보자.
- train_test_split()
1 | from sklearn.model_selection import train_test_split |
- test_size=0.2
- 훈련 세트에서 20%를 검증 세트로 덜어 내었다.
- 훈련 세트와 검증 세트의 크기를 알아보자.
1 | print(train_scaled.shape, train_target.shape) |
(48000, 784) (48000,)
1 | print(val_scaled.shape, val_target.shape) |
(12000, 784) (12000,)
60,000개 중에 12,000개가 검증 세트로 분리되었다.
먼저 훈련 세트로 모델을 만든다. 그 다음 검증 세트로 훈련한 모델을 평가해본다.
이미지 하나에 있는 픽셀은 784개. 뉴런은 10개. 이것을 모두 연결.
완전 연결층 = 밀집층 = 밀집하게 연결되어 있는 것
- fully connected layer = dense layer
1 | print(train_target[:10]) |
[7 3 5 8 6 9 3 3 9 9]
- Dense 클래스를 통해 밀집층을 만들어보자
- 활성화 함수
- softmax와 같이 뉴런의 선형 방정직 계산 결과에 적용되는 함수.
1 | # 매개변수의 의미는 차례대로 뉴런개수, 뉴런의 출력에 적용할 함수, 입력의 크기다. |
- 방금 만든 밀집층을 가진 신경망 모델을 만들자.
- Sequential 클래스를 사용한다.
1 | model = keras.Sequential(dense) |
인공 신경망으로 패션 아이템 분류하기
- 훈련하기 전의 설정 단계
1 | model.compile(loss = 'sparse_categorical_crossentropy', metrics = "accuracy") |
- 모델을 훈련한다.
- 반복할 에포크 횟수를 epochs 매개변수로 지정
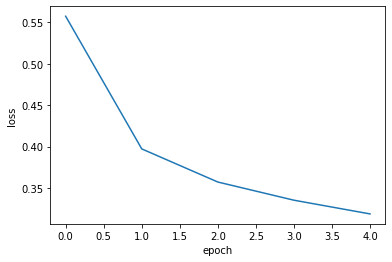
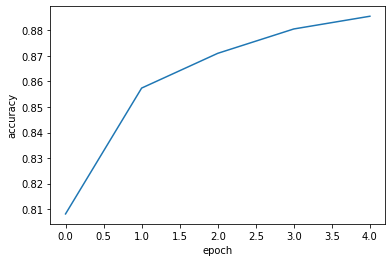
1 | model.fit(train_scaled, train_target, epochs = 5) |
Epoch 1/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4782 - accuracy: 0.8383
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4574 - accuracy: 0.8484
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4450 - accuracy: 0.8525
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4372 - accuracy: 0.8549
Epoch 5/5
1500/1500 [==============================] - 2s 2ms/step - loss: 0.4318 - accuracy: 0.8575
<keras.callbacks.History at 0x7fb1c0b7f450>
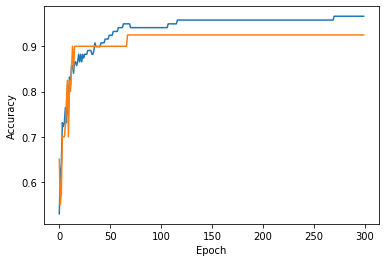
- 갈수록 정확도가 증가함을 알 수 있다.
- 검증 세트(val_scaled, val_target)에서 모델의 성능을 확인한다.
1 | model.evaluate(val_scaled, val_target) |
375/375 [==============================] - 1s 1ms/step - loss: 0.4530 - accuracy: 0.8463
[0.4530307352542877, 0.8463333249092102]
- Reference : 혼자 공부하는 머신러닝 + 딥러닝